一文看透RAG:改变AI命运的一块「抹布」AI Native启示录
2020年5月,也就是 ChatGPT 惊艳全球的两年半之前,Facebook AI Research 的 Patrick Lewis 和他的团队发表了一篇论文。当时,大模型还远未火出圈,他们为了解决知识密集型自然语言处理任务,提出了一套"检索+生成"的混合架构,并随手给它起了一个缩写:
RAG(Retrieval-Augmented Generation,检索增强生成)
如果直译成中文,RAG 的意思是"抹布、破布"。Patrick Lewis 本人后来在采访中坦言,如果当年知道这项技术会火成这样,他一定会认真想个好听点、更显高级的名字。
学术界精雕细琢的原始端到端框架,最终演变成了工程界简单粗暴的"乐高积木",并以一块"抹布"的名字,成为了当今大模型时代最重要的技术补丁。
这块"抹布"到底擦掉了大模型时代的什么污点?它又是如何运转的?今天,我们就避开艰涩的代码,用大白话和生活中的比喻,带你彻底看透 RAG 这台神奇机器的五脏六腑。
一、大模型的"阿喀琉斯之踵":一位入戏太深的即兴演员
要理解为什么我们需要 RAG,必须先看透大模型的真面目。很多人以为大模型是一个无所不知的巨型数据库,你一问,它就去"查"。这个想象从根上就错了。
大模型的本质,是一台接龙机器:它根据前面的文字,预测下一个最可能出现的词。
你可以把大模型想象成一位博闻强识但从不带讲稿的即兴演员。他读过世上几乎所有的书,但一页都没带在身上;无论你抛出什么话题,他都能流畅接茬,因为他的职业底线是"戏不能停"——哪怕遇到不懂的问题,也会根据统计概率"圆"下去。
这种"一本正经地胡说八道"的现象,业内称为幻觉(Hallucination)。有些学者甚至刻薄地认为,这不叫幻觉,而叫"扯淡(Bullshit)",因为大模型对真假根本没有概念,只对"像不像人话"负责。
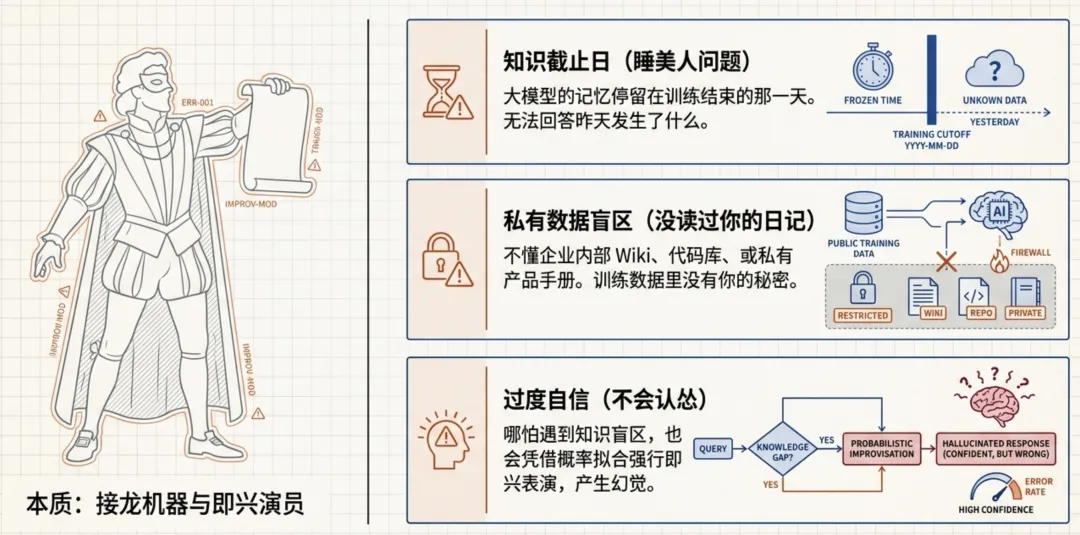
这位顶级的即兴演员,有三个娘胎里带出来的致命缺陷:
知识有截止日(睡美人问题):模型的知识停留在训练结束的那一天,就像睡美人一觉醒来,还以为现在是一百年前。
私有数据盲区:它在公开互联网上长大,从没看过你们公司的内部规定或你的私人日记。
过度自信:人类专家知道自己哪里不会,而大模型在输出错误答案时的语气,和输出正确答案时一样斩钉截铁。
image-20260617151356430
怎么治?重新训练一个模型?那需要成百上千万美元的算力,普通人根本玩不起。给模型做微调(Fine-tuning)?那更像请个健身私教,能改变演员的说话语气和发力体态,但没法把一本厚厚的《民法典》直接塞进他脑子里。
性价比最高的终极药方,就是 RAG(检索增强生成):给即兴演员安排一场"开卷考试"。
既然大模型记不住新知识,那我们就在他上台前,配一位贴身资料员。观众点什么戏,资料员先冲到后台档案室,翻出相关的剧本片段塞给演员,演员再照着手里的资料发挥。
演员还是那个演员,一个参数都没改;但开口前,他手里多了几页"小抄"。这完美解决了知识更新、私有数据接入和过度自信的问题。
那么,这位负责翻档案的"资料员",是怎么在海量数据里瞬间找到正确答案的?
二、将文字化作繁星:Embedding 的"语义地图"
假设用户问:"我工作满三年了,年假有几天?"
系统怎么知道文档中写着"享有带薪休假 X 天"的段落正是我们要找的答案?这两句话连一个相同的关键词都没有。
在计算机眼里,文字只是没有感情的编码,"猫"和"狗"的距离,跟"猫"和"冰箱"的距离没有任何区别,它是彻底的"语义文盲"。为了让计算机理解"意思相近",我们需要给每一段文字发一张"语义身份证"——这就是Embedding(嵌入向量)。
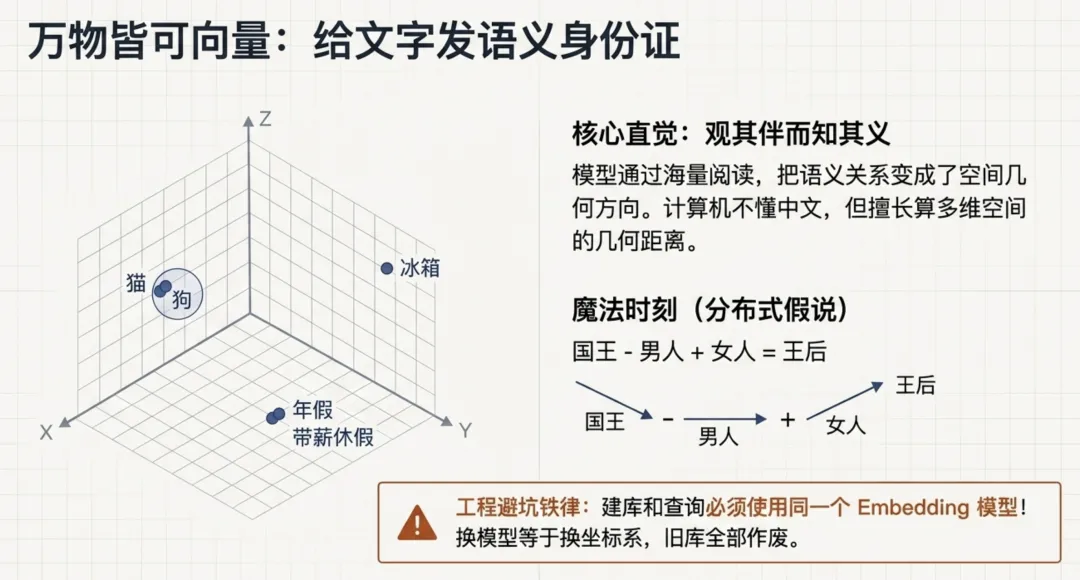
Embedding 的核心魔法,是把一段文字变成一串长长的数字,使得语义相近的文字,在多维空间中的坐标也相近。你可以把它想象成一张语义城市地图:"猫"和"狗"在"宠物街区"做邻居;而"冰箱"则在城市的另一头;"年假"和"带薪休假"几乎住在同一栋楼里。这样,寻找相关资料就变成了计算机最拿手的几何测距问题。
这张神奇的地图是谁画的?理论基础来自1957年英国语言学家 J.R. Firth 的一句暴论:
"观其伴而知其义(You shall know a word by the company it keeps)"
看一个词跟什么词混在一起,就知道它是什么意思。
2013年,Google 的 Tomas Mikolov 团队发布了 Word2Vec,震撼了世界。他们通过让机器做海量的"完形填空",迫使机器把词的"邻居习性"压缩成坐标。人们惊奇地发现,语义关系居然变成了几何方向:
在地图上拿"国王"减去"男人"加上"女人",
得到的坐标恰好是"王后"!
如今的 Embedding 模型已经进化到能够根据上下文,给整个句子进行精准的"实时定位"。
将文字化作语义坐标的嵌入向量示意图
三、修路与切肉:向量检索与分块的艺术
有了坐标点,面对几十上百万份资料,我们总不能一个个去量距离吧?
在小数据时代,暴力检索(全比一遍)是朴素的幸福,精确无误。但在大数据时代,为了在毫秒级找到答案,我们需要一种叫HNSW(分层可导航小世界)的近似搜索算法。
HNSW 的原理就像现实中的道路导航。你要从北京去广州的一条小巷,绝不会一路走胡同;你会先上高速公路(跨越大距离),然后换国道(中等精度),最后钻进乡间小路(精确定位)。HNSW 在多维空间里修建了这套多层路网,用大约2%的精度牺牲,换来了一万倍的速度提升。
有了检索的基础设施,另一个更接地气、却决定了系统生死的核心问题出现了:文本分块(Chunking)。
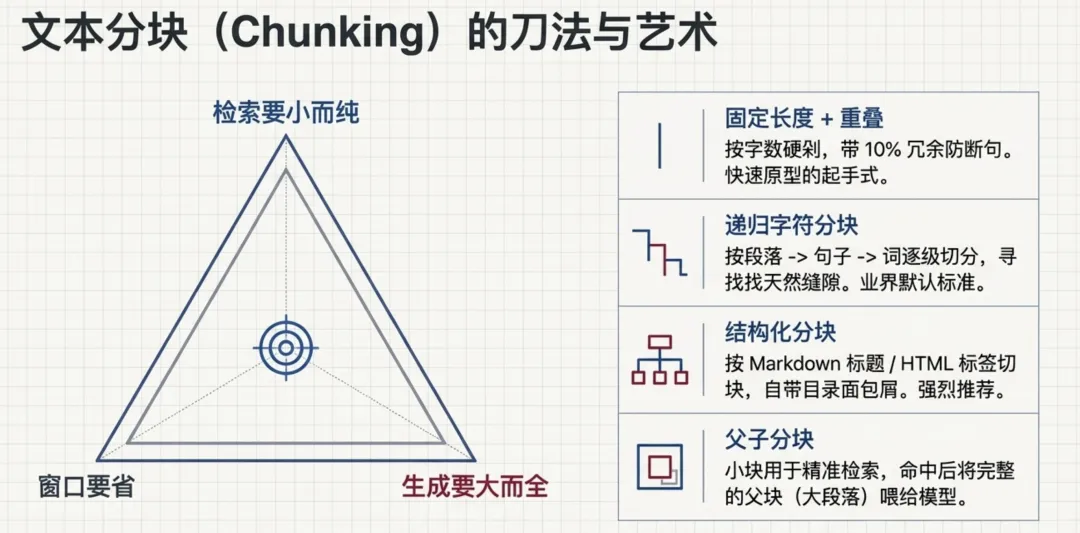
检索系统只能寻找"资料块",如果把一整本书当成一块,它的语义就会像一锅大杂烩,什么都沾边但什么都不纯;如果切得太碎,找回来的就是只有半句话的"断头句"。所以,必须像庖丁解牛一样切分文档。
菜刀派(固定长度):不管三七二十一,每500字切一刀,极容易把"工龄满三年享有年假10"和"天"残忍分开。
骑墙派(重叠分块):像拍全景照片一样,相邻块之间留一点重叠区,这是性价比最高的默认补丁。
结构化分块(看图纸下刀):如果有标题、有段落层级,就顺着这些结构切,每一块还自带"标题面包屑"作为名片。对于代码,甚至会动用编译器的手术刀(AST),按函数完整地切分,保住语法结构的完整性。
父子分块(小块检索,大块上桌):把"检索想要小、生成想要大"的矛盾直接拆开解决。文档切成大块(父块,比如2000字的完整小节),每个父块再切成小块(子块,比如300字);用子块做检索(小而纯,匹配准),命中后把它的父块塞给模型(大而全,上下文足)。
像图书馆用"卡片目录"找书:卡片(子块)信息密度高、翻得快,找到后借走的是整本书(父块)。代价是索引结构复杂一点。这是进阶配置里性价比很高的一招。
文本分块切割示意图
野史角:PDF 解析是每一位 RAG 工程师的渡劫时刻。因为 PDF 从骨子里是一个排版格式(只管把字画在哪里),根本没有"段落"的概念。从中提取文本本质上是一场痛苦的"考古"工作。
四、双剑合璧:当"读心大师"遇上"抠字眼老将"
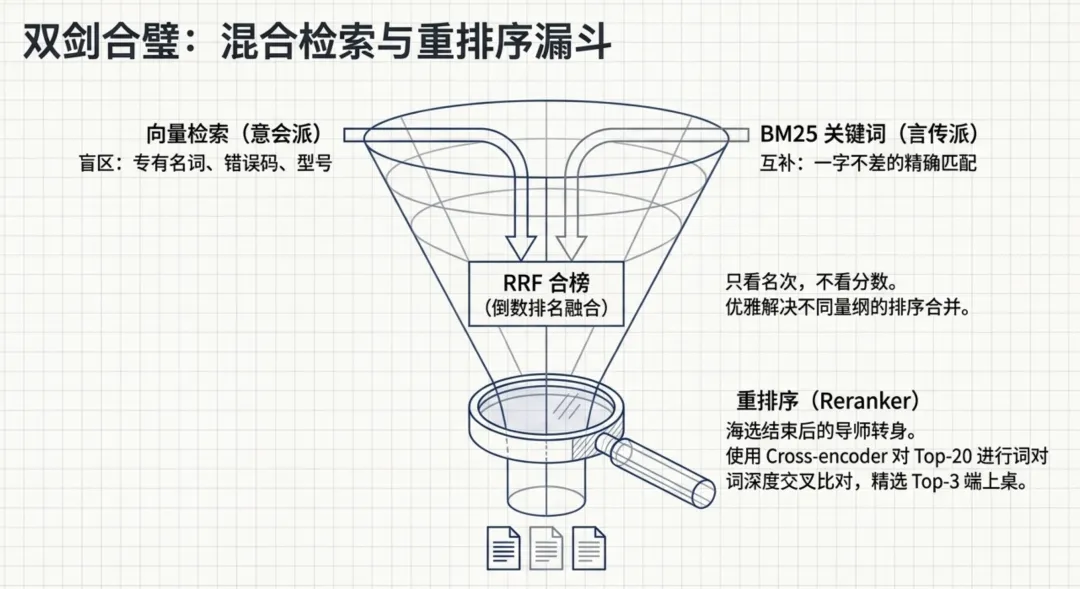
向量检索听起来很神,但它有个致命的盲区:专有名词、产品型号、错误码。
假如用户搜"XR-2024 的保修期",向量模型很可能会找回 XR-2023 的说明书。因为这两个型号在上下文里的用法太像了,在语义地图上紧紧挨着,在模型看来就是一团模糊的雾。向量检索擅长"意会",但对于要求一字不差的"暗号",就必须请出三十年前的老将——关键词检索(BM25 算法)。
BM25 秉承三个极其符合常识的直觉:词频越高越好(但边际递减);物以稀为贵(IDF,烂大街的词不加分,全库少见的罕见词一旦命中加满分);短文档比长文档更容易得高分。这套由英国计算机科学家Karen Spärck Jones在1972年提出的 IDF 理论,比万维网还要古老。
为了兼顾"意会"(懂同义词)和"言传"(抓字眼),现代 RAG 采用了混合检索。两路并发搜索后,通过一种类似于选秀节目"专业评审+大众评审"的机制——RRF(倒数排名融合)进行合榜:不看具体分数,只看双方的名次排位。
如果想精益求精,还可以在海选之后加上"导师转身"环节——重排序(Reranking)。用一种更准但更慢的模型,让用户问题和候选文档"直接见面深聊",把被埋没的好答案捞到第一名。
混合检索双剑合璧示意图