中国团队突破瓶颈:不加GPU,暴涨15%新智元
GPU一块没加,代码一行没改,仅靠重构组网架构就让推理集群多挤出15%的算力!中美大模型厂商不约而同押注同一个判断:网络,才是AI基础设施的下一个主战场。
Vibe Coding太火了!
几乎所有人都一夜之间进入了「说人话就写代码」的新纪元。
问题来了,如何打造更极致的算力支持?
有人开始对网络动刀了。
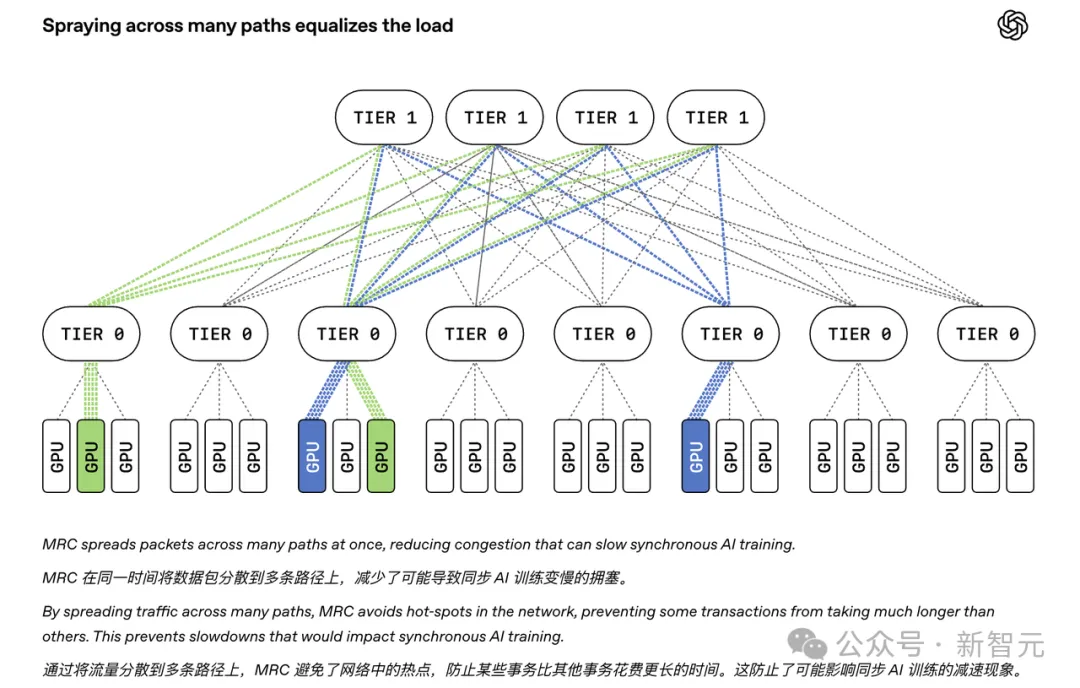
就在本月,OpenAI联合NVIDIA、AMD、Intel、Microsoft、Broadcom五大巨头发布了MRC(Multipath Reliable Connection)网络协议,已部署在其最大规模的GB200超算集群上。
国内这边,智谱联合驭驯网络与清华大学,在GLM-5.1线上生产集群中完成了新一代组网架构ZCube的规模化落地——GPU一块没加,服务器一台没换,代码一行没改,推理吞吐直接多了15%!
更加夸张的是,交换机和光模块的硬件成本还砍掉了三分之一。
而且集群规模越大,这个优势越猛。万卡级别的集群,光网络硬件就能省下2.1亿到6.4亿元。
提出并在真实生产环境中验证这项技术的,是中国团队。
ZCube架构发表于网络领域最顶级学术会议ACM SIGCOMM 2025,被评价为「significantly change the way we think about and understand networking」——显著改变整个行业对网络的认知方式。
地址:https://z.ai/blog/zcube
一月之间,国内外一个在协议层发力,一个在架构层动刀。殊途同归,指向同一个判断:网络,已经成为超大规模AI基础设施的下一个主战场。
ZCube:推翻二十年的「堆交换机」逻辑
过去几年,AI基础设施的军备竞赛只有一个维度:堆GPU。
更多、更快、更猛。
但当推理集群规模突破千卡、万卡,一个反直觉的现象开始出现——GPU的利用率不升反降。
原因很简单:大模型推理不是单兵作战,是协同打仗。
每处理一个用户请求,集群中的GPU需要高频、大量地互相传递中间数据(尤其是KV Cache)。
随着Prefill(处理输入)与Decode(生成输出)分离部署成为主流,数据在GPU之间的流向变得高度动态、不对称——有的链路挤满数据,有的链路空空如也。
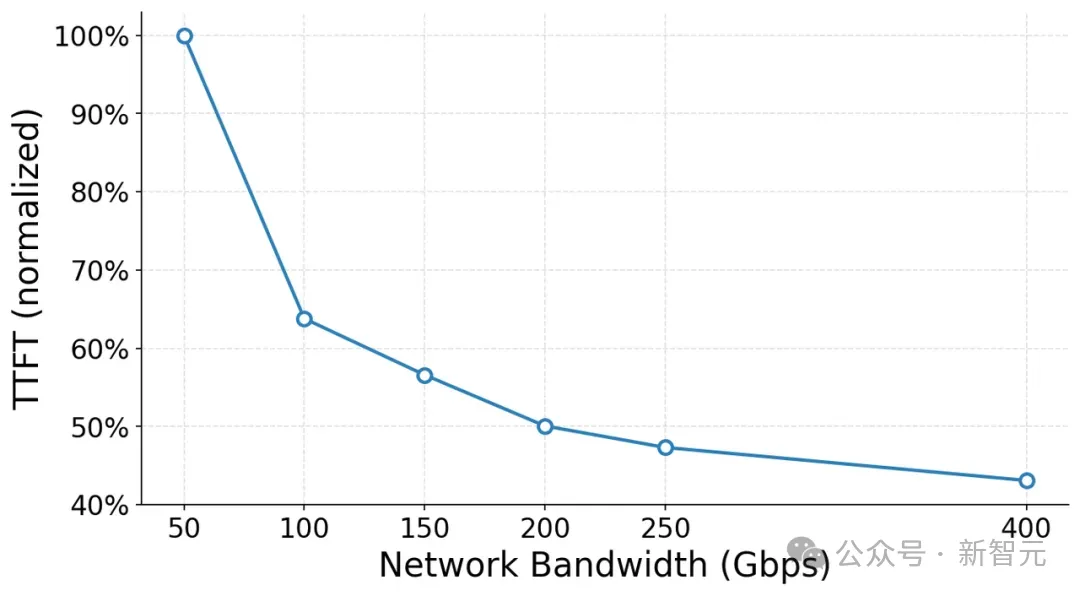
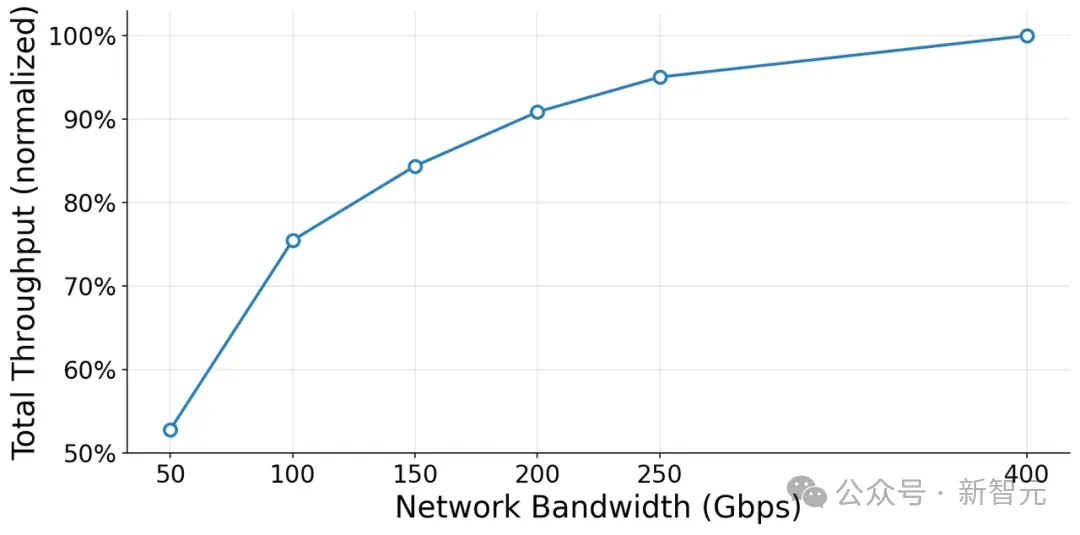
智谱的线上实测数据给出了量化证据:在一个32卡规模的推理服务上做控制变量实验,仅把网络带宽从100Gbps提升到200Gbps,推理吞吐就提升了约19%,首Token响应时延下降了约22%。
而且这个规律随着集群规模扩大,会越来越显著——GPU的性能天花板,其实是被网络「锁住」的。
过去二十多年,全球数据中心普遍采用Fat-Tree / Clos架构组网。
这套方案的核心思路非常朴素:多层交换机一层一层堆上去,规模不够就加层。
互联网流量时代,这套逻辑运行良好。AI训练集群里,也基本够用。
但大模型推理是一种全新的流量模式。
在PD分离部署场景中,Prefill节点和Decode节点之间需要频繁传递KV Cache,不同请求的长度千变万化,数据流向毫无规律。
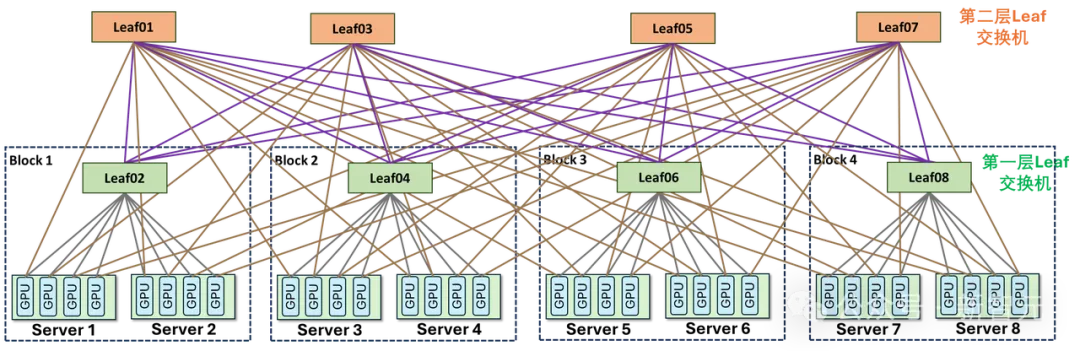
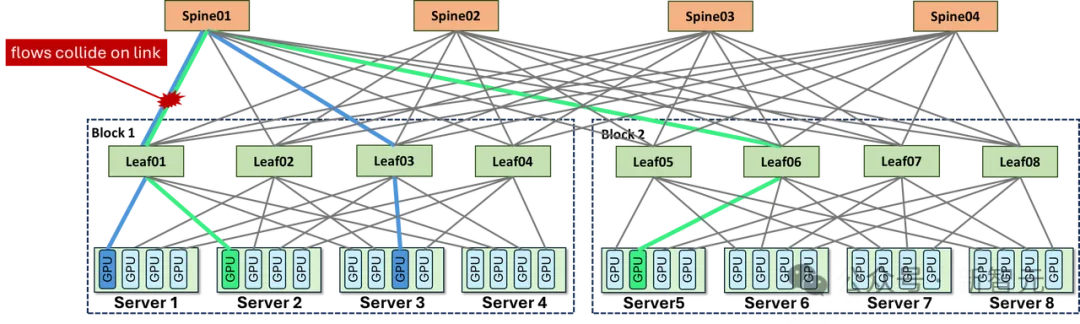
传统Clos架构面对这种流量时,一个结构性的死穴暴露了出来:流量会被拓扑关系天然地推向同几台交换机和同几条链路,形成热点堆积、队列反压、链路拥塞。
ROFT架构中,Leaf交换机之间容易出现流量负载不均
这是路网设计本身的问题。
ZCube的做法,简单说就是三个字:拆掉它。
设计的精妙之处在于:全网任意两张GPU之间,有且仅有一条最优路径。没有多路径选路的冲突,没有「车流挤到同一个路口」的结构性隐患。
拥塞不是被控制了,而是从架构层面大幅降低了结构性拥塞产生的概率。
打个比方:传统Clos是给一座已经堵死的城市装更多红绿灯;ZCube是重新规划了整张路网,让每辆车都有自己专属的最优路线——从源头上大幅减少了堵车的可能。
更值得关注的是网络直径。
ZCube的网络直径仅为2跳,全网GPU经过两台交换机即可互达,介于一层组网(1跳,规模受限)和传统二层组网(3跳,延迟高)之间——兼顾了低延迟与高扩展性。
硬件不换,代码不改,吞吐多15%
理论再漂亮,要看真刀真枪的生产数据。
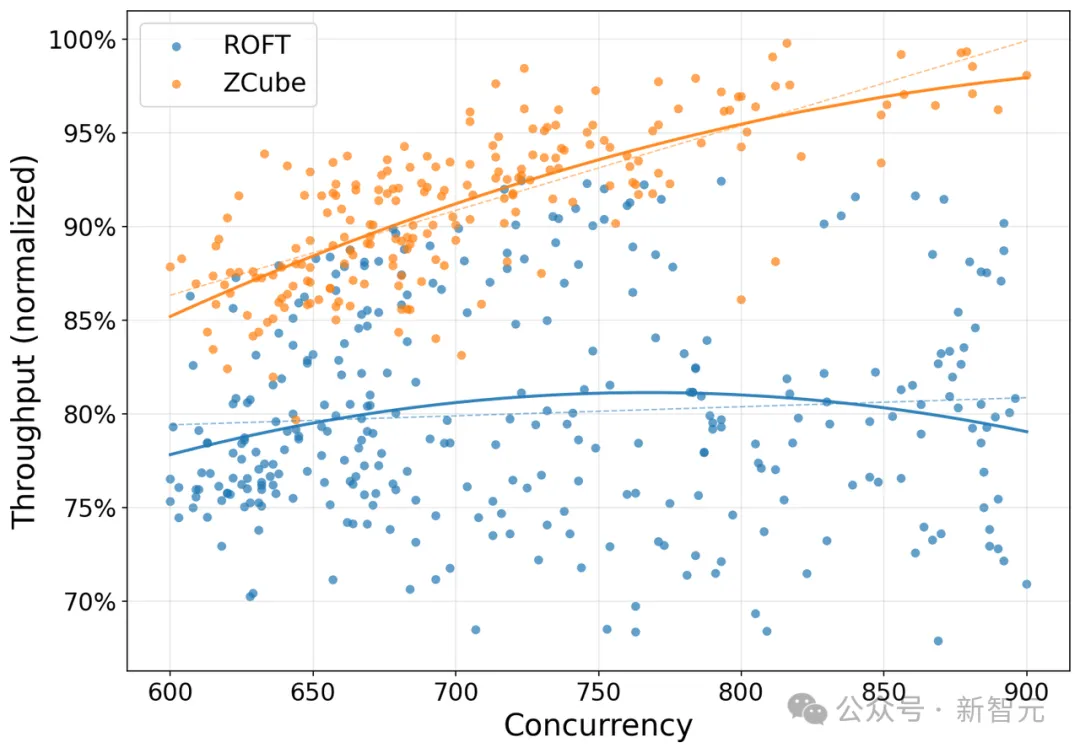
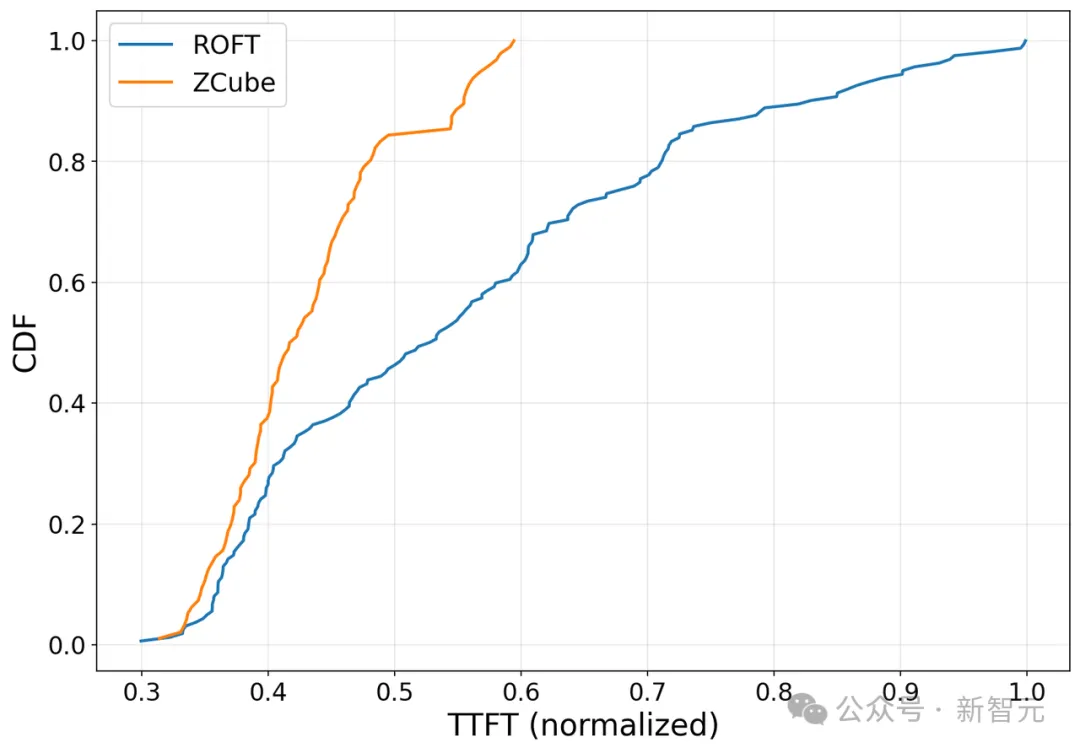
智谱在运行GLM-5.1 Coding推理服务的千卡集群中,将原本部署的ROFT(Rail Optimized Fat-Tree)网络架构直接升级为ZCube。
这次改造并不是简单的「换根网线」——ZCube取消了传统Clos的Spine层,原有的布线模式、IP编址策略、路由策略和交换机配置全部无法复用,需要从头设计。
驭驯网络团队为此开发了ZCube控制器、机房布局设计工具和连线正确性检测程序等一整套自动化工具,才在极短时间内完成了大规模生产集群的改造。
控制变量极其干净:GPU型号不变、软件栈不变、业务代码一行不改,唯一的区别就是组网架构。
结果是这样的:
GPU平均推理吞吐提升15%以上——同样的硬件,每秒多服务15%的用户请求
TTFT P99(首Token尾延迟)下降40.6%——用户等待的「」最坏情况「」大幅改善
交换机与光模块硬件成本减少三分之一——花更少的钱,反而跑得更快
在当前算力紧缺、推理需求持续暴增的背景下,同样一堆硬件凭空多挤出15%的产能,这哪里是「优化」,这是「存量资产的效率重估」!