从非欧几何视角解释和改造Transformer机器学习与数学
在人工智能的浩瀚宇宙中,Transformer 架构无疑是当今最耀眼的恒星。从 ChatGPT 的惊艳对话到 Midjourney 的梦幻绘图,它都是这一切奇迹背后的核心引擎。
然而,对于大多数非巨头的研究者来说,现实往往是骨感的:手头没有成堆的 H100,也没有那烧得起整座发电厂的预算,也想玩转 Transformer 怎么办?
硬(硬件)的不行,要不咱就来点软(数学)的?
是的,既然拼不过算力的暴力美学,那我们就试试数学的精巧逻辑。这就好比武林剑客,力量上拼不过人家,就得在剑术的精妙上下点功夫。
不过呢,稍微复杂一点的数学搬上去未必立刻这就 SOTA,但至少,它能从更抽象的第一性原理层面,为我们提供一种全新的解题思路。
在改进 Transformer 的道路上,通常有两派人马:一派在做减法,比如搞线性注意力(Linear Attention),试图让模型跑得更快、吞吐量更大;而另一派偏偏反其道而行之,他们在做加法。
咱就属于后者,主张把模型整复杂,先弄一点点黎曼几何和李群李代数等知识试试水,试图进一步压榨架构的潜力。
虽然这听起来似乎有点像是为了数学而数学,但其背后的野心在于:与其用海量数据去暴力拟合,不如给 AI 装上一个更加符合几何直觉的大脑。
至于性能优化?交给工程师嘛,咱只负责优雅。
好了,让我们系好安全带,看看咱是如何用微分几何的视角,把 Transformer 扔进一个弯曲的世界里魔改的。
1. 注意力流形
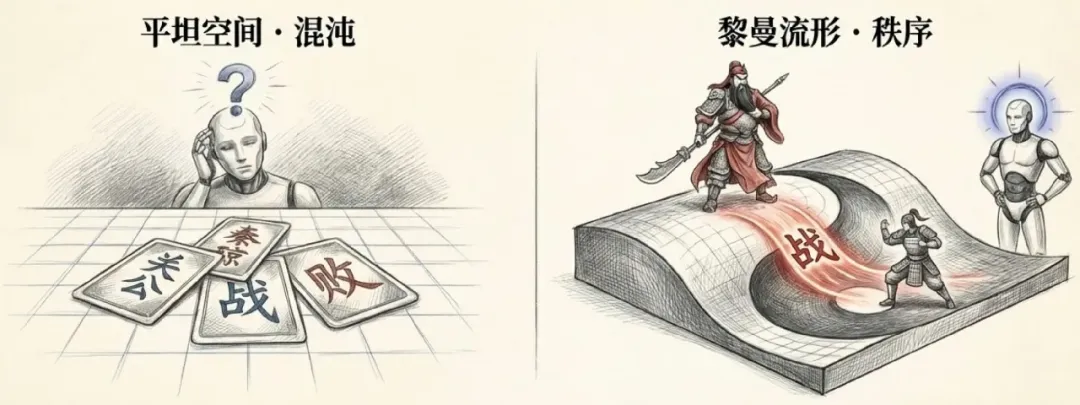
让我们回到 Transformer。它的强大毋庸置疑,然而,你是否想过,这个强大的引擎里头其实是一个路痴?这就不得不说说它的一个出厂设定缺陷:置换不变性(Permutation Invariance)。
痛苦的根源:当 AI 分不清谁是赢家
对于标准的自注意力机制(Self-Attention)来说,它看一句话就像是看一堆散落在地上的麻将牌。它只知道有什么字,却完全不知道字在哪。如果我们将这个概念放在文言文的语境下,这种缺陷足以引发一场历史级的混乱。
请看这个经典的跨朝代乱斗案例:
【原句:武圣之威】
关公 战 败 秦琼(注:关羽跨越时空,把唐朝的秦琼打趴下了。)
【乱序:瓦岗逆袭】
秦琼 战 败 关公(注:秦叔宝逆天改命,武圣颜面扫地。)
在人类眼里,这是两个截然相反的结局,胜负关系完全取决于关公和秦琼谁站在战败的前面。
然而,对于一个没有位置编码的 Transformer 来说,它收到的输入仅仅是一个词袋(Bag of Words):
关公,秦琼,战,败
在它看来,左边的武圣发威和右边的瓦岗逆袭生成的特征向量是一猫一样的。这就是所谓的薛定谔的战役:只要不观测位置,你永远不知道到底是谁赢了。
为了解决这个问题,传统的做法是给每个词脸上贴个编号(1, 2, 3...),这就是位置编码(Positional Encoding)。但这就像是在一副写意水墨画上,生硬地用圆珠笔标上了 坐标。虽然让 AI 分清了胜负,但这种做法总感觉不够优雅和本质,也不符合道法自然的几何直觉。
那么有没有优雅一些的做法呢?
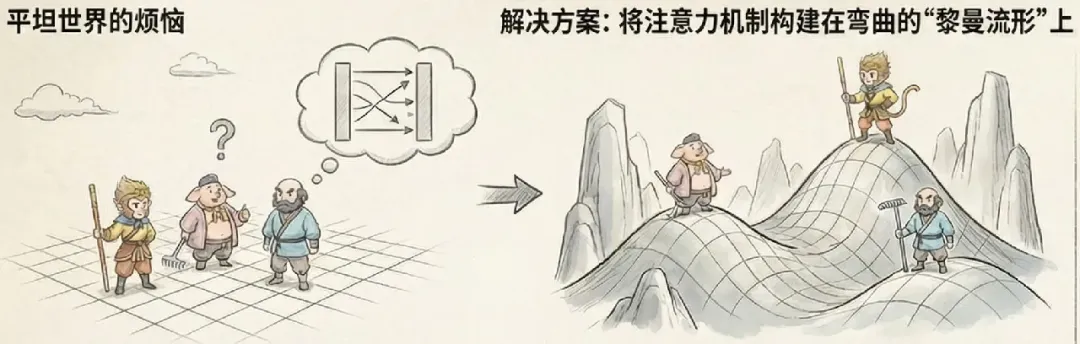
有一天,俺在刷锅的时候突然想到:与其强行标号,不如让这战场本身就是弯曲的(非欧的)如何?
黎曼流形:让注意力在曲面上流淌
我们认为,Token(单词或图像块)不应该待在平坦的欧几里得空间里,而应该住在一个黎曼流形上。这是一个弯曲的空间,就像球面或者起伏的山峦。
在这个框架下,不仅知道 Token 是什么(内容),还能通过几何结构感知它在哪里。
为了让形象更具辨识度,咱这里改成西游记中的三兄弟。
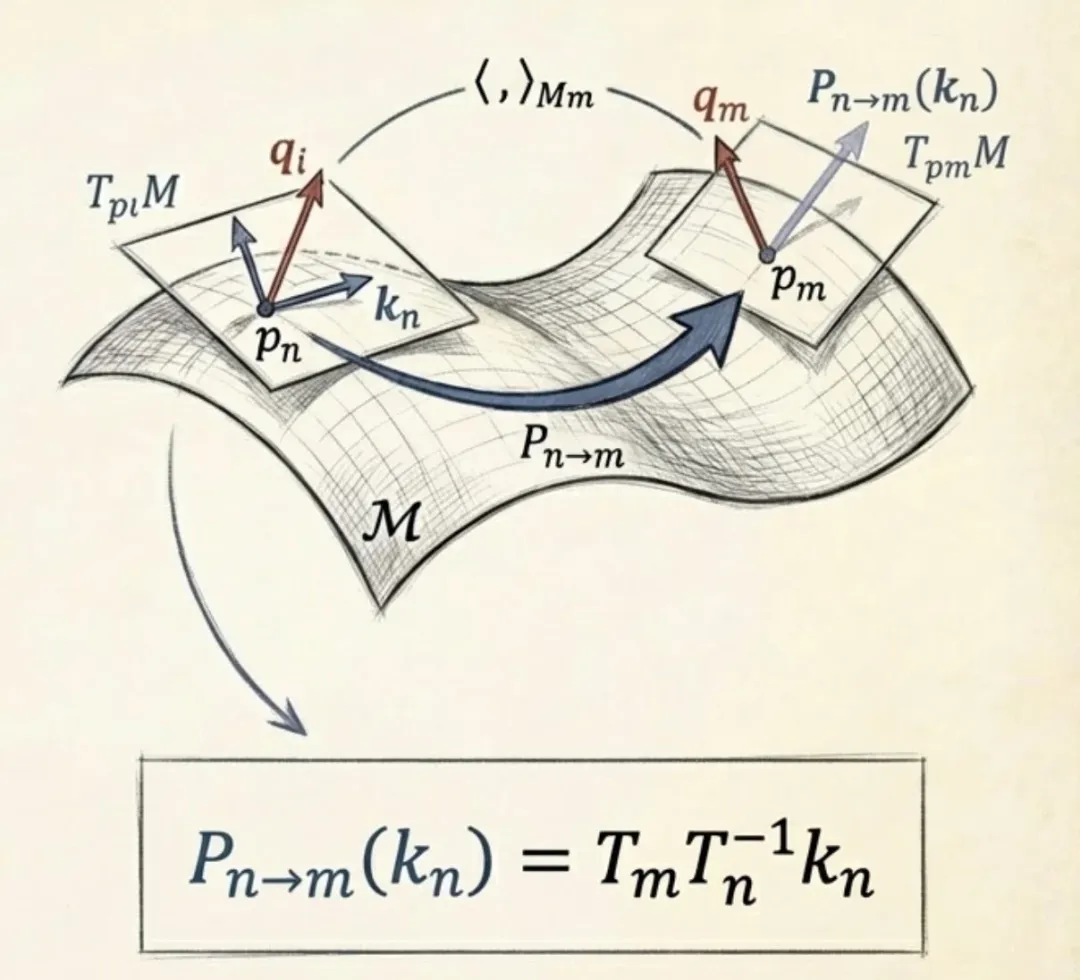
如果在平地上,你可以随意平移一个箭头(向量),它的方向和大小不变。但在球面上,你带着一个指向北极的箭头走到赤道,再沿着赤道走,箭头指的方向相对于当地经纬线就会发生变化。因此,我们需要想办法来比较不同地点的箭头。
我们将 Transformer 的自注意力机制重构为注意力流形(Attention Manifold)上的交互。在此框架下,Token 是流形上的点,特征嵌入是切空间中的向量。流形的几何由两部分定义:黎曼度量(调节局部交互与语义显著性)和平行移动算子(保证不同位置向量比较的一致性)。这为设计具有强归纳偏置的注意力机制提供了基于第一性原理的视角。
我们的核心理念发生了根本转变:从外在几何转向内蕴几何。重要的不是 Token 在环境空间中的绝对坐标,而是它们之间如何通过变换建立联系。我们不再试图参数化绝对位置,而是专注于定义一种协议,使切向量(特征嵌入)能在离散点的切空间之间进行转换,即平行移动。
尽管平行移动提供了切空间间的线性同构,但在离散设置中,我们缺乏显式的坐标、路径及联络定义。因此,我们摒弃显式位置编码,转而令模型直接学习切空间之间的线性映射。
这相当于隐式地构建了沿 Token 序列的平行移动,从而在无需具体位置信息的情况下,实现了几何上合法的内积运算。也就是说,我们无心构建整个连续的流形,而是转向学习一个离散联络。