MIT发现让AI变聪明的秘密:和人类一模一样新智元
你有没有发现,你让AI读一篇长文章,结果它读着读着就忘了前面的内容? 你让它处理一份超长的文档,结果它给出来的答案,牛头不对马嘴? 这个现象,学术界有个专门的名词,叫做上下文腐化。 这也是目前AI的通病:大模型的记忆力太差了,文章越长,模型越傻!
2025年最后一天,麻省理工学院(MIT)丢了一篇重磅论文,就是要解决这个问题的。
这篇论文叫《Recursive Language Models》,也就是递归语言模型。
看起来很学术,但说人话就一句:让AI再做一遍,效果直接起飞。
先剧透两个核心数据:
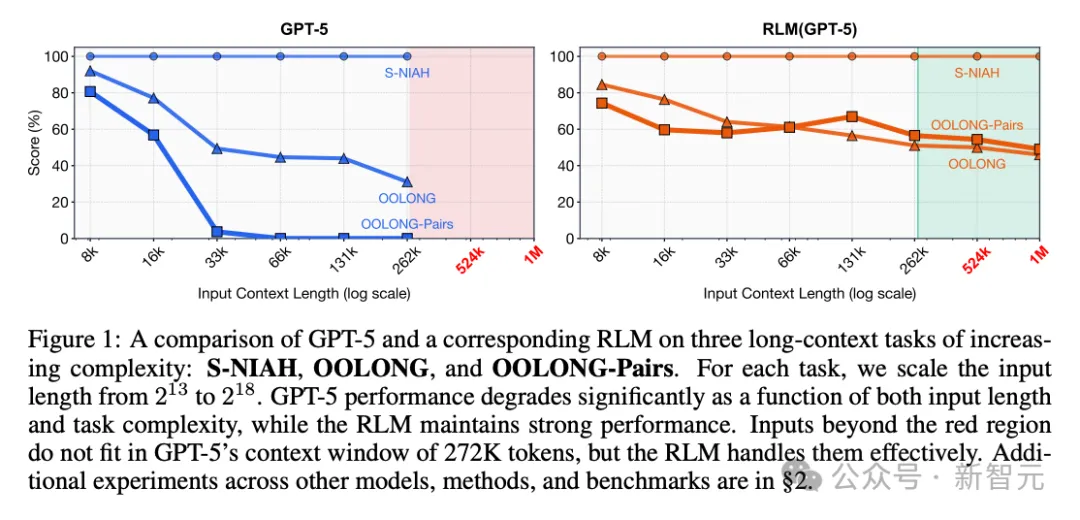
在复杂推理任务上,仅仅让模型多过2-4遍,正确率就能提升10%-25%在超长文档处理上,RLM(递归语言模型)在1000万+token的规模下,依然保持稳定表现,而传统模型直接崩盘!这啥概念?
以前我们觉得,AI不够聪明,那就给它堆参数、加显卡、买更多GPU。
MIT这篇论文直接掀桌子:别堆参数了,让它返工重写一遍,效果可能更好。(真就是人类监工了)
原来解决问题的方法就是这么简单!
并且X上很多大佬纷纷点赞~
从一个让人崩溃的问题说起
你有没有这种经历:
让ChatGPT帮你写一篇文章,它洋洋洒洒写了三千字,你一看——卧槽,离题万里。
或者让它帮你写代码,它写完了,一运行——全是bug。
但神奇的是,你让它再检查一遍、重新想想,有时候它就突然能改对了。
MIT的研究人员发现,这不是玄学,这是有规律的。
大多数AI犯的错,不是因为它不懂,而是因为它初稿写太快了。
就像你写论文,第一稿总是稀烂,但改个三四遍,就像换了个人写的。
AI也是一样。
问题是:现在的大模型基本都是一遍过的模式,你输入问题,它输出答案,完事。
它自己不会主动返工、不会自我检查、不会反复推敲。
或者换一个思路来理解大模型原先的思路:
假设你是一个刚进公司的实习生,领导给你发了一份500页的资料,让你整理出一份报告。
你会怎么做?
正常人的做法是:先翻一翻,找到重点章节,然后一章一章地读,读完一章做个总结,最后把所有总结串起来。
但大模型不是这么干的。
大模型的做法是:直接把500页资料从头到尾一口气读完,然后尝试凭记忆回答问题。
这能记住才有鬼了。
这就是大模型面临的困境。
它不是不聪明,它是记不住。
MIT这篇论文干的事儿,就是给AI装上了一个返工的能力。