GPT-5.5用「最快芯片」,Claude慌了新智元
120B模型飙到2000 token/秒,CFO更放话已在跑GPT-5.5!Cerebras 560亿美元IPO首日暴涨68%,但SemiAnalysis万字拆解直指死穴。
SemiAnalysis,硅谷最硬核的芯片分析机构,4月份光是AI工具的订阅费就烧到了年化1000万美元。
其中80%花在同一个地方,Anthropic的Opus 4.6 fast模式。
它比标准模式贵6倍,但token输出速度快2.5倍!
然后Opus 4.7来了。更聪明,跑分全面碾压上一代,但工程师集体拒绝升级。
理由只有一个,4.7没有fast模式。
他们宁可用更笨的模型,也要更快的token!
2000 token/秒,怎么来的
OpenAI今年2月甩出了GPT-5.3-Codex-Spark。
名字挂着GPT-5.3的招牌,但底层是一个从完整版GPT-5.3 Codex蒸馏出来的小模型,参数量只有原版的十分之一,120B。
虽然是用智能换来的,但速度确实夸张到离谱——2000 token/秒。
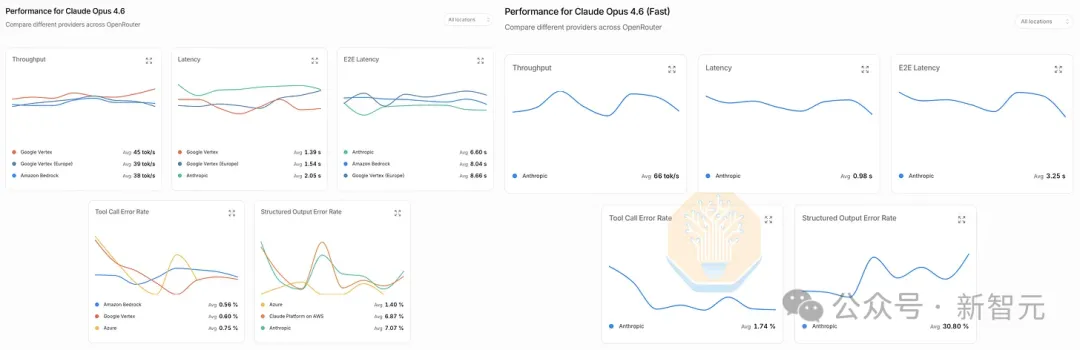
作为对比,Anthropic最快的Opus 4.6 fast大约70-100 token/秒,GPT-5系列在英伟达GPU上是大约130 token/秒。
而Codex-Spark一脚油门踩到了一个数量级开外。
让它跑这么快的,正是Cerebras的WSE-3,一块餐盘大小的晶圆级芯片。
这件事直接引爆了一笔246亿美元的合同,也把Cerebras一路推进了纳斯达克。5月14日首日暴涨68%,2026年至今最大科技IPO。
但Cerebras CFO Bob Komin说,这还只是开胃菜。
IPO前夜,他在采访中亮了一张没人预料到的牌——
我们服务所有模型,对模型大小没有限制。今天,我们正在跑万亿参数的模型。我们正在跑OpenAI内部的GPT-5.4和GPT-5.5。
如果这是真的,Cerebras就不只是一个「小模型快跑」的玩家了,IPO当天的疯狂涨幅立刻站得住脚。
但SemiAnalysis偏偏在同一周甩出了一篇两万字的技术拆解报告,直接把这个故事撕开了一道口子。
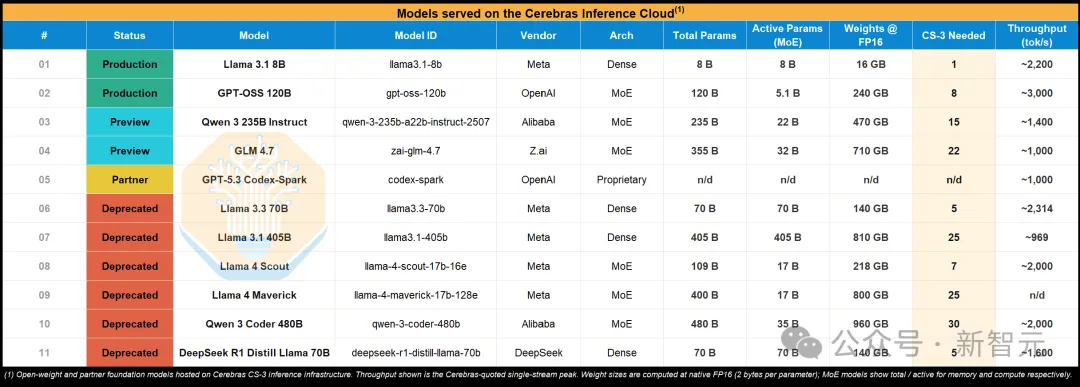
Cerebras公开云上,最大的生产模型是GPT-OSS,总参数120B;预览模型最大355B。曾经上过的Llama 70B和405B,后来也被悄悄下了架。
2025年最火,但体量也更大的开源模型(比如DeepSeek),从头到尾就没出现在Cerebras Cloud上。
CFO口中的那个数字,目前只存在于「OpenAI内部」,外界无法验证。
要搞清楚这中间的裂缝有多大,得先看看这块晶圆到底是怎么回事。
一整块硅的赌注
半导体行业干了50年的事情就是切硅片。
一整块晶圆刻出几十颗芯片,切割,封装,各干各的。英伟达的B300已经把单颗芯片撑到了858平方毫米,基本上是光刻的极限了。
相比之下,Cerebras却反其道而行——它不切。
整块晶圆就是一颗芯片。
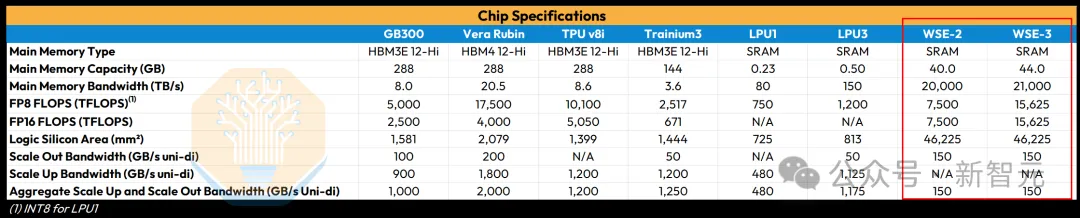
46,225平方毫米,比英伟达的GPU大58倍,大约一个餐盘的尺寸。上面集成了4万亿个晶体管、90万个计算核心,和44GB的SRAM内存。
重点来了,SRAM。
GPU用的是HBM(高带宽内存),容量大但速度相对慢。一块B300配了288GB的HBM,带宽在TB/秒级别。
WSE-3只有44GB的SRAM,但内存带宽高达21PB/秒。
Cerebras速度碾压的秘密就在这里。
SRAM带宽大到解码时几乎可以把全部计算核心喂饱。GPU的计算核心只能饿着等内存。
而推理的瓶颈,正是解码。
模型一个token一个token往外吐的时候,每吐一个就要把全部权重从内存里读一遍。带宽越高,读得越快,token出得越快。
SemiAnalysis做了一个很直观的对比。