反向传播算法——开启深度学习的基石编码大脑实验室
大家好,我是数行天下。在人工智能的璀璨星河中,深度学习无疑是最耀眼的那颗恒星,它让机器具备了从海量数据中自主学习、识别规律甚至创造内容的能力。而支撑这一技术大厦拔地而起的核心基石,正是反向传播(Backpropagation)算法。它的诞生,彻底解决了神经网络训练中的“归因困境”,让深度模型从理论构想变为现实,直接推动了人工智能从低谷走向爆发式增长。
一、深度学习的“灵魂拷问”:谁该为误差负责?
训练神经网络的过程,本质上是一场“试错与修正”的迭代游戏。我们向模型输入数据,期待它输出精准的结果——比如识别一张图片中的猫、翻译一段复杂的文本,或是预测金融市场的波动。但现实往往是残酷的,模型的初次输出几乎必然与预期存在偏差,也就是“误差”。
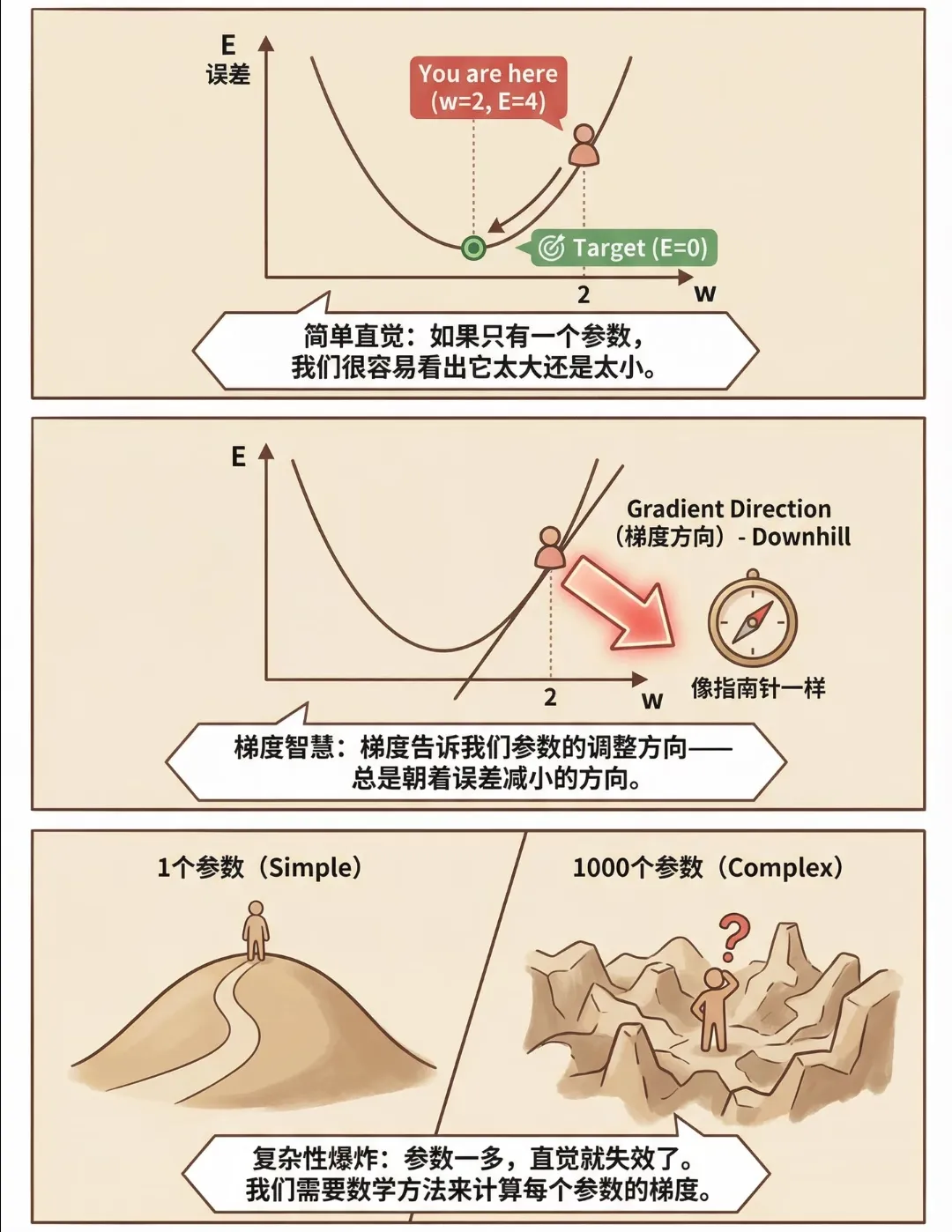
此时,一个棘手的问题摆在面前:神经网络中少则几千、多则万亿的参数里,究竟哪个或哪些参数该为这个错误负责?它们的责任又有多大? 这就像一支交响乐团演奏出错时,我们很难立刻判断是小提琴手走音、钢琴家节奏不稳,还是指挥家的指令出现了偏差。
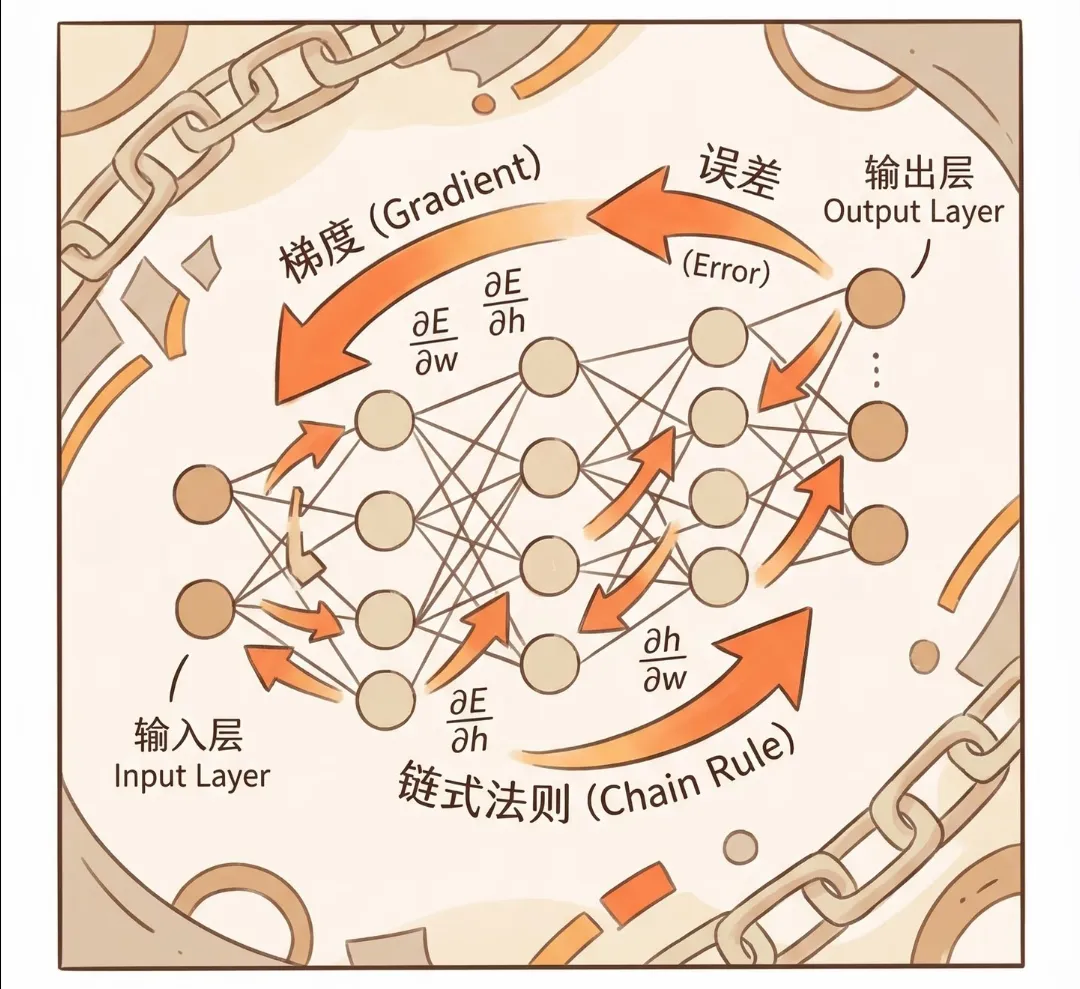
在反向传播算法出现之前,这个问题几乎是无解的。早期的神经网络训练依赖数值微分等方法,不仅计算效率极低,而且无法精准定位参数的责任分配,导致模型只能停留在浅层结构,根本无法处理复杂的任务。直到反向传播算法的提出,才为这个“灵魂拷问”提供了标准答案——它让误差信号从输出层反向流动,像侦探追踪线索一样,精确计算出每个参数对最终误差的“贡献度”,也就是梯度(Gradient)。
二、数学根基:链式法则驱动的“责任追溯”
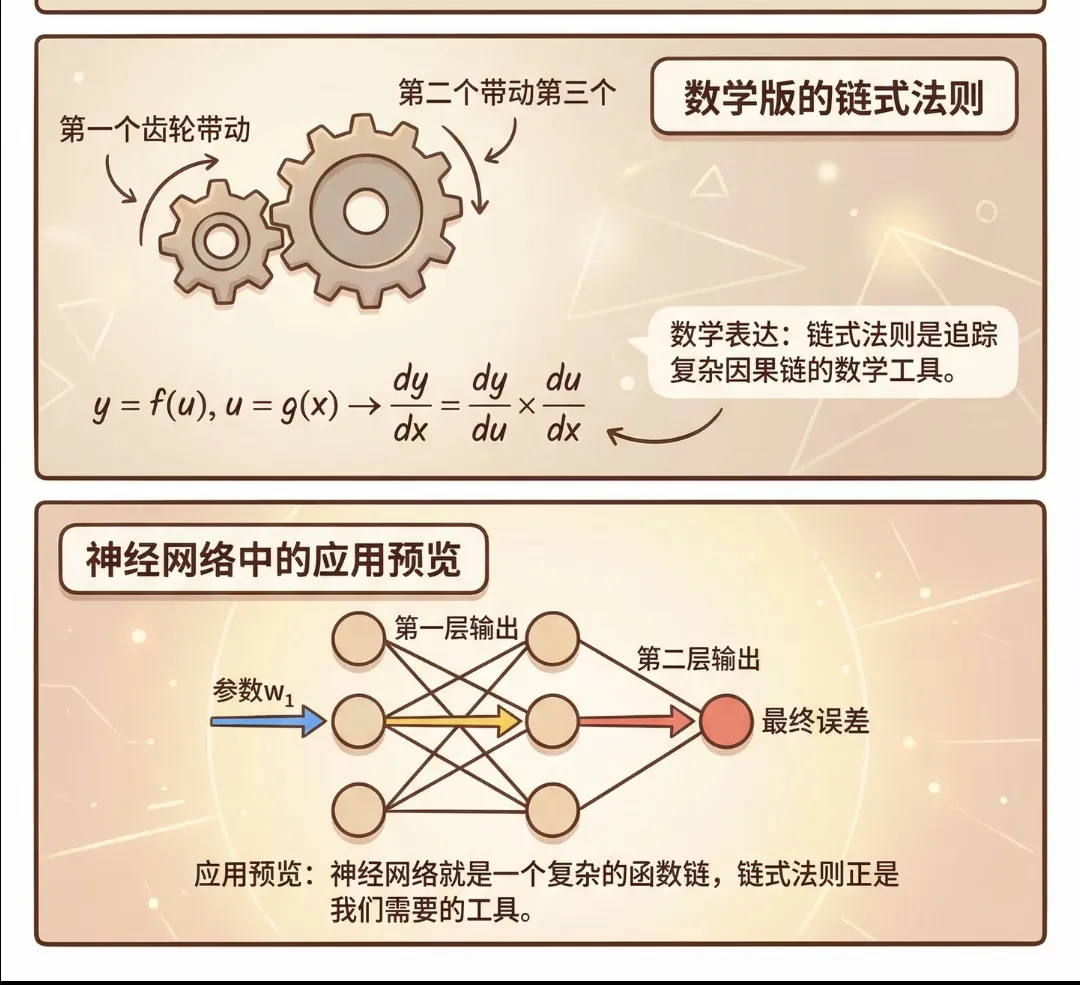
反向传播算法的核心数学支撑,是微积分中的链式法则。这一法则看似简单,却为复杂函数的求导提供了革命性的思路:一个复合函数的导数,可以分解为其组成部分的局部导数的乘积。
这种递推式的计算逻辑,让梯度求解变得高效而有序。我们无需构建全局的复杂求导公式,只需掌握每层的局部计算规则——比如矩阵乘法的导数、加法运算的导数,以及ReLU、Sigmoid等激活函数的导数,就能从输出层开始,逐层反向推导,最终求出所有参数的梯度。
这就像工厂的质量追溯体系:当最终产品出现缺陷时,无需拆解整个生产流程,只需从成品出发,沿着生产线反向排查,每个工序只需确认自己环节的问题,就能快速定位到故障源头。反向传播算法正是这样一套为神经网络量身定制的“质量追溯系统”,让每个参数的“责任”都变得清晰可量化。
三、计算图:反向传播的“运作框架”
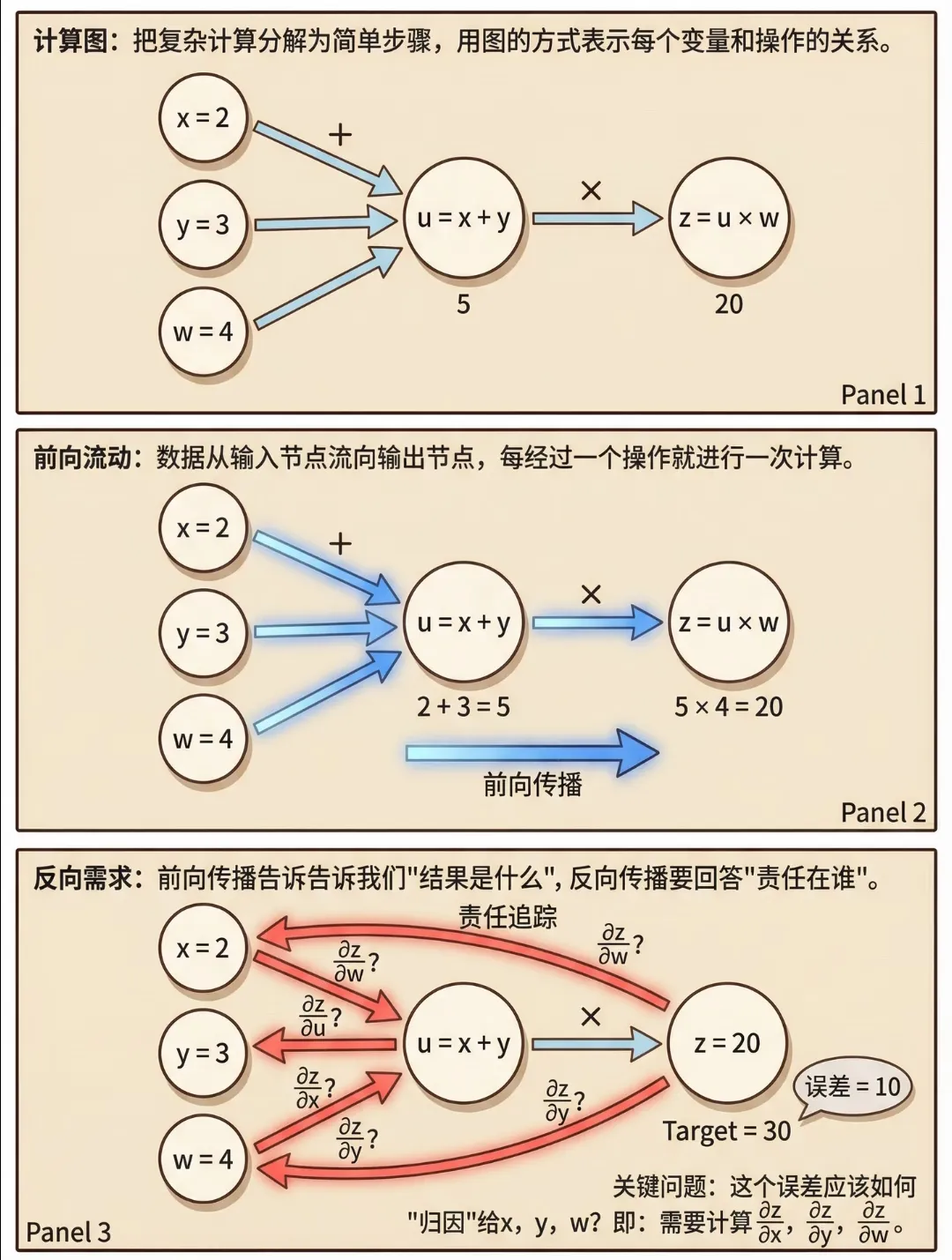
要实现高效的梯度反向传递,离不开计算图(Computational Graph) 的构建。这是一种将复杂计算过程拆解为节点和边的可视化表示,前向传播与反向传播都围绕它展开,形成了一套完整的“计算-回溯”闭环。
(一)前向传播:记录每一步的“因果痕迹”
前向传播是模型处理输入、生成输出的过程,而在反向传播的逻辑中,它还有一个至关重要的作用——记录中间结果。在计算图中,每个节点代表一个运算(如加法、乘法、激活函数)或一个变量(如输入数据、参数、中间输出),边则代表了变量之间的依赖关系。
当数据从输入层流入,经过一层层的线性变换和非线性激活时,计算图会同步记录下每一步的中间输出值。这些看似冗余的记录,实则是反向传播的“关键线索”——因为在计算局部梯度时,我们需要用到这些中间结果来计算变量间的敏感度。例如,在计算Sigmoid激活函数的导数时,需要用到该函数的输出值;在计算矩阵乘法的梯度时,需要用到输入矩阵的转置。