Fable 5突遭下架,GLM-5.2全量开放新智元
GLM-5.2全量开放!1M上下文真能用,长任务不忘事。
昨晚,Claude Fable 5被美国政府一封信直接全球下架。
上线才72小时,说没就没。连Anthropic自家外籍员工都不许碰。数亿用户一觉醒来,直接懵了。
老外自己先坐不住了,梗图满天飞——Anthropic那边说「我们的模型太危险了」,美国政府回一句「那我禁了」。
就在刚刚,国产模型回应来了:GLM-5.2,全量用,最高权限开源。
GLM Coding Plan 全量用户开放,Lite、Pro、Max、团队版,今晚全部能用!
下周API上线,MIT协议开源,权重随便拿。
一边在关门,一边在开门。
从GLM-5到5.1再到今晚的5.2,智谱在Coding这条路上死磕了整整一年。
5.1刚把开源模型推到8小时长程任务,社区反馈还很热,5.2就直接把上下文怼到了1M——而且是那种真能用的1M!
这次GLM-5.2有两个关键词:真1M上下文,Coding国产之光。
到底怎么样?全网都在等Bench
在Anthropic这一通操作的背景之下,5.2模型刚一宣布要开源,海外社区就炸了。
国外知名博主AICodeKing在内测完给出的评价相当直接:这个模型品位出色,代码始终非常干净。我让它微调一个完整的本地模型,30分钟就搞定了。全方位都表现优异。
目前已公布的开发者实测Bench来看,性能基本对标Opus 4.8——实打实的国产之光。
智谱其实在前两天就开通了coding plan用户的一波内测(在最近的AI圈发模型中也是常规操作了)
而我们潜水的内测社群里,体感反馈也一致得吓人。
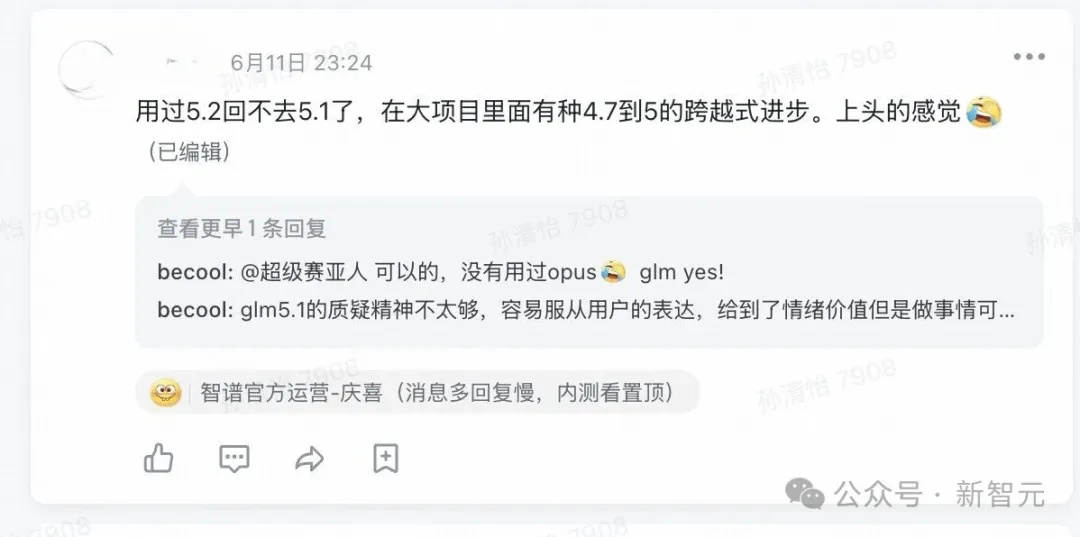
有网友表示,「这是国内第一款在我工作流上达到Opus级的模型」。
另一位内测用户更直白——「用过5.2回不去5.1了,在大项目里面有种4.7到5的跨越式进步。上头的感觉。」
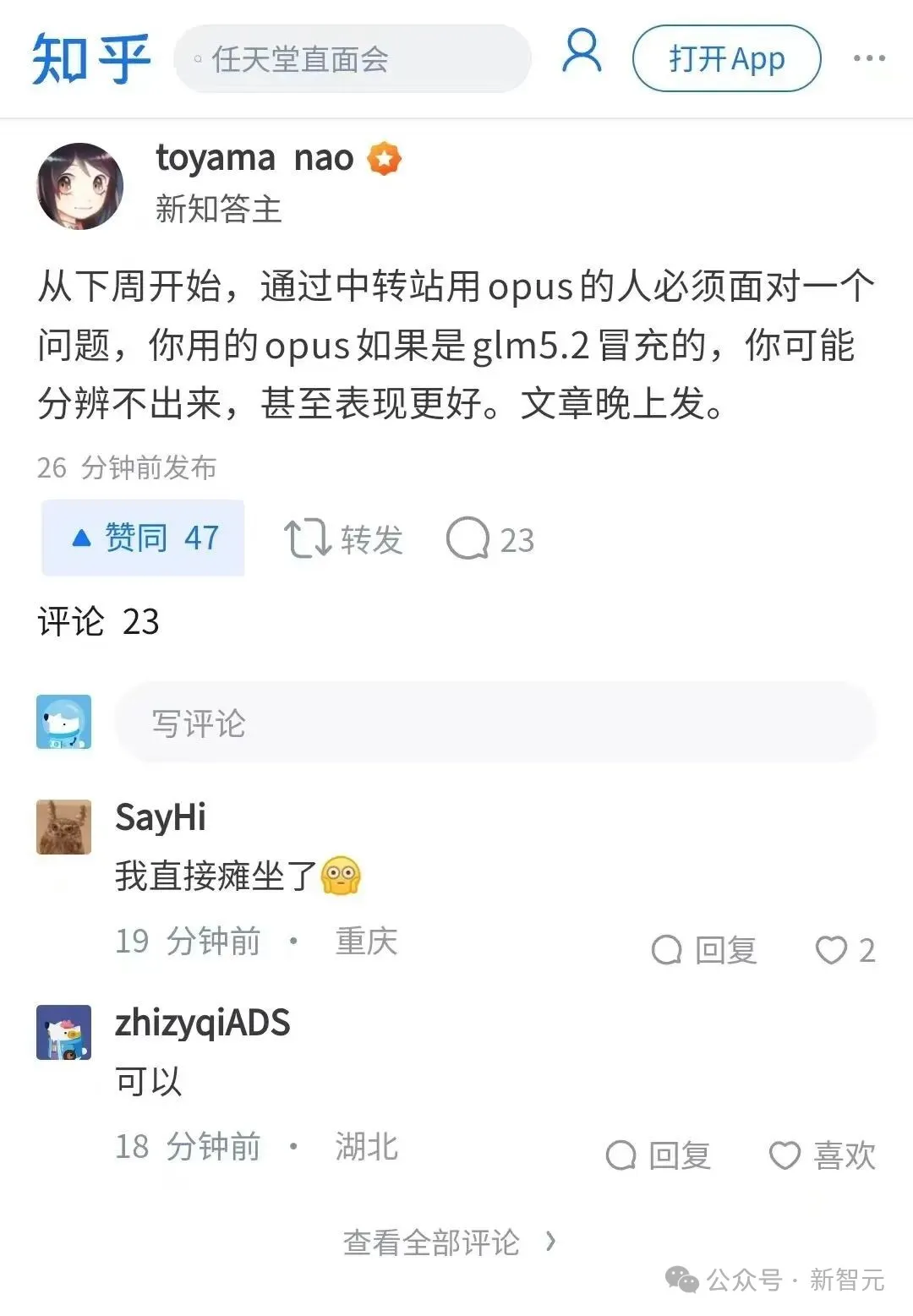
知乎上甚至有人说:「从下周开始,通过中转站用Opus的人必须面对一个问题——你用的Opus如果是GLM-5.2冒充的,你可能分辨不出来,甚至表现更好。」
官方Bench还没出全,全网都在等。但就目前开发者自己跑出来的数据和体感来看,Coding国产第一这个位置,GLM-5.2坐得稳。
第一时间拿到内测资格后,我们也迫不及待地上手实测了下。果然和之前的模型不一样。
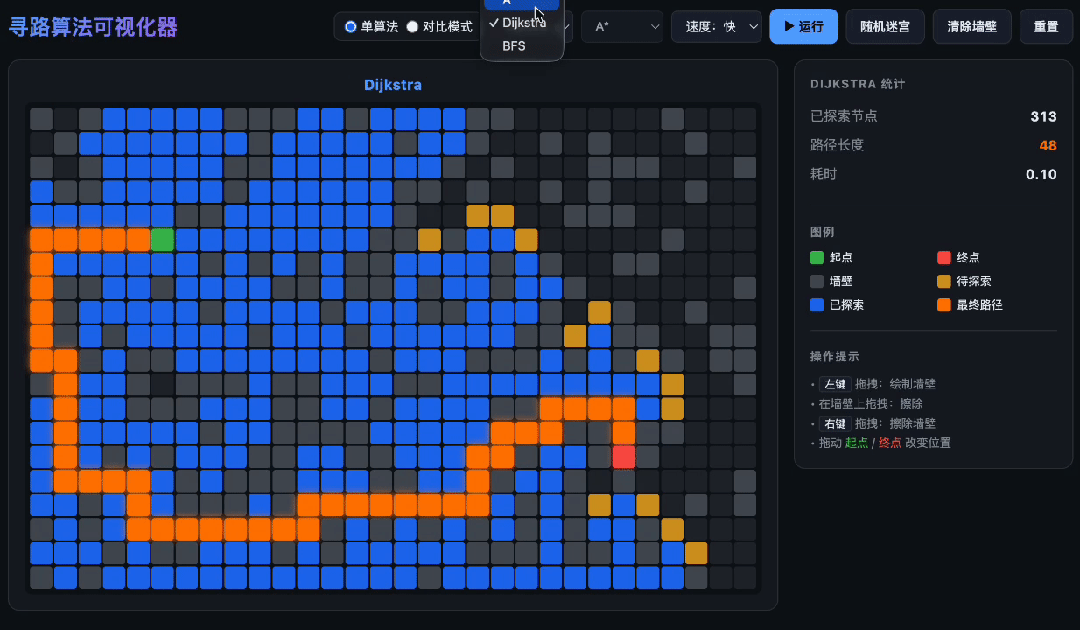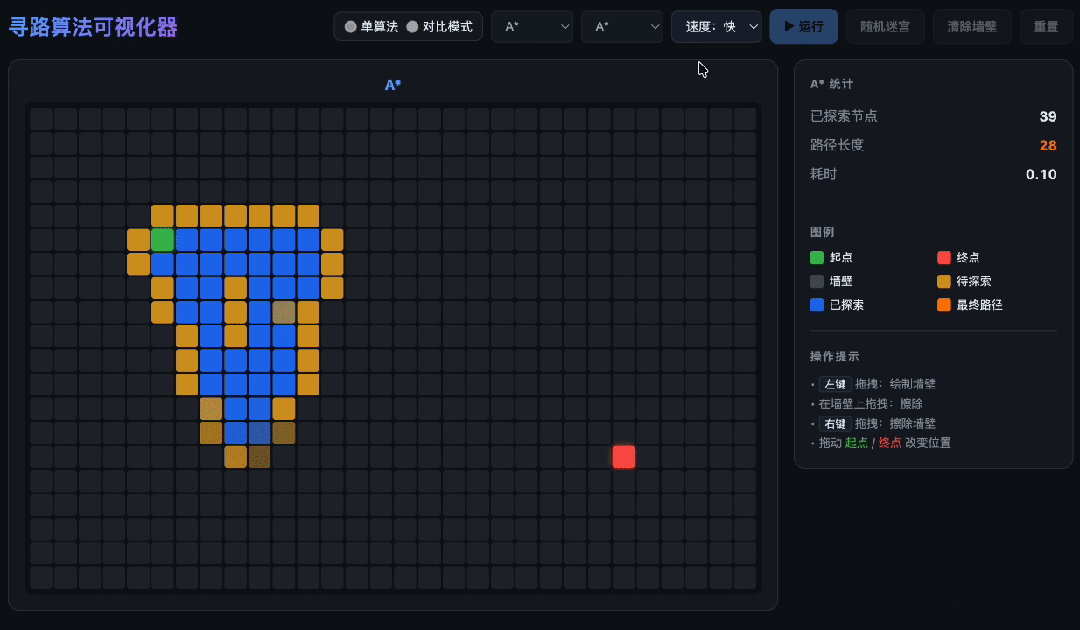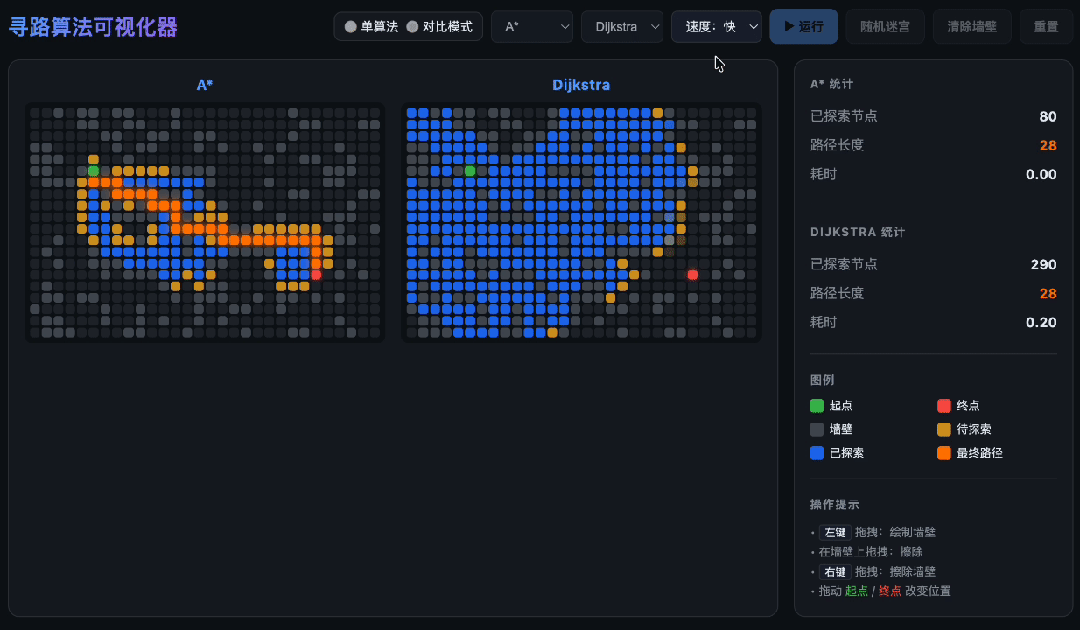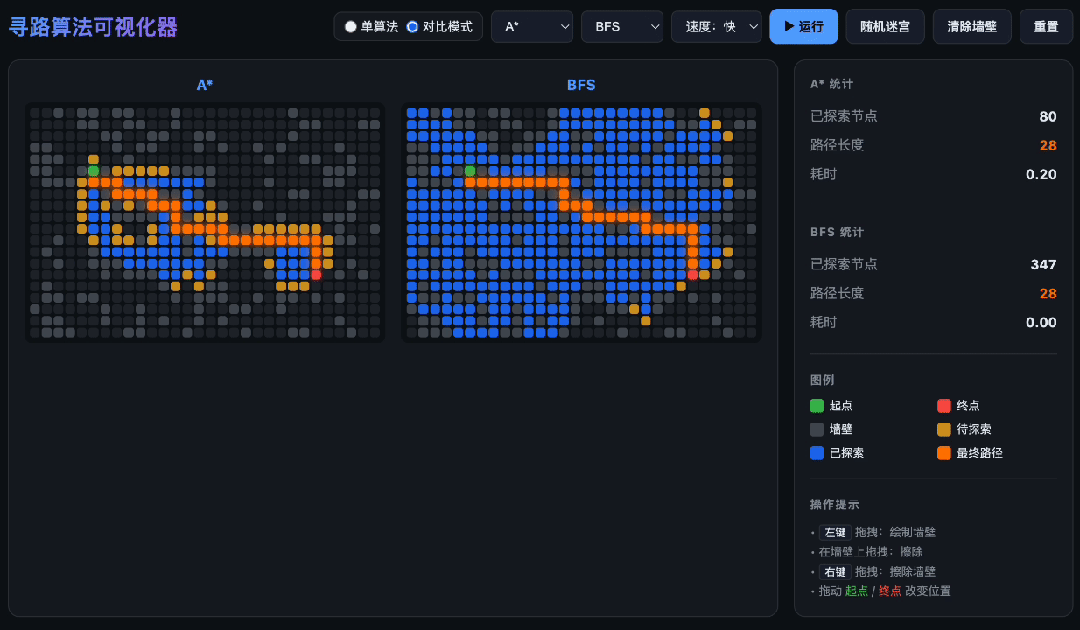
一口气写完,三种寻路算法全跑对了
让GLM-5.2写一个寻路算法可视化器。它给你一次搞定。
A*、Dijkstra、BFS——三种算法各有各的套路,一个都没搞混。
连优先队列都是自己写的,不是拿现成的库糊弄。
最狠的是分屏对比:两种算法同时跑,各走各的路、各算各的数,画面上五颜六色地铺开——这等于一个文件里同时管两套独立的搜索过程,状态一串就全乱。它没串。
六套逻辑塞在一个文件里,从头到尾都不打架——算法、动画、交互、对比、统计、迷宫生成,全记着,全对着。
Coding跟长上下文的真功夫,就体现在这种地方。
长任务,不忘事
GLM-5.1已经能连续自主工作8小时,但想再往前推,绕不开一个坎:上下文。
一个连续干几小时活的智能体,要经历数千次工具调用、读写几万行代码、攒下一大堆中间状态。
窗口不够长,它就得不停压缩、丢弃。很多长任务翻车,不是模型不够聪明,是它忘了。
所以1M上下文的意义,不是参数表上一个更大的数字,而是让模型能把整个项目一口气吃进去——代码、决策、约束全记着,从头干到尾不丢东西。
现在标称1M的模型不少,但用过的人都有体感:喂进去是喂进去了,记不太住。
很多模型过了25万token就开始「失忆」;而且上下文越长,算力和显存烧得越猛——不是不能跑,是跑起来又慢又贵,没人敢这么用。
从结构下手,用一套注意力层面的创新组合拳,把1M长度下的效果衰减和推理成本一起压了下来。
在长文基准上,GLM-5.21M长度的衰减明显小于同类模型。
连续干了4小时,搓出一整个合成器工作站
这个case最能说明「长任务,不忘事」到底意味着什么。
一句话需求扔过去——做一个专业级的HTML音乐合成器工作站,WebAudio,零依赖。
然后它就开始干了。不是干几分钟,是整整4个小时,一口气,中间没人插手。
4个小时里它自己写代码、自己组了29个review智能体从4个维度对着自己的代码挑毛病、揪出18个bug全部修掉、还跑了Headless Chrome自动化测试验证完整音频链路。
最狠的是,自动测试还抓到了一个review都没发现的致命bug,它自己修了。