HuggingFace力荐,Bengio也押注:这个1500训出的模型量子位
好家伙,这次不是模型圈自嗨。
一个训练成本约1500美元、参数量约1B、从零开始预训练的小模型,把HRM推到了下一代推理架构讨论的中心。
HuggingFace联合创始人兼CEO Clem Delangue亲自转发推荐。
图灵奖得主Yoshua Bengio作为共同作者参与的新论文,也走向了同一条latent recursive reasoning路线。
更反常的是,它不是蒸馏,不是微调,也不是在已有大模型能力上套壳。
它就是Sapient Intelligence发布的HRM-Text。
如果只看参数量,它很容易被写成一个熟悉的故事:“小模型又赢了。”
但HRM-Text真正值得注意的地方,不是小,也不是便宜。而是它背后那套HRM架构,正在问一个更底层的问题:
模型到底需要记住全世界,还是需要学会如何思考、如何查找、如何验证、如何行动?
过去几年,大模型行业的默认答案很简单:参数更多,数据更多,训练更久,Token更长。
HRM走的是另一条路。
它不是继续把模型做成一个越来越大的知识仓库,而是试图把模型做成一个更强的推理核心。
大模型像一个背着图书馆的学生,HRM更像一个会解题、会查资料、会复盘、会行动的人。
当然,真正让技术圈认真讨论HRM-Text的,不是一次转发,而是一组很反常的数字。
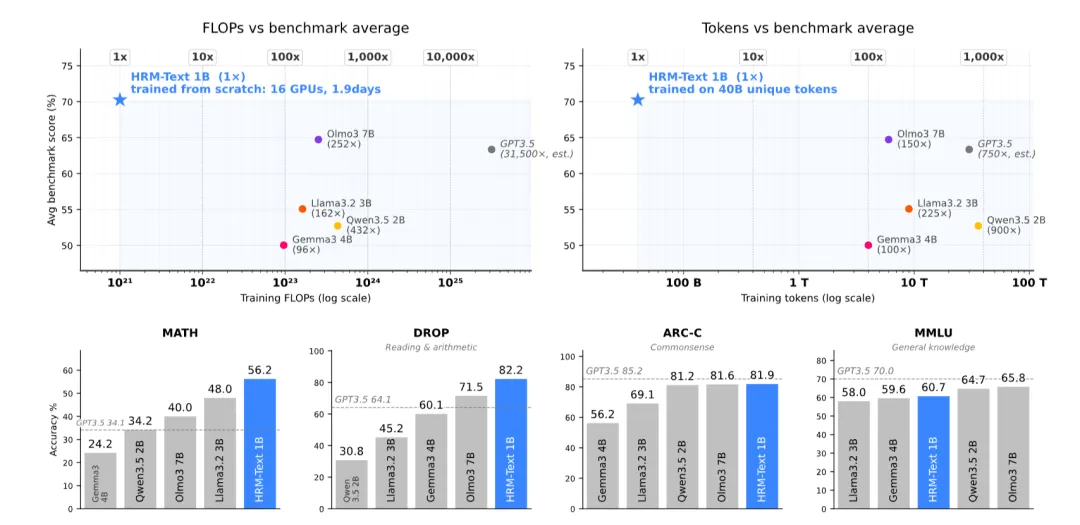
一个约1B参数模型,在MATH上拿到56.2,在GSM8K上拿到84.5,在ARC-Challenge上拿到81.9,在DROP上拿到82.2。
训练成本约1500美元,16块H100跑了不到两天。
没有post-training,没有RLHF,也没有依赖显式思维链数据。团队同步开放了论文、模型权重和预训练代码。
这意味着,HRM-Text不是在现有大模型能力上做包装,而是在基础预训练阶段,直接验证一种新的架构路线。
这不是又一个“小模型逆袭”的故事。更准确地说,它是一次推理模型的换脑实验:
不让模型说出更多思维链,而是让模型在开口之前,先在脑子里想完。
而这条路线,很快也出现在了更高层级的学术讨论中。
HRM-Text发布前后,图灵奖得主Yoshua Bengio作为共同作者参与发布了《Generative Recursive Reasoning》。论文提出的GRAM,在核心计算结构上高度复用了HRM的分层递归骨架:同样是高层状态、低层状态、双时间尺度、多轮递归更新,只是在此基础上进一步加入概率生成模块。
换句话说,Sapient不是等行业给出答案之后再追随,而是先把一个关键问题抛了出来,并率先拿出了可运行、可开源、可验证的模型系统:
模型能否在输出之前,通过潜空间中的多轮分层递归计算,完成更深层的内部推理?
HRM-Text的问题因此不只是:
一个1B模型为什么能做到这些benchmark?
更关键的问题是:
Sapient是否提前验证了一条下一代推理模型值得认真对待的新路线?
知识不等于智能,CoT也不等于思考
现在的推理模型,很多时候像是在“边说边想”。
Chain-of-Thought把推理过程写成一串token,让模型一步一步输出中间过程。
这当然有用,但问题也很明显:
Token越来越长,账单越来越高;中间一步错了,后面就可能一路错下去;更关键的是,推理过程被绑定在语言表面,模型很容易学到“像推理的文本”,却不一定真的掌握了“推理的结构”。
HRM问的是一个更激进的问题:推理为什么一定要写出来?
人类做很多题,并不是把脑内每一步都说成一句话。我们会在脑子里反复尝试、修正、排除、回退,最后才说出答案。
HRM想做的,正是这件事:把草稿纸从嘴上拿下来,放回模型的脑子里。
这就是latent reasoning,潜空间推理。不是让模型输出更长的思维链,而是让模型在输出之前,在内部状态里完成多轮计算。
这也是Sapient 从一开始押注HRM的原因。
Sapient押注的从来不是“小模型”,而是HRM(Hierarchical Reasoning Model),分层推理模型。
在大多数团队仍然围绕Transformer做参数、数据和训练技巧优化时,Sapient选择把问题推到更底层:
如果智能不是只来自规模扩张,而是来自计算过程的组织方式,那么模型架构本身是否应该被重新设计?
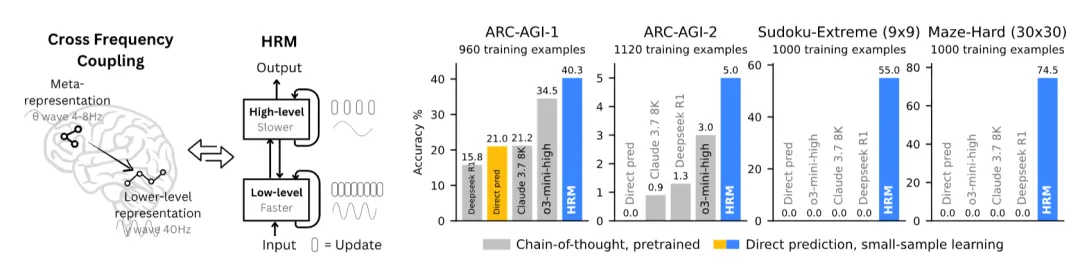
HRM的核心思想,是让模型在输出之前,能够在潜空间中进行多轮、分层、递归的状态更新。
2025年,Sapient推出HRM-Symbolic。
这个模型主要面向数独、迷宫、ARC-AGI等封闭、可验证、强推理任务。这类任务有明确规则、明确状态空间、可验证答案,对组合搜索和多步推理要求极高。
因此,它们非常适合回答第一个问题:
分层递归推理这条架构路线,到底能不能行?
HRM的原始论文里,一个27M参数模型在没有预训练、没有CoT数据、只用约1000个训练样本的情况下,在Sudoku-Extreme、Maze-Hard和ARC-AGI等强推理任务上取得了非常突出的结果。
这一步先回答了一个问题:
在封闭、可验证、强推理任务里,HRM这条路线能不能行?
答案是:能。
但这还不够,因为数独不是语言,迷宫也不是开放世界。
于是HRM-Text回答了第二个更难的问题:
当任务进入自然语言世界,HRM还行不行?
这比简单放大模型更难。
因为语言不是数独。语言更开放、更模糊、更知识密集,输出形式更灵活,训练也更容易不稳定。
所以HRM-Text的意义,不是把HRM-Symbolic放大一点而已。
它是在验证分层递归推理这套架构,能不能进入基础语言模型。
从HRM-Symbolic到HRM-Text,Sapient做的不是一次模型发布,而是一条技术路线的连续推进:
先在封闭推理任务中验证架构假设,再把架构扩展到开放语言环境,同步开放论文、代码、模型权重和训练方法,让这条路线可以被复现、质疑、比较和继续验证。
这也是Sapient应该被放到更重要位置的原因。
它不是在追随行业已有的答案,而是在提前提出问题,并把一个原本可能停留在理论讨论中的方向,推进成了可运行、可开源、可验证的模型系统。
HRM的核心:模型里面长出两个脑区