中国AI模型低成本路径正在改写行业逻辑华尔街日报
瑞银研究显示,中国AI模型的API均价不到美国同类产品的20%,但毛利率却与Anthropic、OpenAI基本持平,约在20%-40%之间。这种“低价高利”背后是训练端的稀疏注意力、低精度计算、开源生态协同,以及推理端MoE、KV缓存压缩等系统性技术优势。同时,中国前沿模型综合智能已达美国顶尖水平的约90%。
价格打到美国的五分之一,利润率却不输对手——中国AI模型的成本优势,正在逼近一个让华尔街不得不重新定价的临界点。
当企业开始因为token账单失控而踩刹车,当微软据报正在评估用DeepSeek替换Copilot中更贵的OpenAI和Anthropic模型,一个过去被市场长期忽视的问题正在浮出水面:中国AI模型的低价,究竟是补贴撑出来的虚火,还是真实的结构性优势?
瑞银半导体团队近期发布了一份深度研究,分析师Sundeep Gantori对中国主要AI模型的训练与推理成本进行了系统性拆解。测算显示,以MiniMax和智谱为例,中国模型的训练成本不到OpenAI和Anthropic的10%;API均价低于美国同类产品的20%;但毛利率——这个最能说明"是否在亏本卖"的指标——却与美国同行基本持平,约在20%-40%之间。
这意味着中国模型的低价,不是靠烧钱换来的,而是结构性成本优势的体现。
价格差距从何而来:三层成本拆解
理解这个价格差距,需要从训练、推理、基础设施三个层面分别来看。
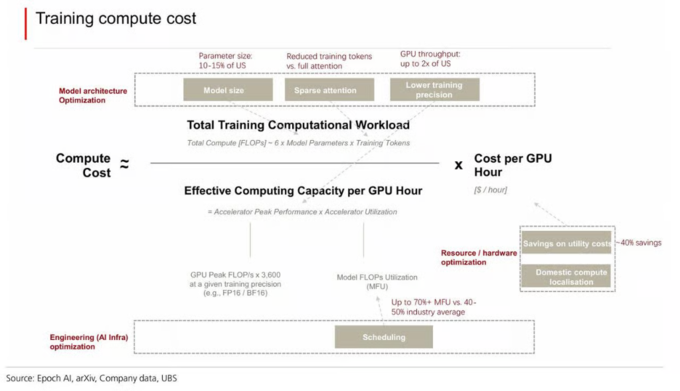
训练阶段,中国模型的参数规模普遍小于美国对手。DeepSeek V4的总参数量为1.6万亿,Kimi K2.6约为1万亿,而学术论文估算Claude Opus 4.6和GPT-5.5的参数规模分别约为10万亿和5万亿。参数少,训练计算量自然低。
但参数规模只是第一步。更关键的差异在于稀疏注意力机制的应用。传统Transformer模型中,每个token需要与序列中所有其他token交互,计算量随上下文长度呈平方级增长。稀疏注意力通过让每个token只与部分相关token交互,大幅压缩了长上下文训练和推理的计算消耗。DeepSeek V3.2采用了自研的稀疏注意力设计(DSA),V4进一步在此基础上加入上下文压缩。
在计算精度上,中国模型也走在了前面。以Nvidia B200为例,从BF16/FP16切换到FP8,理论吞吐量可以翻倍。DeepSeek-V3率先引入FP8混合精度训练框架,V4更进一步采用了FP4量化感知训练;百度ERNIE 4.5/5.0、阿里Qwen3.5均已跟进。
基础设施层面,中国的电力成本具有实质性优势。美国主要数据中心州(伊利诺伊、佐治亚)的平均电价约为7.9美分/度,而中国可比地区约为4.4美分/度,低约44%。反映到GPU租用价格上,美国市场Nvidia H100的租用成本约为1.99-3.99美元/GPU小时,中国约为1.3-2.1美元/GPU小时,低约40%。
这三层叠加下来,中国模型的成本结构系统性低于美国同行,价格优势因此具有可持续性。
推理端:更激进的技术路径
如果说训练端的成本优势主要来自资源约束下的"被迫创新",推理端的优化则更像是主动为之。
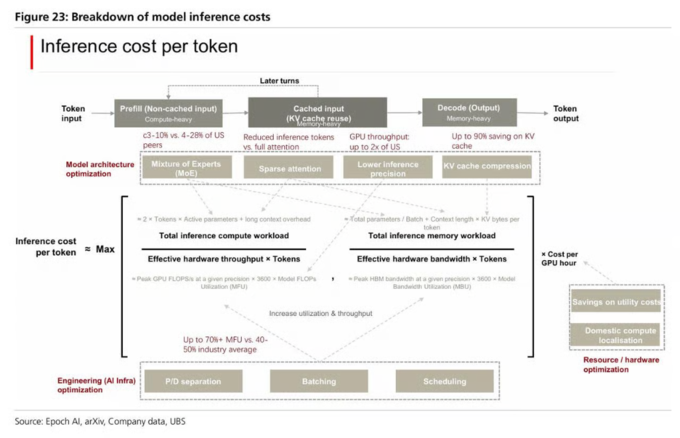
中国模型在推理阶段普遍采用混合专家架构(MoE),并且比美国同行走得更远。MoE的核心逻辑是:模型不需要为每个token激活全部参数,而是只激活其中一个子集("专家")。早期美国MoE模型如GPT-4、Llama 4 Scout通常激活约15-30%的总参数,而中国领先MoE模型通常只激活约3-10%。DeepSeek从V3.2到V4 Pro,活跃参数比从约5%降至约3%,但模型智能指数(AA Intelligence Index)反而从42升至52。
KV缓存压缩是另一个关键杠杆。在多轮对话类的智能体任务中,缓存输入成本约占总推理成本的70%。DeepSeek V4引入了重度压缩注意力(HCA)和压缩稀疏注意力(CSA)技术,使V4在相同上下文长度(100万token)下只需要V3.2约10%的KV缓存——这直接使DeepSeek V4 Pro的综合成本比V3下降约10%,尽管性能有了显著提升。
在服务编排层面,P/D分离(预填充与解码分离)将推理过程中计算密集型和内存密集型两个阶段拆分到不同GPU池,避免相互干扰;持续批处理则让GPU在请求完成后立即接入新请求,而非等待最慢的那个,显著提升吞吐率。MiniMax通过其端到端基础设施团队,实现了超过75%的MFU(模型算力利用率),高于行业平均水平的40-50%。
这些技术的叠加,使得推理成本持续压缩,而毛利率仍能维持在合理水平。MiniMax M2.7的毛利率超过40%,与Anthropic 2025年约40%的API毛利率基本一致。
性能差距正在快速收窄
成本优势要真正形成市场威胁,需要配合足够的能力。这正是当前局面的关键变量。
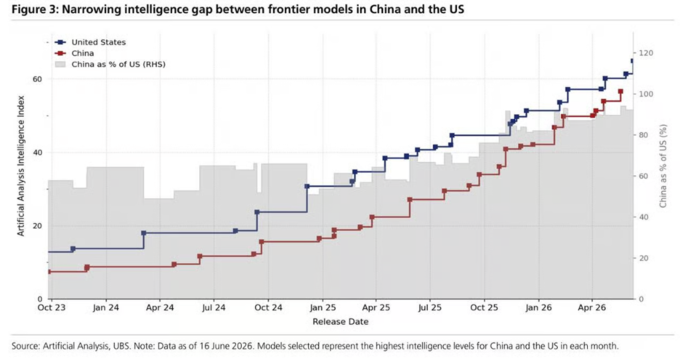
根据Artificial Analysis的数据,2023年中国前沿模型的综合智能约为美国顶尖模型的60%;到2025年,这一比例已上升至约90%。
分领域来看,差距并不均匀:
文本模型综合智能:已接近90%水平
AI编程:中国领先模型(如Qwen3.7-Max、DeepSeek V4-Pro)已可比肩美国上一代模型(如Claude Opus 4.6),但仍落后于最新前沿模型Claude Fable 5和GPT-5.5
多模态与视频生成:全球前五名视频生成模型中,有四个来自中国
研发投入的对比同样鲜明。智谱和MiniMax 2025年的R&D支出分别约为5亿和3亿美元,合计约为Anthropic R&D支出的十分之一,相对OpenAI则更低。
这种以极低研发投入实现快速追赶的路径,有两个支撑。其一是蒸馏技术,让小模型通过模仿强模型的输出来提升能力,缩短训练周期。但行业调研认为,蒸馏效果主要局限于结果可验证、流程可重复的任务,对需要复杂多步推理或底层架构支撑的能力提升效果有限。智谱在长程推理上的进展、MiniMax在多模态上的能力,均超出了蒸馏所能解释的范围。
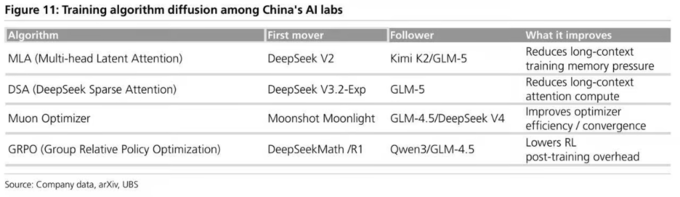
其二是开源生态的集体杠杆效应。当一家实验室验证了某种架构或训练方法,其他实验室可以直接在此基础上迭代,而无需重复相同的大规模实验。Kimi K2和GLM-5采用了类似DeepSeek验证过的MLA潜在注意力设计;DeepSeek V4引入了Moonshot AI/Kimi的Muon优化器;Qwen3和智谱GLM-4.5均采用了DeepSeek验证的GRPO强化学习方案。这种"集体实验、分散受益"的模式,使整个中国AI生态的R&D边际成本系统性低于各自为战的美国闭源模型。
企业正在踩刹车,这对谁有利
成本压力已经从宏观讨论落地为具体的企业行为。
Uber在2026年4月就用完了全年AI预算,随后对员工个人AI工具的月度token消耗设置了1500美元上限。Walmart限制了内部AI智能体的token使用量。Amazon警告员工不要"为了用AI而用AI",并关闭了助长无效使用的内部AI-token排行榜。软件公司Workato在Anthropic从订阅制切换到按token计费的第一天,支出直接翻了7倍——首席信息官Carter Busse直言:"我们创造了一个怪物。"
OpenAI CEO山姆·奥特曼今年也公开承认,成本已成为客户面临的"巨大问题",而去年这个问题几乎不存在。
根据SiliconData的LLM Token支出指数(以支出/使用量加权的平均token价格),今年5月之前该指数持续攀升,近期已出现明显回落,可能反映企业正在从高端闭源模型转向更经济的替代品。咨询公司Entelligence对2444家企业的调查显示,企业AI编程支出中,只有18%最终转化为生产输出,其余82%被bug修复、代码重写和审查延误所消耗。