俩AI「互喷」,治好科研软件95%老毛病?新智元
过去几十年,科学计算领域诞生了无数开源工具,却鲜有能「开箱即用」。深势科技Deploy-Master以执行为中心,用自动化工作流一次性部署验证超5万个工具,为Agentic Science铺平道路。
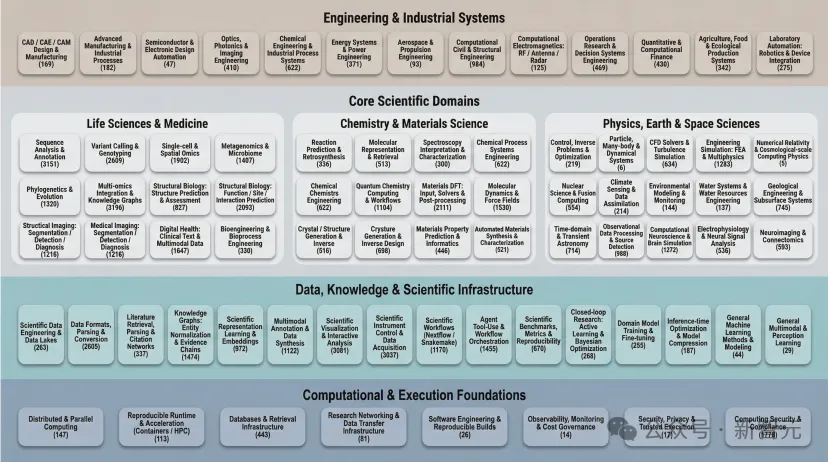
过去几十年里,科学计算领域积累了数量空前的开源软件工具。
从生物信息学、化学模拟,到材料计算、物理仿真与工程设计,几乎每一个学科方向,都形成了自己的工具生态。在GitHub等平台上,成千上万个代码仓库声称可以被用于科研实践。
但一个长期存在、却始终没有被系统性解决的事实是:绝大多数科学软件,停留在「被发布过」,而不是「可以直接运行」的状态。
在真实科研实践中,我们往往需要花费数天甚至数周时间,反复解决编译失败、依赖冲突、系统不兼容等问题,才能在本地「勉强跑通」一个工具。
这样的运行环境高度依赖个人经验,往往是临时的、不可移植的,也很难被他人复现或复用。每个研究者、每个实验室,都在手工维护自己的运行环境,而不是在一个共享、可复现的执行基础设施之上开展工作。
这种模式带来的问题,并不只是效率低下。更关键的是,它在结构上限制了科学软件的三件事情:可复现性、大规模评估,以及系统性集成。
即便容器化、云计算和HPC平台已经显著降低了算力门槛,这一「部署瓶颈」依然真实存在,并且长期制约着科学软件的可用性。
随着AI for Science(AI4S)的兴起,这一问题被进一步放大。
在新的科研范式中,AI系统不再只是输出预测结果,而是需要与真实的科学工具发生紧密交互:
1. 调用求解器;
2. 执行模拟程序;
3. 运行分析管线;
4. 处理真实数据。
在这样的背景下,一个工具是否「真的能跑」,不再是工程细节,而是第一性问题。
这一问题在Agentic Science场景中表现得更加尖锐。
如果工具依赖隐含环境、执行高度脆弱,那么智能体的规划将无法真正落地,执行失败也无法被结构化分析,更不可能转化为可学习的执行轨迹。
从这个角度看,工具是否部署就绪,已经成为制约AI4S与Agentic Science规模化发展的结构性瓶颈。
基于这些观察,深势科技逐渐形成了一个判断:科学软件的问题,并不在于工具不够多,而在于缺乏一个能够将工具系统性转化为可执行事实的共享基础设施。
Deploy-Master,正是在这一背景下被提出的。
在真实世界中,部署并不是一个孤立步骤,而是一条连续链路:
工具能否被发现、是否被正确理解、能否构建环境,以及是否真的可以被执行。
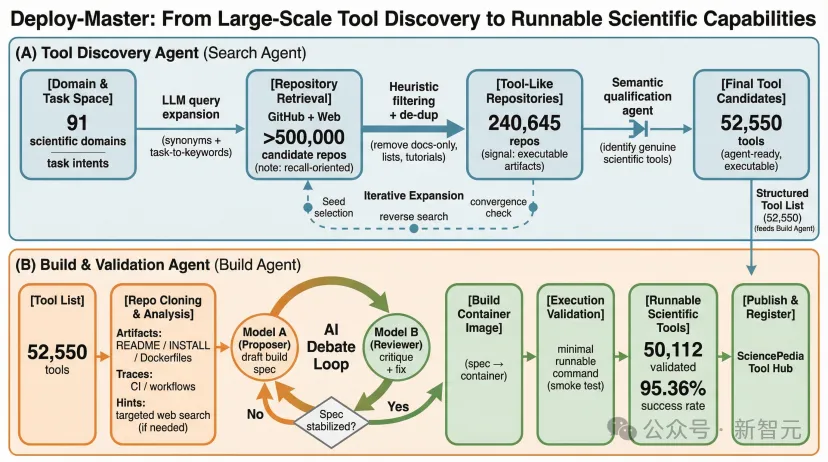
Deploy-Master正是围绕这条链路,被设计为一个以执行为中心的一站式自动化工作流。
Search Agent
百万级仓库搜索
在大规模场景下,部署的第一个难题并不在构建,而在发现。如果候选工具集合本身存在系统性偏差,后续所有自动化都会被放大为偏差。
为此,他们从91个科学与工程领域出发,构建了一个覆盖AI4S实际应用场景的学科空间,并使用语言模型扩展搜索关键词,在GitHub与公共网络中进行大规模检索。
初始召回得到的仓库,会作为「锚点」,通过依赖关系、引用关系、共享贡献者和文档链接等信号进行迭代扩展,从而避免仅依赖关键词搜索带来的盲区。
随后,他们通过结构启发式规则剔除明显不可执行的仓库,并由agent进行语义判断,确认其是否构成一个可执行科学工具。
通过这一多阶段漏斗流程,他们将最初约50万个仓库,收敛为52,550个进入自动部署流程的科学工具候选。
这一步的意义,不仅在于筛选工具,更在于第一次以结构化方式刻画了真实科学工具世界的规模与边界。
Build Agent
在构建阶段,大家面对的并不是一个「有明确说明书」的世界。
大量科学软件仓库的构建信息是零散的、不完整的,甚至相互矛盾的。
README文件可能早已过期,已有Dockerfile也未必反映当前代码状态,而关键依赖往往只存在于作者本地环境中。
Build Agent会系统性地遍历仓库中的构建线索,并在必要时进行补充信息检索,生成初始构建方案。
早期实验表明,仅依赖单一模型生成构建规格,成功率只有50%–60%,失败主要源于构建信息中大量隐含、未被显式表达的假设。
为此,Deploy-Master引入了双模型评审与辩论(debate)机制:
一个模型提出构建规格,另一个模型独立审查并主动寻找潜在不一致、缺失依赖或环境假设,提出修正建议。
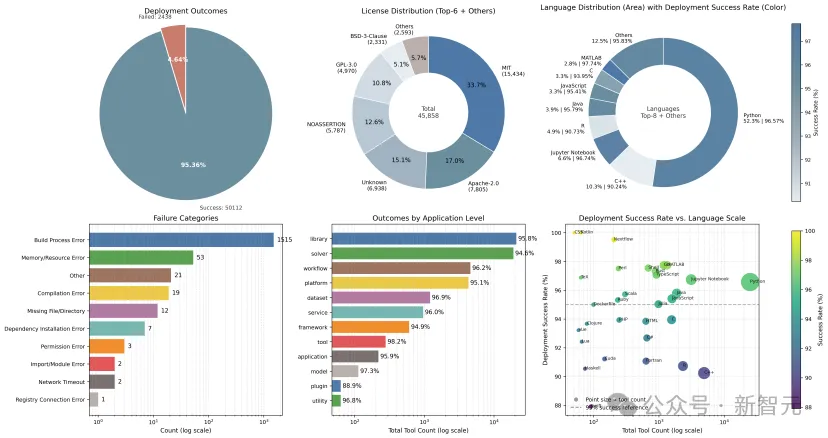
两者通过多轮交互,不断修正方案,直到形成稳定、可执行的构建规格。这一机制将整体成功率提升到了95%以上。
每一个工具最终都会通过一个最小可执行命令进行验证。
只有通过执行验证的工具,才会被视为成功部署,并被进一步结构化、注册和发布到玻尔与SciencePedia上,使其可以被直接使用,或被其他agent(例如SciMaster)调用。
从构建时间的分布来看,大规模部署并不是一个「均匀」的过程。
尽管大多数工具可以在7分钟左右完成构建,但整体分布呈现出明显的长尾特征。
一部分工具仅包含轻量级脚本或解释型代码,构建过程相对简单;
而另一部分工具则涉及复杂的编译流程、深层依赖以及系统级库配置,其构建时间显著更长。