姚顺雨腾讯首篇论文:给AI下半场指路量子位
姚顺雨,入职腾讯首席AI科学家后,参与的首个成果来了。
CL-bench,专门用来测试大模型“从上下文中学习”的能力。
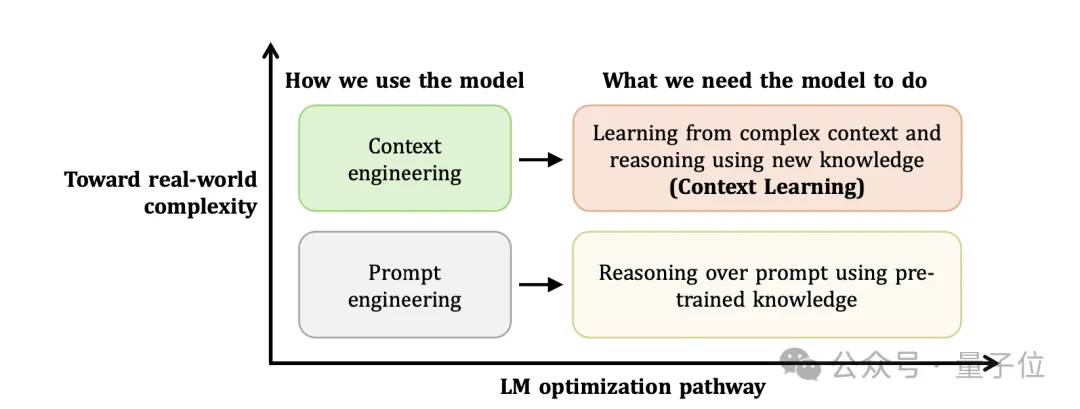
这项研究与姚顺雨一贯的研究思路高度契合,去年8月他在OpenAI期间发表的博文《下半场》曾提出一个被反复引用的判断:
AI正处在“中场休息”阶段,上半场是训练大于评估,下半场将是评估大于训练。
真正重要的不是继续堆模型规模,而是让模型在真实任务、真实系统中经得起检验。
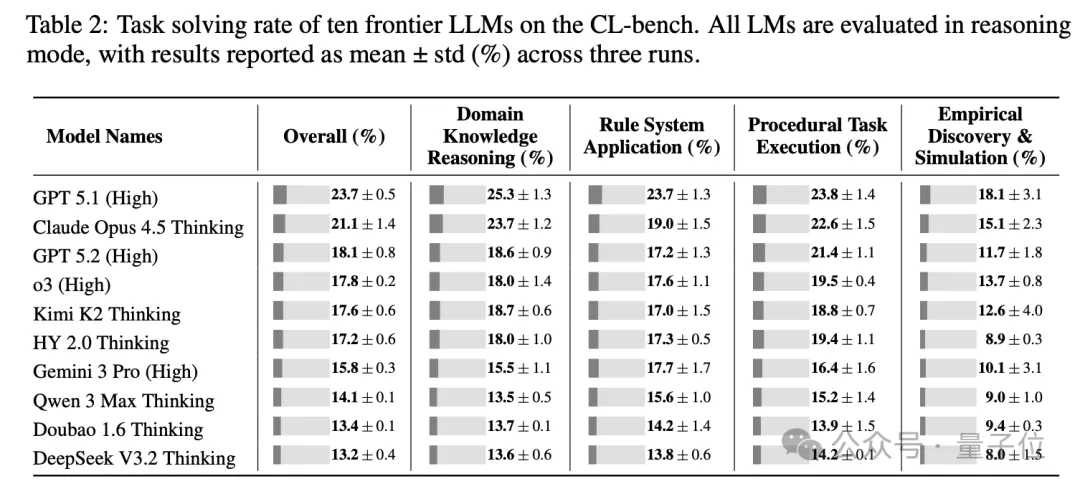
CL-bench的评测结果相当扎心,当前最强的GPT-5.1 (High),任务解决率只有23.7%。
换句话说,即便把解题所需的全部信息都喂给模型,它依然在超过四分之三的任务上栽了跟头。
为什么需要上下文学习
研究团队在博客中开门见山地指出了一个被忽视的问题:今天的前沿模型是顶级的“做题家”,能解奥数、能写代码、能通过人类需要苦读数年才能拿下的专业资格考试。
但这能在考场拿满分的学生,未必能胜任真实世界的工作。
博客中举了三个人类日常生活的例子:
开发者扫过从未见过的工具文档就能立刻调试代码;
玩家拿起新游戏的规则书在实战中边玩边学;
科学家从复杂的实验日志中筛选数据推导出新的结论。
这些场景中,人类并不只依赖多年前学到的死知识,而是在实时地从眼前的上下文中学习。
然而今天的语言模型并非如此。它们主要依赖“参数化知识”,即在预训练阶段被压缩进模型权重里的静态记忆,在推理时更多是在调用这些封存的内部知识,而不是主动从当前输入的新信息中汲取营养。
团队用一句话概括了这个矛盾:我们造出了依赖“过去”的参数推理者,但世界需要的是能吸收“当下”环境上下文的学习者。
CL-bench:500个复杂上下文,一个简单但苛刻的要求
为了量化这个差距,团队构建了CL-bench。
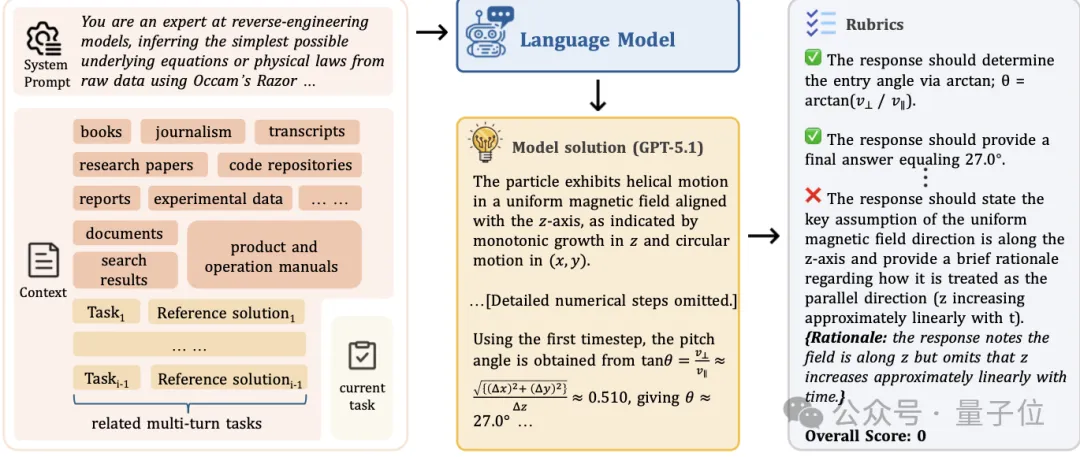
这个基准包含由资深领域专家精心制作的500个复杂上下文、1899个任务和31607个验证标准。设计原则只有一条:解决每个任务要求模型必须从上下文中学习到预训练中不存在的新知识,并正确应用。
模型需要学习的知识非常广泛,包括新的领域知识、不熟悉的规则系统、复杂的产品工作流,甚至是必须从实验数据中推导归纳出的定律或结论。
所有这些知识要么是由领域专家完全新构建的,要么是取自那些不太可能出现在当前前沿模型训练数据中的小众、长尾来源。
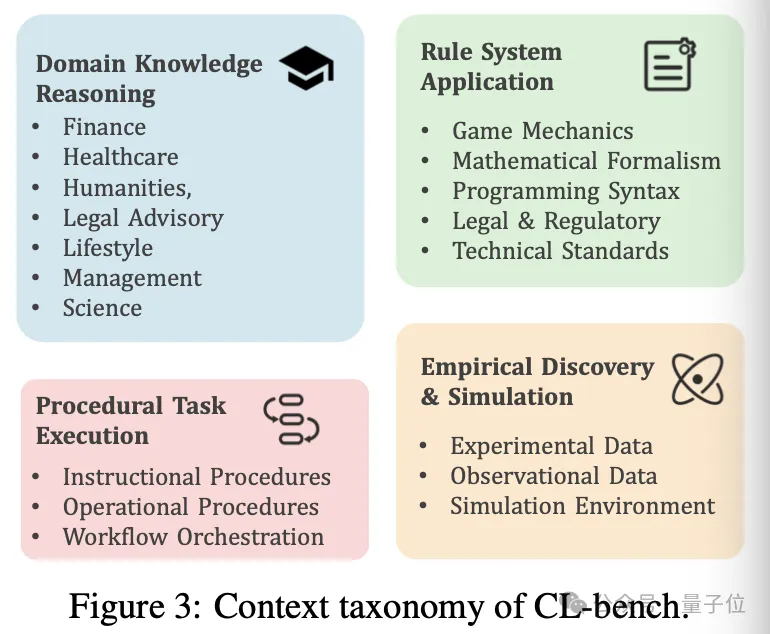
具体来说,CL-bench涵盖了四种现实世界的上下文学习场景:领域知识推理,比如虚构的法律体系或创新的金融工具;规则系统应用,比如新的游戏机制或编程语法;程序性任务执行,比如工作流和产品手册;以及最具挑战性的经验发现与模拟,要求模型从数据中归纳出潜在规律。
团队展示了几个任务案例:在一部长达2.3万字、刚刚生效的新法律下判一起真实纠纷;基于一门新设计的教育编程语言规范实现一个带有时间条件终止的周期性程序;在一套从未见过的编程框架中执行代码;在给定技术规格和长期环境政策情景的条件下模拟关键技术金属的可持续全球供应。
为了确保测试结果反映的是真正的上下文学习能力而非数据泄露或记忆,团队采用了无污染设计:专家创作完全虚构的内容,或修改现实世界的内容创建变体,或整合在预训练数据集中代表性极低的小众内容。
论文特别提到,在不提供任何上下文的情况下,GPT-5.1 (High)仅能解决不到1%的任务,有力证明了模型若不从上下文中学习几乎完全无法解决这些任务。
平均而言,领域专家花费约20小时标注每个上下文,以确保任务构建的质量和深度。
十个前沿模型集体翻车
即使提供上下文,当前模型的表现也好不到哪去。
团队在CL-bench上评估了十个最先进的语言模型,结果揭示了当前模型几乎不能从复杂上下文中学习来解决真实场景的问题。
平均而言,模型仅解决了17.2%的任务,即便是表现最好的GPT-5.1 (High)也仅达到23.7%。