开源追上闭源了,差距只剩3到6个月AI寒武纪
开源AI正在以肉眼可见的速度逼近闭源天花板。OpenRouter梳理出2026年6月最值得押注的四个开源模型:DeepSeek V4 Flash以GPT-5.5百分之一的成本跑出同级智能体表现;GLM 5.2代码规划能力登顶开源榜首;MiniMax M3独揽多模态赛道;英伟达Nemotron则打出本土企业级王牌。开源与闭源之间,那层窗户纸已经薄如蝉翼。
OpenRouter梳理了截至2026年6月最值得关注的4个开源模型
在过去长达18个月的时间里,开源与闭源的差距稳定保持在3到6个月之间。至少就目前来看,闭源大厂完全没有甩开开源阵营的迹象。
随着企业AI用量激增,控制成本成了各大团队的核心诉求,这也让开源模型迎来了真正的高光时刻。
把业务从闭源模型迁移到开源模型,能省下一笔巨款。闭源模型的前沿能力当然会继续进化,但只要你对智力水平的需求是固定的,使用成本就会一直往下降。
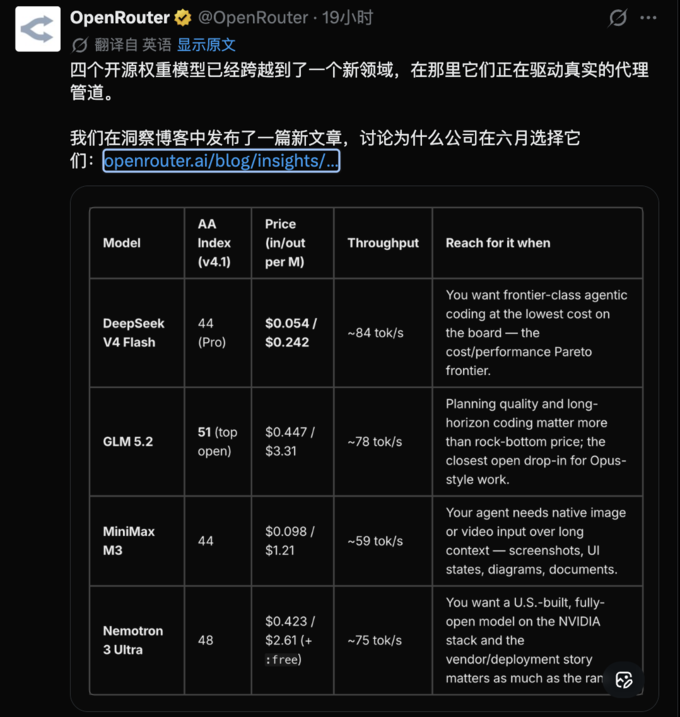
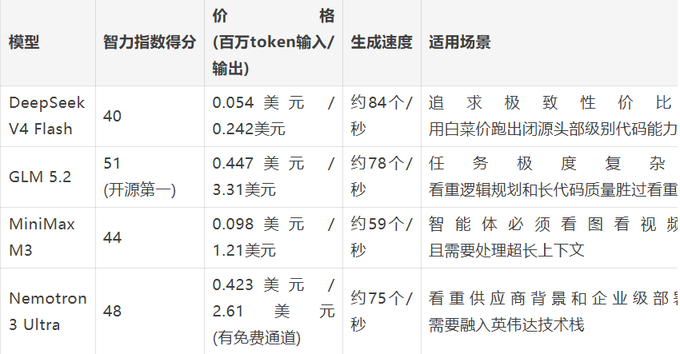
新模型发得快,各项能力长短不一,新玩家又多,普通开发者很难搞清楚到底该用哪个模型。站在2026年6月的时间节点上,OpenRouter认为目前真正具有决定性意义的开源大模型,只有下面这四个。
DeepSeek V4 Flash 跨越智能体分水岭
DeepSeek V4 Flash是第一个被开发团队直接塞进智能体工作流的开源模型,大家完全把它当成了Anthropic或OpenAI同级别闭源模型的完美平替。
大杯版本的V4 Pro在SWE-bench Verified测试中拿下了80.6%的成绩,刷新了开源模型的最高分,直接看齐GPT-5.5级别的智能体表现。但真正引爆市场的是Flash版本,它保留了绝大部分核心能力,同时把性价比推向了极致。
Flash版本采用MIT协议,是一个拥有2840亿总参数和130亿激活参数的MoE模型,支持百万token上下文。它的SWE-bench Verified得分是79.0%,和Pro版以及那个1.6万亿参数的超大杯相比,差距都在1.6分左右。2026年4月发布。
大家疯狂用它,主要还是因为太便宜了。在DeepSeek官方API上,Flash版本的输入和输出价格分别是每百万token 0.14美元和0.28美元。如果算上缓存折扣,输入价格还能降到0.029美元。官方在五月份把这个号称打了骨折价固定成了永久价格。对比下来,它的输出成本大概只有GPT-5.5的150分之一。
也可以选择西方的第三方托管平台,价格大概是官方的两倍,但考虑到它的智力水平,这依然白菜价。DeepSeek官方带头打价格战,直接把这个智力级别的模型价格彻底打了下来。
避坑指南: 日常使用中,它干技术活很利索,但写文章和语气把控一般。提示词需要写得非常具体,它更吃指令,不能过度依赖它自己的发挥。
适用场景: 需要用极低成本跑出闭源头部级别智能体或写代码。首选Flash版本,如果真的需要那一点点极限性能提升,再上Pro版。
GLM 5.2 复杂规划与代码能力的顶级平替
GLM 5.2在6月中旬才刚刚发布,初期的口碑已经炸裂。DeepSeek靠价格杀出重围,GLM 5.2的核心杀手锏则是任务规划和超长上下文代码编写。
在Artificial Analysis最新的4.1版本智力指数榜单上,GLM 5.2拿下了51分,稳坐开源模型第一名,距离闭源的Claude Fable 5只差了5分。在真实的智能体基准测试中,它同样领跑开源阵营,基本和GPT-5.5 xhigh版本打平。
虽然刚发布不久,很多第三方平台已经火速上线。它的均价是每百万token输入0.447美元输出3.31美元。单看token价格比GPT-5.5或Opus便宜,但这个模型在输出时非常喜欢深入思考,消耗的token量大,跑起来还是会有点费钱。
这背后还有一个助推因素。美国刚出了出口管制新规,迫使Anthropic大规模禁用了Fable 5和Mythos 5的海外访问权限。作为一个采用MIT协议且代码能力极其接近闭源头部的模型,它成了很多追求业务稳定性的企业的香饽饽。
避坑指南: 同样是纯文本模型,不支持图像和视频。思考过程会消耗大量输出token,比较费钱。刚发布不久,各家托管平台的质量参差不齐。最高生成速度大约每秒78个token,比DeepSeek V4 Flash的84个略慢。
适用场景: 完美替代闭源模型做智能体规划和代码生成。非常适合处理架构设计、整个代码库级别的重构或是耗时很长的智能体任务。
MiniMax M3 把多模态和长文本做到极致
在这四个模型里,MiniMax M3是唯一一个原生理解文本图表和视频的模型。如果你的智能体需要看屏幕截图、分析UI界面、读懂架构图或者看视频,M3是首选。
在智力指数榜单上,它和DeepSeek V4 Pro并列拿了44分,落后于GLM和英伟达。但它的核心竞争力是多模态能力,单纯看分数意义不大。在真实的智能体测试中,它的表现基本和Claude Sonnet 4.6持平。
价格诱人,每百万token输入0.098美元输出1.21美元,当然如果上下文超过51万token价格会上浮。和GLM类似,单价便宜不代表总价低,M3也是个话痨,推理过程很长。
避坑指南: 没用MIT协议,用的是自家的社区协议。商业使用需要加署名,大型商业产品还要书面授权。文本代码能力不如GLM 5.2。各家服务商对全量上下文的支持程度不一样。
适用场景: 需要处理原生图片或视频的长文本智能体。适合UI自动化测试、看图写代码、图文文档解析、视频工作流或是混合了代码和文档的复杂任务。是谷歌Gemini Flash在多模态理解领域的强力竞争对手。
NVIDIA Nemotron 3 Ultra
英伟达的Nemotron 3 Ultra是美国本土最能打的开源模型。它是一个专为企业部署打造的严肃推理模型,背后有整个英伟达软硬件生态撑腰。
它的跑分很稳,智力指数排名第二,拿到48分,仅次于GLM 5.2。
它的核心差异化优势在于极高的部署效率。现在的加权平均价格是每百万token输入0.423美元输出2.61美元,它还有一条免费测试通道,目前极其火爆。
参数方面,它是一个5500亿总参数和550亿激活参数的Mamba-2与Transformer混合MoE模型。使用了NVFP4精度,支持百万上下文和多token预测技术,采用OpenMDW协议。英伟达这次连同模型一起把训练数据、配方、评估工具和强化学习基础设施全给开源了。
英伟达的算盘打得很响,开源模型用得越多,市场对他们家各种芯片计算卡以及软件生态的需求就越旺盛。Nemotron不仅仅是个模型,它更是用来给整个英伟达AI全家桶拉客的招牌。英伟达不差钱,他们有足够的财力持续投入研发,在这个赛道里卷下去。
避坑指南: 纯文本模型。基础智力比不上GLM 5.2,极限代码能力也略逊于中国开源头部。免费通道只能用来测试玩玩,不能支撑正式的商业产品。协议是OpenMDW,不如MIT开放。
适用场景: 当企业对运行速度、私有化部署、数据控制权和供应商背景的看重程度超过了对极限跑分的追求时,选它最合适。
总而言之,DeepSeek证明了开源大模型完全能胜任前沿智能体工作,而且只收个零头。GLM拿下了质量榜单的铁王座。MiniMax成了平价多模态领域的扛把子。英伟达则带着深厚的家底,给出了一个完全开源的美国本土企业级方案。开源和闭源的差距确实存在,但这层窗户纸已经非常薄了。弄清楚自己的业务到底需要极限低价、顶级质量、多模态能力还是企业级部署,对号入座去挑选测试,这才是最靠谱的做法。