Ilya警告、LeCun冷嘲、奥特曼沉默:Scaling Law新智元
过去10年,AI大模型的技术本质,是把电力能源通过计算过程转化为可复用的智能。2026年,我们需要让AI模型在单位时间内「吃下」更多能源,并真正将其转化为智能。
2026年的AI圈子,最怕什么?
从2022年底ChatGPT横空出世以来,AI圈子里一直潜藏着一个「幽灵」。
从ChatGPT到惊艳世界的DeepSeek,再到2025年底的Gemini 3、GPT-5.2等,所有这些顶级模型背后都是这个幽灵。
他就是Scaling Law,但是令所有人焦虑的是:这个幽灵是否将要,还是已经「撞墙」了?!
Scaling Law是否已经失效?
大佬们的看法出现了前所未有的分歧。
Ilya Sutskever公开表示,单纯堆砌预训练算力的时代正在进入平台期,智能的增长需要转向新的「研究时代」。
Yann LeCun则一如既往地毒舌,认为当前的大语言模型无论怎么Scaling都无法触达真正的AGI。
即便是Sam Altman,也在公开场合含蓄地承认过,仅仅靠更多的GPU已经无法换回同比例的智能跃迁。
当全行业都在为「数据枯竭」和「算力报酬递减」头疼时,大家都在问:算力还在涨,为什么智能的跃迁似乎变慢了?
最近在刷知乎时,读到了新加坡国立大学校长青年教授、潞晨科技创始人尤洋(Yang You)的一篇深度长文:《智能增长的瓶颈》。(文末附有原文)
这篇文章的角度非常独到,尤洋站在基础设施与计算范式的底层,探讨了一个更本质和底层的问题:
算力是如何被转化为智能的,以及这种转化机制是否正在失效。
尤洋教授在文中给出了一个引人深思的观点:
过去10年,AI大模型的技术本质,是把电力能源通过计算过程转化为可复用的智能。
文章系统性地梳理了过去十年大模型成功背后的「隐含假设」,并指出这些假设正在接近边界。
一、智能从哪里来?
尤洋对「智能」的定义相当通俗易懂,也就是模型的预测与创作能力。
在此基础上,他进一步提出:
「过去10年,AI大模型的技术本质,是把电力能源通过计算过程转化为可复用的智能。」
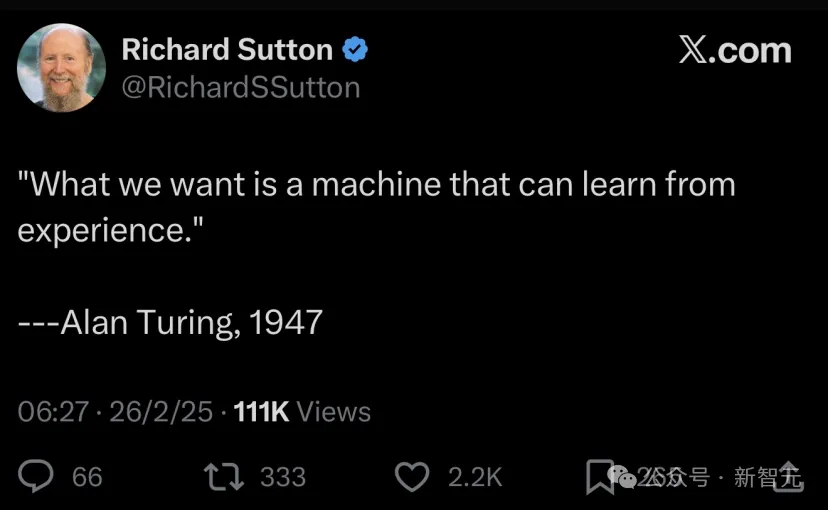
这与强化学习教父Richard S. Sutton分享的观点类似。
在尤洋的叙述中,有三个关键共识被明确强调:
预训练是智能的主要来源
微调、强化学习等阶段贡献有限,根本原因并非算法无效,而是能源(算力)投入规模不在一个数量级。
Next-Token Prediction是一个极其成功的Loss设计
它最大化减少了人为干预,给AI大模型提供了近乎无限的训练数据。
Transformer的胜出,是因为Transformer也是一台并行计算机。
Transformer并非「更像人脑」,而是更像GPU——高度并行、计算密集、通信可控。
正是这三点共同作用,使得从GPT-1、BERT、GPT-2、GPT-3,到ChatGPT与Gemini,大模型得以在十余年间持续放大算力投入,并将其稳定转化为可感知的智能提升。
尤洋也因此指出了真正的瓶颈所在。
二、真正的「瓶颈」在哪里?
在《智能增长的瓶颈》中,尤洋重新界定了「瓶颈」的涵义,并明确区分了两类经常被混淆的进展:
用更少参数、更低算力,达到相同效果(如剪枝、蒸馏、低精度、Mamba等)。这类进展对于工程落地和规模化部署至关重要,但并不直接决定智能的上限。
智能上限提升
在相同的浮点计算总量约束下,训练出能力更强、泛化性更好的模型。这才是决定智能是否能够持续跃迁的关键指标。
在尤洋看来,当前遇到的并不是「算力不够」,而是:
「我们现在的范式无法充分利用持续增长的算力。」
换句话说,问题不在于GPU增长放缓,而在于模型、Loss、优化算法对算力的「消化能力」正在下降。
我们需要让AI模型在单位时间内「吃下」更多能源,并真正将其转化为智能。这么来看:
大模型智能可能还有很大的发展空间,预训练才刚刚开始。