DeepMind发现了最先进的强化学习算法人工智能大讲堂
12/13/2025
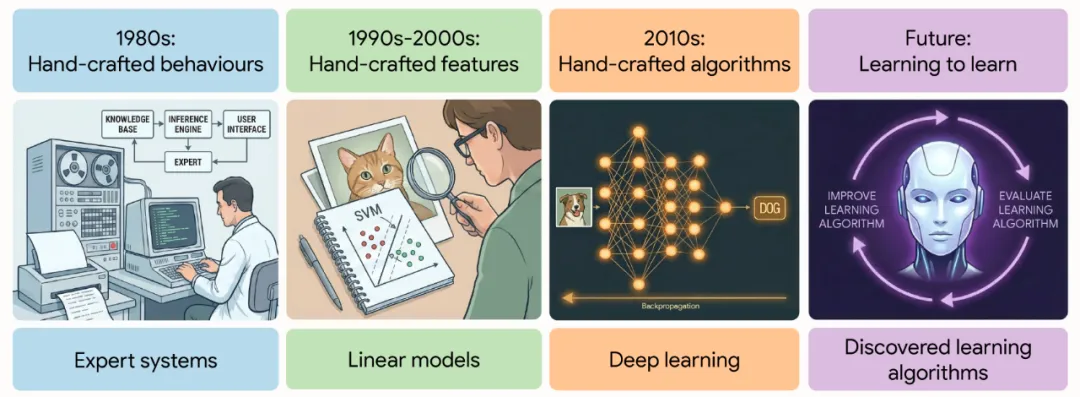
在人工智能领域,强化学习(RL)算法的设计长期依赖人类专家的知识积累与直觉判断。从AlphaGo背后的蒙特卡洛树搜索,到掌控复杂物理系统的深度强化学习框架,每一次算法突破都离不开研究者们耗时数年的反复迭代与调试。
近日谷歌DeepMind宣称发现了最先进的强化学习算法,该算法拥有独特的预测语义与自适应机制,在 Atari 等多类经典基准任务上性能超越 MuZero 等人类设计算法,且具备优异的跨领域泛化能力。目前该研究成果已发表在《Nature》期刊。
强化学习的核心是让智能体通过与环境的交互,不断调整行为策略以最大化累积奖励。几十年来,研究者们手动设计了一系列经典算法:从基于时序差分的TD学习,到兼顾探索与利用的Q学习,再到如今广泛应用的近端策略优化(PPO)和分布式强化学习(Distributional RL)。这些算法在围棋、星际争霸等复杂任务中取得了瞩目成就,但人工设计的局限性也日益凸显。