一个加号拯救了深度学习——何恺明de一个简单的实验AI-lab学习笔记
56 层的网络比 20 层更差——不是过拟合,是训练误差也更高。然后何恺明加了一个加号:y = F(x) + x。就这一个加号,让网络从 20 层堆到 1000 层,让 GPT 成为可能。
从一个反直觉的实验说起
2015 年,微软亚洲研究院的何恺明做了一个简单的实验:把一个图像识别网络从 20 层加深到 56 层。
直觉上,更深的网络应该更好——56 层网络至少不应该比 20 层差,因为它完全可以在前 20 层学完之后,让剩下的 36 层什么都不做(学成恒等映射 f(x) = x)。
但实验结果令人震惊:
CIFAR-10 数据集上的训练误差:
20 层网络: ~5%
56 层网络: ~8% ← 更深,但更差!
不是过拟合。 过拟合是训练误差低、测试误差高。但这里训练误差也更高——56 层网络连训练数据都拟合不好。
更深的网络,反而更笨了。
这个现象被称为退化问题(degradation problem)。它说明的不是模型容量的问题,而是优化的问题——让 36 层网络学会"什么都不做",对标准的梯度下降来说,竟然做不到。
"Deeper neural networks are more difficult to train."
— He, K. et al. (2015). Deep Residual Learning for Image Recognition. CVPR 2016 Best Paper.
这个发现把深度学习推到了一个十字路口:如果更深 ≠ 更好,那深度学习的"深"字还有意义吗?
然后何恺明做了一件看似微不足道的事——他在网络中加了一个加号。
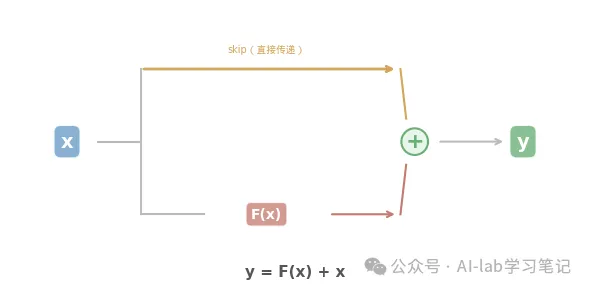
一、一个加号改变一切:y = F(x) + x
传统网络 vs 残差网络
传统的深度网络中,每一层学习一个变换 H(x):
输入 x → [第 1 层] → H₁(x) → [第 2 层] → H₂(H₁(x)) → ...
每一层的任务:从输入 x 直接学到输出 H(x)
何恺明的改变只有一步:不让网络直接学 H(x),而是让它学 F(x) = H(x) - x,然后把 x 加回来。
就这一个改变。y = F(x) + x。
▲ 输入 x 兵分两路:一路经过网络层 F(x),一路直接跳过。两路在加号处汇合。即使 F(x) 学不好,x 也能完整传递
💡 关于代码示例: 本文引用的 microgpt 和 nanoGPT 是 Karpathy 开源的教学项目——前者 200 行零依赖,后者用 PyTorch。如果你对代码不熟悉,可以先跳过代码块,专注于文字和图解——后续我会出视频逐行拆解这些代码。
在 nanoGPT 中,残差连接只有两行——可能是整个 Transformer 中最短但最关键的代码:
# nanoGPT 中的 Transformer Block(model.py 第 103-106 行)
def forward(self, x):
x = x + self.attn(self.ln_1(x)) # Attention 的输出 + 原始输入
x = x + self.mlp(self.ln_2(x)) # MLP 的输出 + 原始输入
return x
在 microgpt 中看得更清楚——因为它是纯 Python,没有任何抽象:
# microgpt 中的残差连接(第 116-141 行)
for li in range(n_layer):
# 1) Attention block
x_residual = x # ← 先把 x 存起来
x = rmsnorm(x)
# ... 一堆 Attention 计算 ...
x = linear(x_attn, state_dict[f'layer{li}.attn_wo'])
x = [a + b for a, b in zip(x, x_residual)] # ← 加回来!
# 2) MLP block
x_residual = x # ← 再存一次
x = rmsnorm(x)
x = linear(x, state_dict[f'layer{li}.mlp_fc1'])
x = [xi.relu() for xi in x]
x = linear(x, state_dict[f'layer{li}.mlp_fc2'])
x = [a + b for a, b in zip(x, x_residual)] # ← 又加回来!
每个 Transformer 层做了两次残差连接:一次在 Attention 之后,一次在 MLP 之后。
GPT-2 有 12 层,每层 2 次 → 24 次加法。
GPT-3 有 96 层,每层 2 次 → 192 次加法。
这 192 次加法,是 GPT-3 能工作的根基。
一句话记住: 残差连接 = 输出加上输入。y = F(x) + x。不是让网络从头学整个变换,而是让它只学变化量。这一个加号,让网络从 20 层扩展到了 1000 层。
二、为什么学"变化"比学"全部"更容易?
恒等映射的困境
回到退化问题。理论上,56 层网络可以包含一个 20 层的解——只要让多余的 36 层学成恒等映射 f(x) = x。
但在实践中,让一堆非线性层学会"什么都不做",出奇地困难。
想象一下:一个层有几百个参数(权重和偏置),经过矩阵乘法和 ReLU 激活函数。要让这些参数恰好组合出 f(x) = x,需要权重矩阵精确等于单位矩阵,偏置精确等于零。虽然这在数学上是可能的,但梯度下降很难找到这个解——因为损失函数的地形(loss landscape)中,恒等映射的位置不是一个容易到达的"谷底"。
残差让"什么都不做"变成默认选项
加上残差连接之后,情况完全反转了。
传统网络想"什么都不做":
需要学 H(x) = x → 困难(要让一堆非线性层精确输出 x)
残差网络想"什么都不做":
需要学 F(x) = 0 → 容易(只需要把权重推向零)
"If the identity mapping f(x) = x is the desired underlying mapping, the residual mapping amounts to g(x) = 0 and it is thus easier to learn: we only need to push the weights and biases of the upper weight layer within the dotted-line box to zero."
— d2l.ai, Chapter: ResNet
残差连接把"什么都不做"从一个困难的优化目标,变成了网络的默认状态。
每一层的真正任务变成了:在保留原始信息的基础上,决定要"增加"什么。 如果这一层没有什么有用的可以贡献——没关系,F(x) ≈ 0,输出 ≈ 输入,信息无损传递。