AI时代,Python已经是新的“汇编语言”了王建硕
那天和任鑫在茶馆里坐着喝茶,开完会,他突然说"不如我们录个播客吧",于是我掏出两个手机,他掏出电脑,就开始录了。
先问一个问题:汇编语言是不是屎山代码?
我们都知道,任何 C 语言、Python 语言写出来的程序,到最后都要被编译成汇编语言(或者机器码)。一行 C 代码,可能要被编译成几十、几百行的汇编。一个库(library),编译完了可能就是几万、几十万行汇编。
现在的问题是:这一坨编译出来的汇编语言,是不是屎山代码?
按照"屎山"的定义——人不可维护的代码,看不懂、改不动、一改就到处是 bug——它百分之百是屎山。
你看都看不懂。改一行,一定满世界飞 bug。你压根不可能在那几万行汇编里精确改一处而不影响别的。
可是现实里有人觉得它是屎山吗?没有。
为什么没有?因为没有人需要去维护它。它不是给人看的,是给 CPU 看的。
一旦编译器诞生,人类就完全离开了汇编层。哪怕你是要改这段汇编,正确的做法也不是去汇编里改,而是去改它上一层——C 代码——重新编译。改完了 C,下面那几万行汇编自动跟着变。
所以严格来说:汇编不是"屎山",汇编是"已经退场了的源代码"。
人不需要去那里维护它。
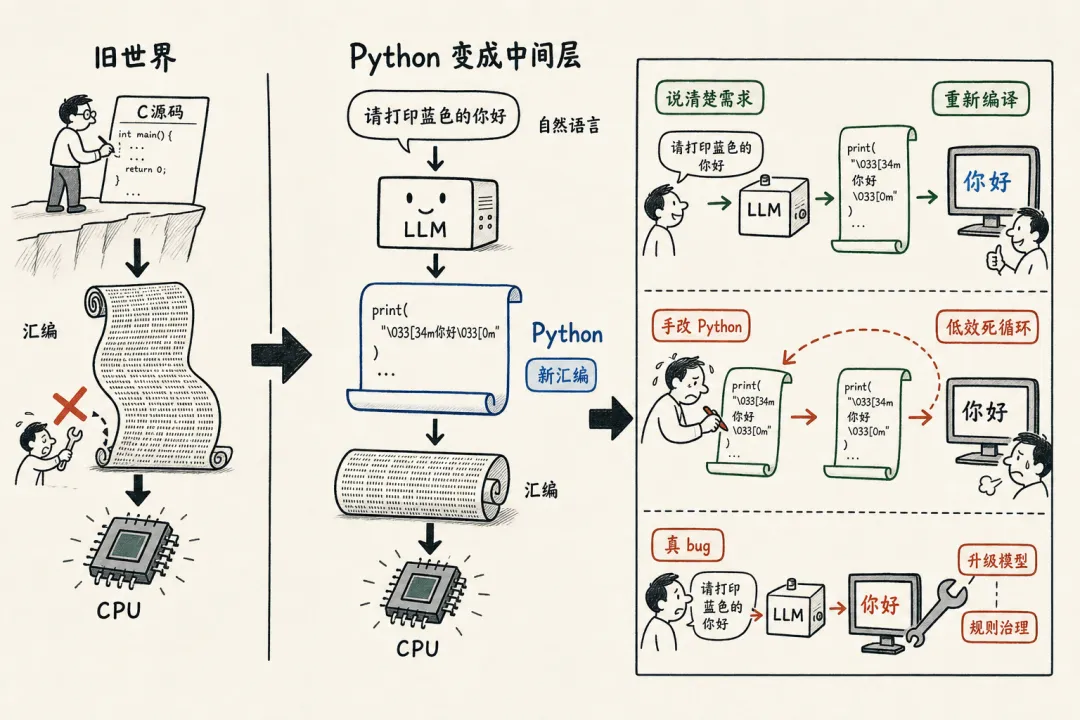
大语言模型,是一个新的编译器
它把你的自然语言(三句话、五句话、一段中文),编译成 Python(或者 JavaScript、或者别的什么语言)。Python 再被传统编译器编译成汇编,最终给 CPU 执行。
所以现在我们的"编译链",从一层变成了两层:
> 自然语言 →(LLM 编译)→ Python →(传统编译器编译)→ 汇编 → CPU
请注意发生了什么——Python 在这个链条里的位置,已经不再是"源代码"了。它的位置,就是当年汇编语言的位置:一个中间产物,一个编译出来的东西,一个理论上你不需要再亲手改的层。
如果这件事成立,那"屎山代码"这个抱怨就有点奇怪了。
你今天抱怨 AI 写出来的 Python 是屎山,逻辑上等价于五十年前一个汇编工程师抱怨 C 编译器产出的汇编是屎山。
不是它写错了,是你的脑子还停在旧的那一层。
"蓝色的你好":到底是不是 bug?
为了把这件事讲清楚,我举一个最家常的例子。
假设你写 Python 代码:
你没有指定颜色。
编译完了,运行起来,terminal 默认是黑底白字,屏幕上出现的就是一行白色的"你好"。
这是 bug 吗?
不是。编译器一丝不苟,毫无差错——你没说颜色,它就用默认值。
但这是你要的吗?不一定。可能你脑子里想的就是一行蓝色的"你好",只是你没把它写出来。
这时候你应该怎么做?
回到 Python 代码,加一行:
重新编译,蓝色就出来了。Bug fixed。
但请注意,这件 bug fixed 的事是在 Python 那一层完成的,不是在编译出来的汇编那一层。你从来没有打开过汇编文件去手工把白色改成蓝色。
把同一件事,搬到 AI 上
现在把这个例子原样搬到 AI 这一层。
你给 AI 写了一句 prompt:
它给你生成了一段 Python,运行出来是白色的"你好"。
你脑子里想的其实是蓝色的"你好"——但你没写。
接下来会发生什么?
我观察到一种非常普遍的反应——打开它生成的 Python,把里面的颜色参数手工改成蓝色,跑一遍,问题"解决"了。然后心里嘀咕一句:唉,这个大语言模型还是不太靠谱,我还得自己来。
朋友们,这正是当年那个汇编工程师在做的事情。
他没有去改源代码(也就是自然语言那一层),他跑去改了编译产物(Python)。表面上问题解决了,可是他完全错过了这件事的本质——
他的源代码,那句自然语言,本身就没说要蓝色。
AI 没有写错。AI 严格按照他写下的"请打印你好"给他编译了出来。是他自己脑子里的 intention(蓝色)和他实际写下来的指令(没说颜色),中间出现了错位。
正确的做法应该是:回到自然语言那一层,把它改成"请打印蓝色的你好",然后让 AI 重新编译一次。
这才是这个时代的"改 C 源代码"。
那真正的 bug 长什么样?
当然,AI 也是会有真 bug 的。
比如:你已经非常明确地写了"请打印蓝色的你好",结果它给你生成出来的 Python,明明白白写着打印红色的你好。
这才是 bug——编译器(也就是 LLM)没有忠实地把你的源代码翻成对应的产物。
但是请注意,就算是这种真 bug,你也不该自己去手工改它生成的 Python。
为什么?因为这件事有两个解法,都不该是"手改 Python"。
一个是等编译器升级。LLM 这种编译器,进化速度非常快,可能比当年 GCC 进化要快十倍、一百倍。这一版有 bug,下一版可能就修了。你今天花两个小时手改 Python,下一版编译器一出来,你这两小时连复利都没攒下。
另一个是在编译器外面套一层"治理"。比如系统级的 hook,比如 skill,比如 prompt 模板,让它每次碰到"颜色"就强制走某条规则。说穿了,这就是在丰富这个新编译器的预处理和后处理流程。
哪怕是 C 编译器,从最早到现在,也是从一个简单的编译器,长成了一整套工作流——预处理器、链接器、各种 library、各种优化选项。LLM 这一层只是刚刚开始而已。
唯一不应该做的,就是直接去改它编译出来的那个 Python。
在编译产物上改,是低效的,也没有前途
假设有一个汇编工程师,每次 C 编译器编出来的汇编里有一处他不满意,他都跑去手工改那一行汇编。
可以吗?可以。但是这件事不可持续。
第一是低效。下次你重新编译 C,这一行又会被覆盖回去,你白改了。
第二是没有前途——整个软件工程行业,是奔着"人离汇编越来越远"在跑的,你偏偏要往回跑。
还有一层更隐蔽的:你越是在汇编层挣扎,越不会去优化你的 C 代码本身;越不去优化 C 代码,给编译器的输入就越糟糕;输入越糟糕,你就越要回头改汇编。死循环。
今天我们对待 AI 写出来的代码,差不多就是这个错觉的翻版。
每一次你打开 AI 生成的 Python 去手工改某一行——你都在错过一次升级"你脑子里那一层源代码"的机会。
说到底,不是车坏了,是不会用。
AI 写出来的"白色的你好"不是 bug,是因为我们还没有习惯告诉它"我要蓝色"。
旧的工程师习惯告诉计算机"你具体做这做那"——这是过程式的,写 Python。新的工程师需要学会告诉计算机"我要的最终样子是什么"——这是声明式的,写自然语言。
这两种习惯之间,需要换一个脑子。换脑子是会疼的,会让人下意识地退回去,退回到那个"我直接改 Python 心里踏实"的旧世界。
但奇迹永远来自那个迅速学会用枪的人,不是那个继续把武功练得更硬、去和枪较劲的人。
下次你打开 AI 写的 Python 想去手改之前,请停一下,问自己一句:
我有没有,在上一层,把我真正想要的事情,说清楚?
如果没有,先回去说清楚。
如果说清楚了,AI 还是给你红色,那才是它的 bug——那种 bug,让编译器去修,不要让自己去修。