CMU新论文:让AI睡一觉新智元
都在卷上下文窗口,以为越大越强。CMU新论文发现:大模型缺的不是长上下文,是「睡一觉」。
这两天,一篇arXiv上的论文在Hacker News上引发热议。
这篇论文题目为《Language Models Need Sleep》(大模型需要睡觉),作者是来自CMU的Sangyun Lee、Giulia Fanti,以及马里兰大学的Sean McLeish和Tom Goldstein。
https://arxiv.org/pdf/2605.26099
它要解决的,是一个被整个行业卷疯了的问题:长上下文。
这两年,大模型的上下文窗口从几千token一路扩展到几十万乃至百万级。对前沿模型来说,百万级上下文已经不再罕见。
所有人都默认一条逻辑:窗口越大,模型记得越多,就越聪明。
但这篇论文偏要打破这个行业共识:模型答不对,不是记不住,而是「缺觉」了。
可能从一开始就卷错了方向
先说清楚现在主流大模型是怎么处理长文本的。
纯Transformer有个硬伤:注意力的计算量随上下文长度呈平方级增长,缓存占用则线性增长:塞得越多,越烧钱。
于是一些前沿长序列模型开始采用混合架构:注意力负责高保真地读取近期token,再穿插固定大小的「快速权重」(fast weights,可快速更新的轻量记忆)负责压缩存储活跃窗口之外的信息。
注意力+SSM(状态空间模型)的混合设计,如今在大规模前沿模型里已经很常见。这套设计的逻辑是:只要快速权重的存储容量够大,长上下文问题就解决了。
但论文实验结果,直接打脸了这个假设。
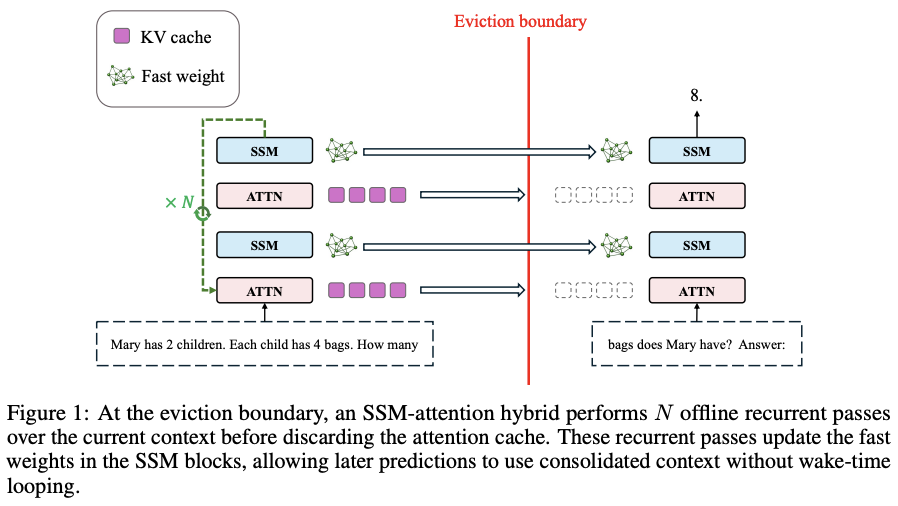
论文核心架构图。当上下文窗口被填满,模型在「驱逐边界」(Eviction boundary)前先做N次离线递归前向传播,反复更新SSM模块中的快速权重(Fast weight)。随后注意力缓存(KV cache)被丢弃,模型仅凭巩固后的快速权重,一次前向就答出「8」。
研究者设计了一组受控实验:在token预算相同、需要存储的信息量固定的前提下,只调一个变量:所需的推理深度。
结果发现,随着推理深度增加,普通的SSM-注意力混合模型性能持续下降。哪怕快速权重的容量明明是够的。
这意味着瓶颈并非「记忆容量」。真正缺的,是把已经被驱逐出缓存的上下文,转化成有用内部状态的那部分计算量。
能记住,窗口塞得下,不等于会推理。整个行业卷了两年的「窗口大小」,可能从一开始就找错了那个最关键的按钮。
模型怎么「睡」?
一次计算调度的重新分配
那论文的解法是什么?让模型「睡一觉」。
这听起来似乎有点玄乎,但背后的机制并不复杂,它的灵感来自生物学:
动物把短期记忆转为长期记忆的过程,被认为依赖海马体回放,尤其发生在睡眠期。睡眠期间动物对外界刺激没有反应,说明这件事的认知收益,值得它付出「断联」的代价。
模型的「睡眠机制」,则是照搬了这个调度逻辑。该机制的触发时机是:当上下文窗口被填满。这时模型不急着清空缓存,而是先进入睡眠模式。
在这段睡眠里,它对累积下来的全部上下文做N次离线递归前向传播,通过一个习得的局部规则,递归地更新SSM模块中的快速权重。
当然,和动物睡觉一样,这个阶段模型不接收任何外部输入token。睡醒之后,KV缓存被清空,模型带着更新过的快速权重继续干活。
这里的关键在于:额外的计算被整体挪到了睡眠阶段。只要这一步赶在缓存驱逐前、或在空闲期完成,模型醒着回答时就仍是一次标准前向传播,推理延迟不会增加。
这才是这套机制最聪明的地方:醒着的时候只管快答,真正费脑子的整理工作,留给睡觉。
HN上有人点出了这套机制的巧思:定期停下来,把近期上下文写进一个快速权重状态,这一步等于给了模型一段专门的「消化时间」,而不是让它在回答时硬扛。
他更看好E2E-TTT那套做法,这是一种更灵活的持续学习方案。
递归不只为回答
这里你可能会问:让模型「多想几步」,这不是早就有的思路吗?
的确,此前的Looped LM(循环语言模型)、测试时计算(test-time compute),走的都是同一条路:让模型在回答时多绕几圈。
论文里用到的Ouro 1.4B,本身就是一个这样的循环模型。Ouro并非这篇论文新发布的模型,而是此前已有的工作,它采用参数共享的循环架构,让同一批Transformer块反复作用,从而在潜在空间里做迭代计算。
这篇论文的创新之处在于它把「循环」这件事的作用,从输出端挪到了记忆端。
以往的循环模型,把递归计算花在「预测」上:回答问题时多想几步。这篇论文的核心洞见是:递归不仅能用于预测,也能用于记忆巩固。
把读过的token变成好用的记忆,这件事本身就不简单,一次传播未必做得完。就像梯度下降,也是靠一次次迭代,才慢慢把权重调好的。睡眠期多循环几次,就是多给模型几步,让它把上下文嚼得更透,压进快速权重里。
而且和以往的循环模型不同,这个模型回答时根本不用循环——该花的算力,睡觉时已经花完了。以前是回答时多想,现在是睡觉时多想。
不过在Hacker News上,也有人对「睡眠」这个说法提出相当尖锐的质疑:看不出这个方法在「睡眠」期间真的更新了模型权重。
被更新的,似乎只是SSM的状态:任何Mamba类模型每处理一个token都会做的常规更新。这位用户的判断是:论文只是优化了模型,让它在即将驱逐缓存时更充分地利用这个状态而已。
还有人翻出别的研究于它对比:端到端测试时训练(E2E-TTT),以及Letta团队的「睡眠时计算(sleep-time compute)」。焦点只有一个:去掉「睡眠」这个新包装,它到底比前人多走了几步?
Letta团队《睡眠时计算》论文提出,让模型在用户提问前离线「思考」上下文,预先算好可能用得上的量,从而压低测试时的计算开销。与本文同属「离线计算」路线,但是另一项独立研究。图片来源:https://arxiv.org/pdf/2504.13171
但换个角度看,这恰恰说明它踩在一条正在成形的路上。把部分计算从「回答时」前置到「空闲时」,并非这篇论文独创。
离线思考、算力前置,正在成为一条新路线。它和「回答时无限拉长思维链」走的是相反方向:一个把算力往前挪,一个把算力向后堆。
52%的提升从哪来
支撑这个机制的,是一堆扎实的数据。
论文的实验任务有三类:元胞自动机、Depo多跳图检索,以及GSM-Infinite数学推理。
这些任务有个共同点:普通Transformer和SSM-注意力混合模型,在上面都会失败。
第一个数据。在GSM-Infinite的六步运算子任务上,Ouro 1.4B用4次循环后,最终准确率从0.419提升到0.615;更难的八步运算,从0.210提升到0.272。