这家中国团队重新定义了计算机量子位
黄仁勋的GPU,解一道矩阵方程,要做上亿次乘法。
一家中国公司,一步就给解了,用的是模拟计算。
这家公司叫安纳智芯(Anatrix)。
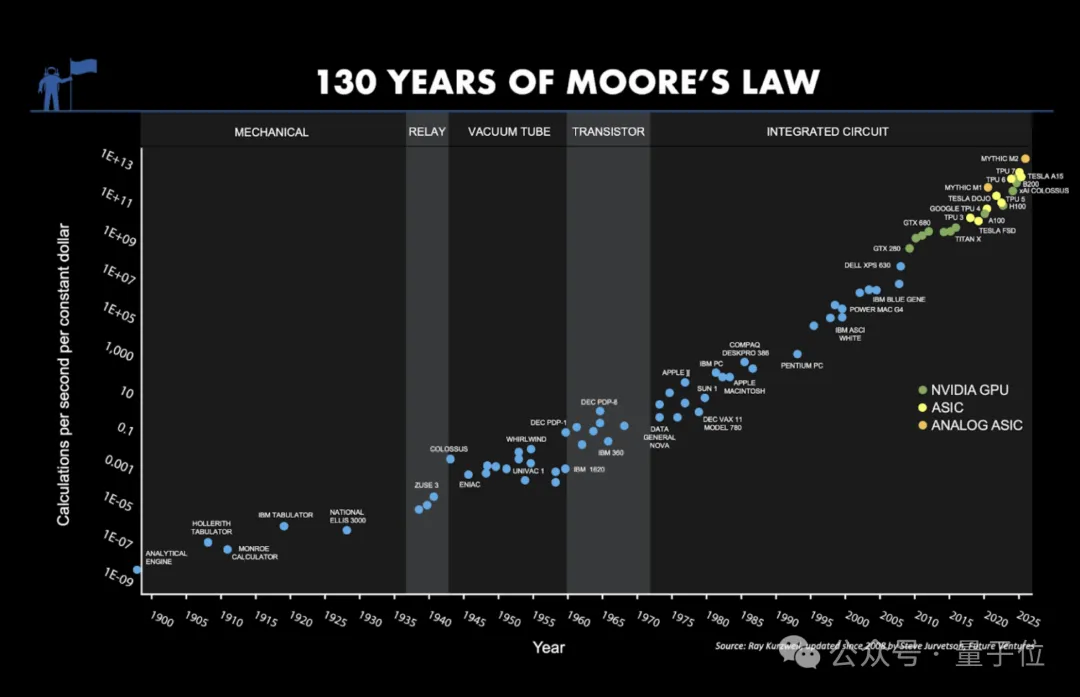
过去几年,整个AI行业几乎都在往同一个方向狂奔。GPU、TPU、LPU、CPU……大家卷来卷去,本质上卷的其实还是数字计算:
更多晶体管、更先进的制程、更大带宽、更高吞吐。
但最近,我们发现有一批公司,开始不按这个逻辑走了。
安纳就是其中之一。
他们选定的,是一个已经沉寂已久、但这两年又开始火热的方向:
这个概念听着新,其实一点都不新。
早在数字计算机大规模普及之前,人类就已经在研究模拟计算。最近很火的存算一体、光计算、量子计算、类脑芯片,往大了说,本质上也都属于这条路线。
之所以这两年重新被关注,一个很重要的原因在于:
模拟计算天然具备更高并行度、更低功耗,而且不像数字芯片那样高度依赖先进制程。
但它的问题也很明显,数字计算本质上处理的是0和1,只要能区分高低电平,误差就能被不断校正。
而传统模拟计算由于是直接用物理信号表示信息。电压、电流、电导这些量在传播过程中,容易积累噪声和漂移。
矩阵规模越大,误差放大得越夸张。
过去几十年,数字计算靠着摩尔定律一路狂飙,精度被不断“硬堆”上去;而模拟计算虽然理论上更高效,却始终困在精度问题里。
△图源:Unconventional AI
行业里甚至一直有一个很流行的观点:模拟计算很快、很省电,但不可信。精度,也因此成了模拟计算近几十年来最大的死结。
而安纳做的,就是把它解开。
模拟计算的精度,不再是问题了
过去近十年里,安纳的核心科学家一直在做同一件事——
把模拟计算的结果,做得足够可信。
去年,团队完成了精度媲美数字芯片水平的原理性验证,在模拟计算领域达到断档式领先,而今年,相关芯片目前已经进入流片阶段。
在技术路线上,安纳走的是一条非常典型、但也非常“硬核”的模拟计算路线:
基于存储器阵列,搭建非冯诺依曼架构芯片。
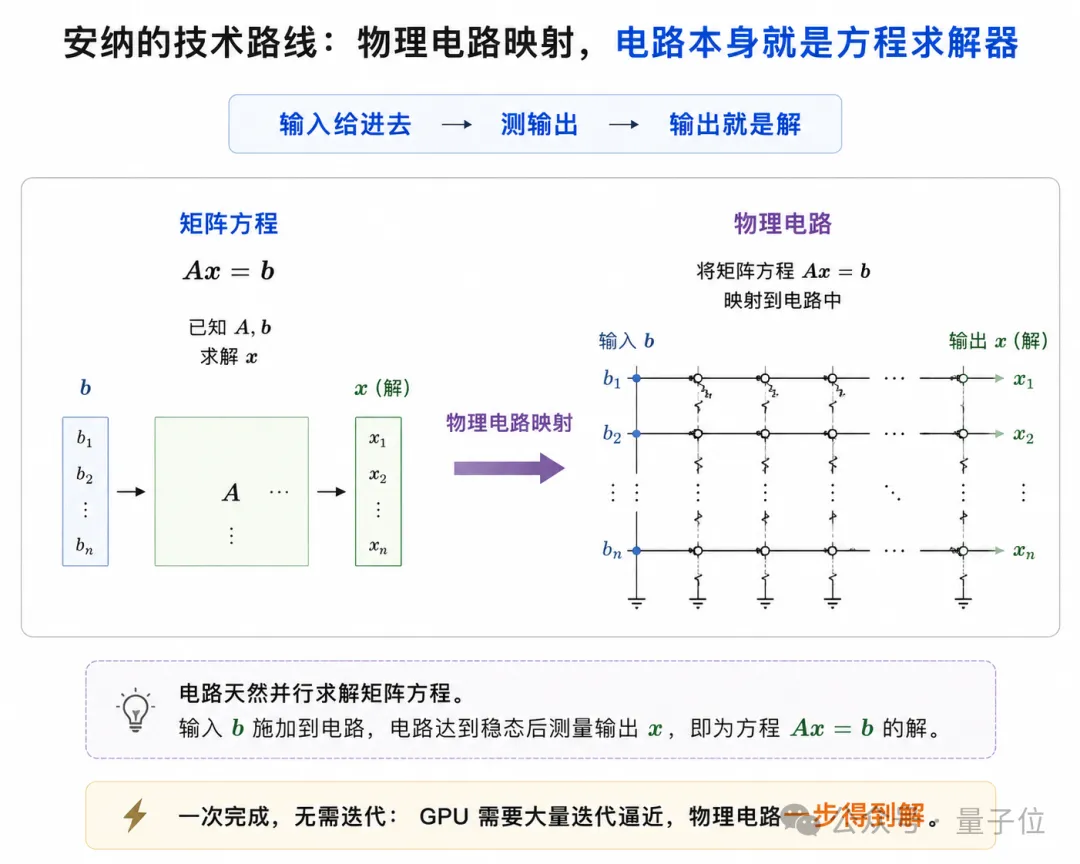
简单来说,就是把矩阵方程直接映射进物理电路,让电路本身成为方程求解器。
输入给进去,测输出,输出就是解。
也正因如此,那些GPU没办法直接求解、只能靠海量迭代逼近的矩阵方程,在安纳这里,可以一步完成,并保持精确。
(注:GPU拿到一个512×512的矩阵方程后,第一件事并不是“直接解”。它会先把问题拆开、转置、分解,再转化成海量矩阵乘加运算,通过一轮轮迭代慢慢逼近答案。整个过程,往往需要上亿次乘法。)
但有意思的是。
即便精度问题开始被解决,今天大多数模拟计算公司依然没有选择这条路。
像Unconventional AI、Normal Computing、EnCharge AI这些近两年最受关注的模拟计算创业公司,主打的依然是低功耗、存算一体或者特定场景加速。
(注:模拟计算正在重新获得资本市场关注。2025年底,主打低功耗模拟芯片的 Unconventional AI在种子轮便获得Lightspeed Venture Partners和a16z联合领投的4.75亿美元融资,估值接近45亿美元;专注热力学计算的Normal Computing于今年3月完成由三星领投的5000万美元融资;而存算一体公司EnCharge AI去年也完成了超过1亿美元的B轮融资。)
这背后其实对应着两种完全不同的研究哲学。
一种思路是接受模拟计算存在误差,在低精度条件下寻找“够用”的应用场景。
另一种思路,则是先把精度做到极限,再讨论效率和成本。
安纳属于后者。
在与量子位交流时,团队反复提到一个观点:
所有计算平台的发展历史,几乎都是先把精度做到天花板,再根据场景需求向下做取舍。
数字计算也是如此,AI模型训练里,先有FP32,再向下兼容FP16、INT8、INT4。
如果一开始就在低精度里寻找“够用”,很多能力可能永远没有机会被验证。
从上世纪80年代末的类脑计算,到后来的模拟神经网络,再到今天的存算一体,类似的故事其实已经反复出现过很多次。
所以,并不是追求精度这件事有争议,而是在过去很长时间里,由于模拟计算精度低是固有的,大家停留在这一层面,存在认知上的偏差,于是只能退而求其次。
而安纳率先完成了认知上的突破,他们真正想做的,就是把高精度模拟计算推向可用。
所有人都在做乘法,安纳想把“除法”补回来
除了对精度的态度,安纳和其他模拟计算公司的不同,还在于他们选了一个完全不一样的方向:
今天做模拟计算的公司,不管是存算一体、模拟CIM,还是各种类脑、光计算路线,几乎都在做矩阵乘法。
这其实很好理解,因为整个AI产业,本质上就是建立在矩阵乘法之上的。
一方面,GPU本身就极其擅长矩阵乘法;另一方面。大模型推理,也几乎全是矩阵乘法,所以
整个行业的思路都很自然——
既然模拟计算更省电、更并行,那就拿它去替代一部分GPU的矩阵乘法,但安纳并没有这么做,他们选择了更第一性的矩阵求逆。
那么,矩阵乘法和矩阵求逆有啥不一样呢?
简单来说,矩阵乘法,本质上是“知因求果”。权重已知、参数已知,乘起来、加起来,最后得到结果。
而矩阵求逆反过来。结果已经知道了,但中间真正的参数、权重、状态未知,你需要反过来把它求出来,从结果反推原因。
对应到大模型里也很好理解:矩阵乘法更多对应推理,而矩阵求逆则更接近训练。
因为训练本质上,就是已知输入和输出,再反过来寻找中间最合适的参数。
(注:今天主流数字计算的做法,依然是把原本需要直接求解的问题,转化成海量矩阵乘法,再通过不断迭代去逼近答案。)
事实上,矩阵求逆并不局限于大模型训练。现实世界里真正难的问题,很多其实都是“逆问题”。
比如,机器人为什么会摔倒?自动驾驶怎么从传感器数据里还原真实状态?通信系统怎么从混杂信号里恢复原始信息?
这些问题,底层都在做同一件事:从结果反推原因。