字节Lance开源即冲上抱抱脸第一量子位
多模态模型,终于不只是“会看”或者“会画”了。
字节跳动Intelligent Creation Lab这次开源的Lance,直接把图像和视频的理解、生成、编辑塞进了同一个原生统一模型里。
它能看图、看视频,能文生图、文生视频,还能按自然语言指令改图、改视频。
更反差的是,Lance不是动辄几十B、上百B参数的大块头,而是一个激活参数只有3B的原生统一多模态模型;
在最大128-GPU训练预算下,就把视频生成、视频理解、图像生成、图像编辑四类任务一起跑通了。
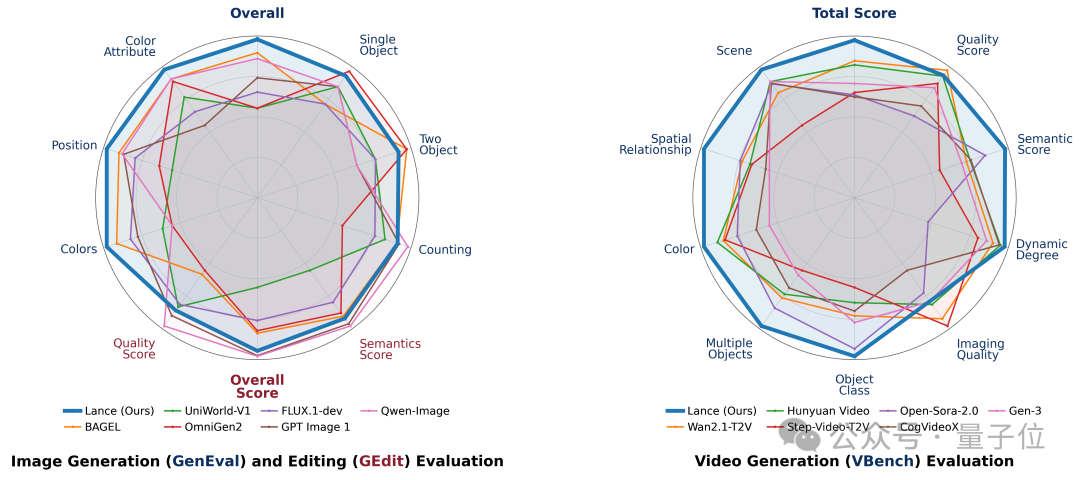
成绩也已经摆上桌:
VBench 85.11,MVBench 62.0,GenEval 0.90,GEdit-Bench 7.30。
换句话说,它不是只在某一个单项上“刷存在感”,而是把图像和视频的“看、画、改”放到同一张考卷上一起考。
统一多模态这条路,开始往“小而全”卷了。
统一多模态,卡在哪?
统一多模态这件事,听起来很自然:
人可以一边看图、一边看视频、一边描述、一边修改,模型为什么不行?
但真做起来,问题就来了。
只做理解,生成能力缺位;只做生成,问答和推理又不够;把多个模块拼起来,系统复杂、训练成本高,还很难形成真正的跨任务迁移。
所以说,现在的模型做起来,要么模型太大,训练和部署成本高;要么能力覆盖不全,尤其视频这块,经常只做生成或只做理解。
Lance要解决的,正是这个长期痛点。
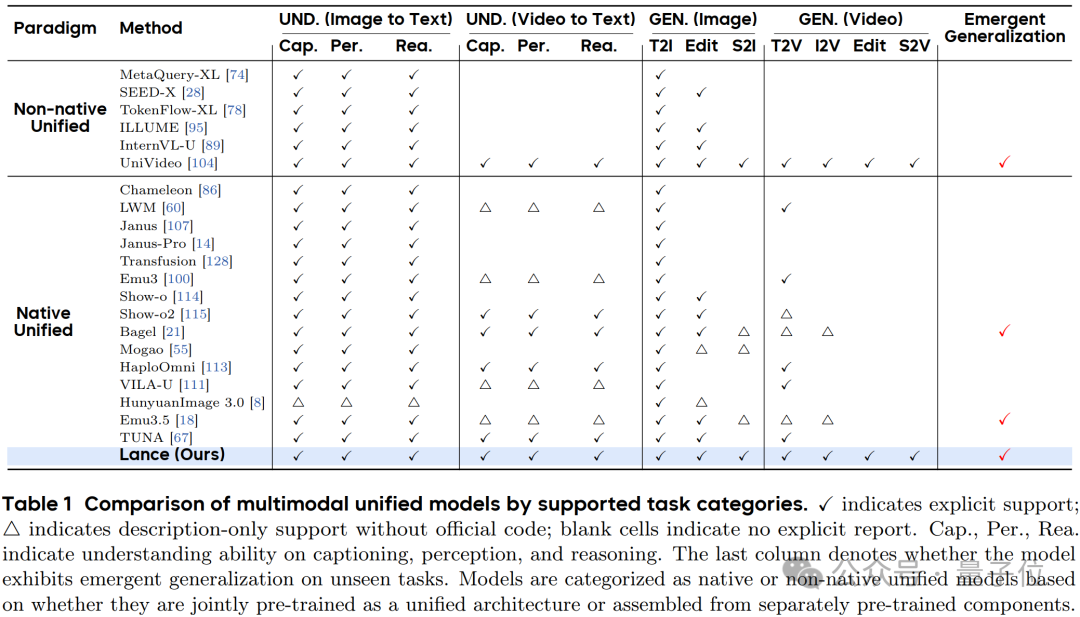
它把X2T、X2I、X2V三类任务统一起来:图像/视频到文本理解,文本到图像/视频生成,以及图像/视频到图像/视频编辑。
这样一来,模型不是只会“看”或者只会“画”,而是能在同一套上下文里处理不同模态和不同任务。
更有意思的是,团队观察到:任务覆盖越完整的统一模型,越容易出现emergent generalization,也就是跨任务的涌现泛化。
也就是说,多任务不是简单拼盘。任务之间可能真的会互相“喂经验”。
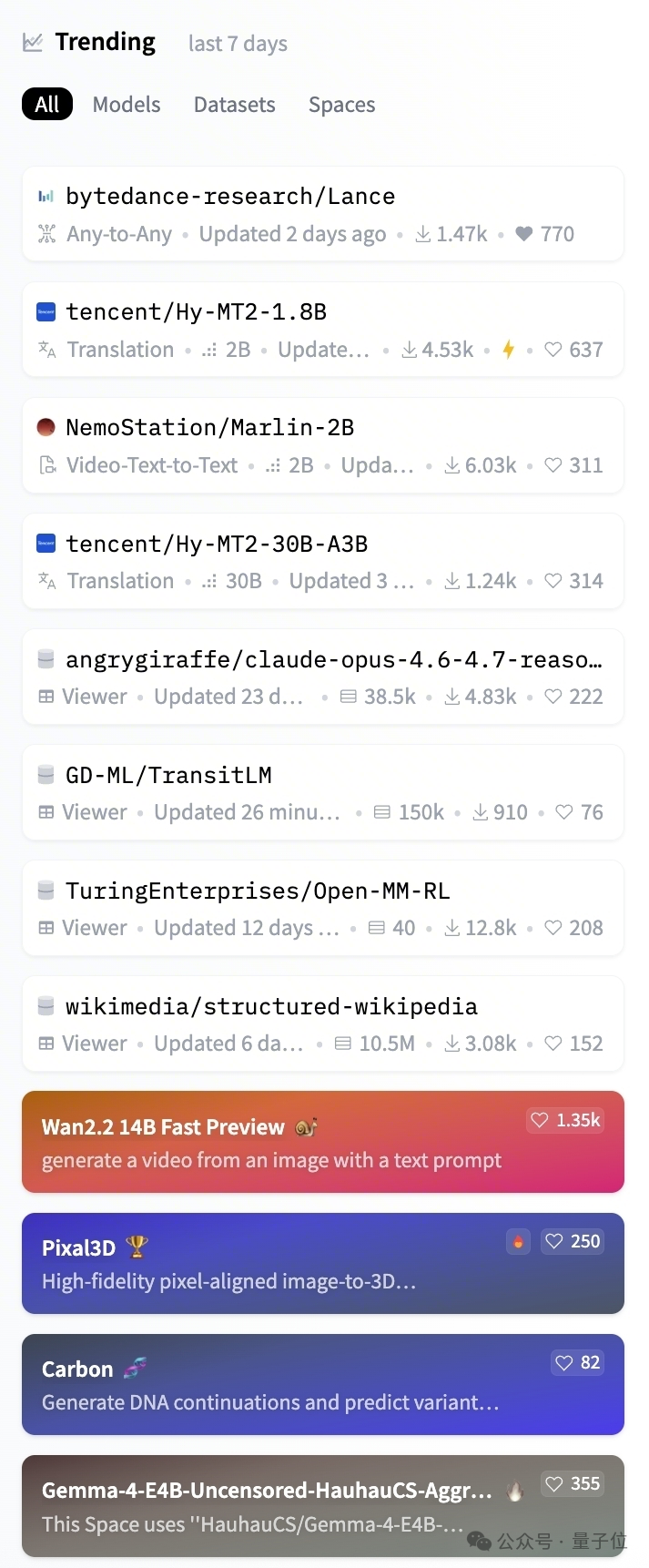
开源之后,Lance也很快冲上Hugging Face Trending第一。
这类榜单本身不是论文指标,但能说明一件事:社区对轻量级原生统一多模态模型的需求很直接。
毕竟,3B激活参数、同时覆盖图像/视频理解生成编辑,还开放模型权重和代码,这几个关键词放在一起,对研究者和开发者都相当有吸引力。
△Lance位列Hugging Face Trending第一
Lance覆盖的不是单点能力,而是一整组图像/视频任务:能看图、能看视频,能文生图、文生视频,也能按自然语言直接改图、改视频。
先上视频生成。
给它复杂文本指令,Lance 能生成具备自然运动、稳定时序一致性和清晰视觉细节的视频内容。
更有看头的是视频编辑。
它不是改一张关键帧糊弄过去,而是连续三轮改视频:
先把短直发改成法式卷发,再加红白花朵发箍,最后把背景换成湖边童话城堡。
难点在于,人物还得是同一个人,动作不能乱,前后帧也不能闪成PPT。
△source video