AI考满分,为什么还会出错?AI-lab学习笔记
训练集满分,不等于真实世界可靠。欠拟合是还没学会,过拟合是把旧题背得太死;正则化不是让 AI 少学,而是逼它从记住表面,走向看见结构。
训练集满分,不等于真实世界可靠。欠拟合是不够会,过拟合是太听话;正则化不是让 AI 少学一点,而是给学习加上约束,逼它在复杂世界里学到更能迁移的结构。
① 会做旧题不等于会做新题 → ② 过拟合是学错层次 → ③ L1/L2、Dropout、早停、数据增强 → ④ 大模型的过拟合悖论 → ⑤ 人的学习也需要正则化
开场:训练集满分,不等于真的会
我们总怕 AI 不够聪明。
可在训练模型时,工程师更常防的是另一件事:
AI 太会背。
它能把训练集做得很漂亮。
甚至把每一道旧题都做对。
但一换新题,一进真实世界,就开始出错。
这种错误,不是因为模型完全没学会。
有时是因为它把不该学的东西也学进去了。
太简单,连基本规律都抓不住,叫欠拟合。
太听话,把旧题纹路背得太死,叫过拟合。
中间那条窄路,才叫泛化。
这篇文章的主线,可以压成一对词:
记住,是把答案背下来。看见,是把结构认出来。
模型也好,人也好,能不能从旧例子走到新例子,差的就是这一步。
先看三个学生。
第一种,题做得太少。
公式看过,概念听过,例题跟着抄。
换一道题,就不会了。
这叫欠拟合。
他不是学偏了,而是还没学够,连表面规律都没有抓住。
第二种,题做得很多。
但他只刷同一类原题。
题干一变,数字一换,问法一绕,他就慌。
他不是没努力。
他努力得非常局部。
他记住的是这套卷子的纹路,不是题目背后的结构。
这叫过拟合。
记得越牢,离“看见”反而越远。
第三种,练习也做,但不沉迷原题。
基础题会做。
变式题也做。
做错以后看错因。
看完错因,把例子压成方法。
再拿方法去新题里验证。
他记住的东西更少,看见的东西更多。
这才叫泛化。
AI 学习也一样。
欠拟合是没记住,过拟合是只记住;真正的学习,是从记住表面,走到看见结构。
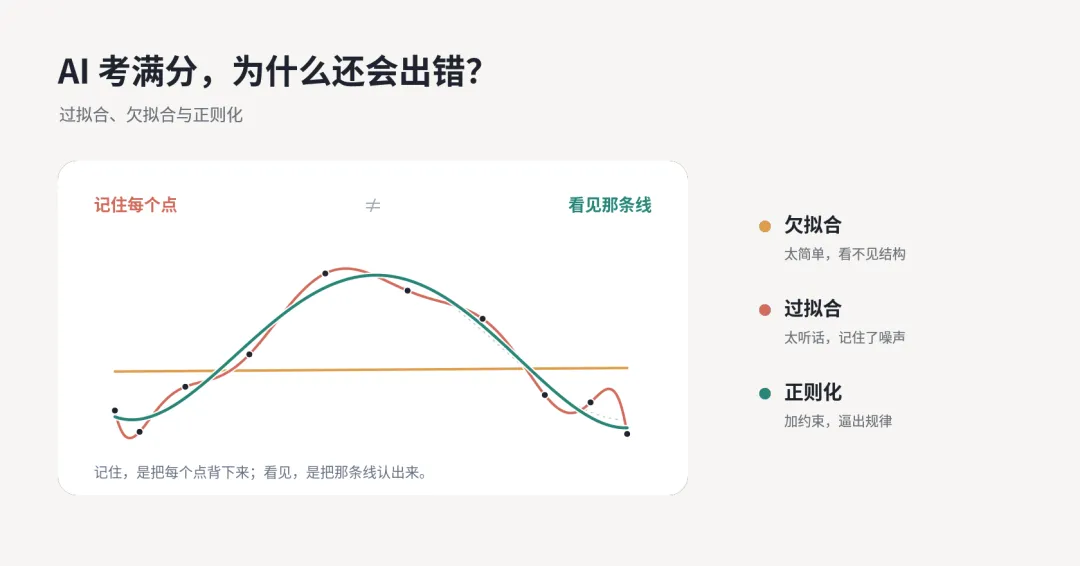
▲ 记住表面,不等于看见结构
一、把旧题全做对,不等于看见那条线
最经典的过拟合图像,是一堆训练点和三条曲线。
这张图不是在模拟某个具体行业里的真实变量关系。
它是机器学习教材里常见的一维示意图。
横轴只是某个输入特征。
纵轴是模型要预测的结果。
真实关系可能本来就是弯的,甚至会先升后降。
训练点是在这条真实关系附近采样出来的,但每个点都带一点噪声。
第一条曲线太简单。
它只画一条直线。
如果真实关系本来有弯曲,这条直线怎么调都抓不住。
这就是欠拟合。
模型太弱,连主要结构都看不见。
第二条曲线比较平滑。
它不穿过每一个训练点,但大体抓住了趋势。
这通常才是训练者想要的状态。
第三条曲线最“听话”。
它弯来弯去,真的穿过每一个训练点。
训练误差几乎为零。
看上去最厉害。
但它也最危险。
因为训练点里有噪声。
有些点偏高。
有些点偏低。
有些来自测量误差。
有些来自隐藏变量。
有些只是样本里的偶然波动。
如果模型为了贴住每一个点,把这些偶然因素也学进去,它就会在新房子上预测得很差。
这就是过拟合。
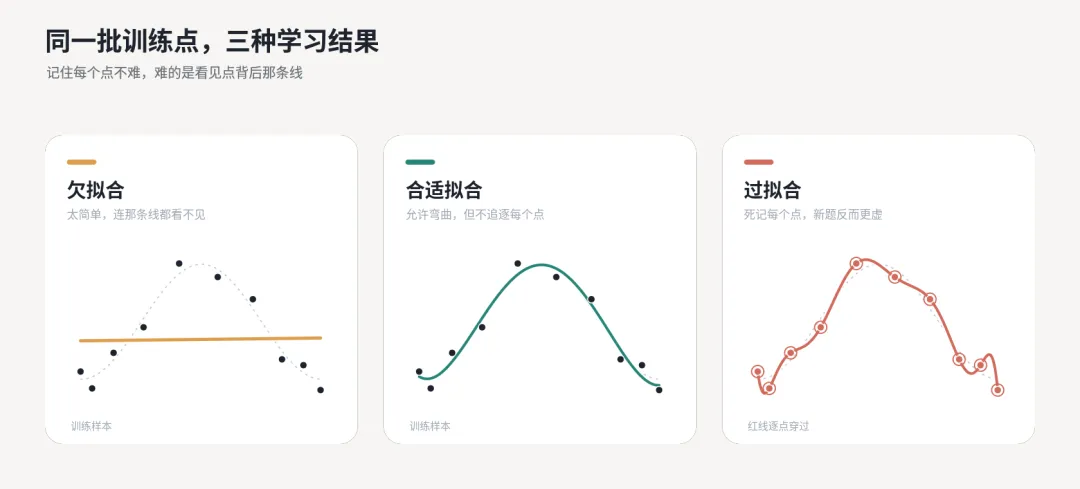
▲ 同一批训练点,三种学习结果
图里的红色过拟合曲线用的是插值方式生成。
在训练点上,它不是大概靠近,而是严格穿过。
危险也正在这里:
旧题越贴,新题未必越稳。
scikit-learn 官方文档里有一个经典例子:用多项式去拟合带噪声的余弦函数。
1 次多项式太简单,会欠拟合。
4 次多项式比较合适。
15 次多项式可以在训练点之间疯狂扭动,训练误差很低,但面对新样本反而更差。
它几乎就是机器学习入门课里“欠拟合 / 合适拟合 / 过拟合”的标准画面。
机器学习里最基础的一条经验由此而来:
不要只看训练集表现,要看验证集和测试集表现。
训练集像课堂练习。
验证集像模拟考试。
测试集像真正上场。
课堂练习都错,说明欠拟合。
课堂练习全对,模拟考试崩掉,说明过拟合。
真正会做题,不是把旧题答案记下来。
而是在新题里仍然看见同一个结构。
二、过拟合不是记得太多,而是记错了层次
过拟合常被说成:
模型学太多了。
这只说对了一半。
真正的问题不是“记得多”,而是“记错了层次”。
一份训练数据里,通常混着两种东西:
信号:可以迁移的规律 噪声:偶然、误差、偏差、巧合
学生刷题时,真正应该抓住的是:
这类题的结构是什么? 变量之间有什么关系? 为什么这个方法能用? 换个数字、换个问法,还能不能成立?