谷歌造出AI数学家,48%碾压全场新智元
谷歌DeepMind今日官宣推出「AI co-mathematician」多智能体系统,在FrontierMath Tier 4自主模式下斩获48%正确率。牛津教授借助该系统攻克Kourovka Notebook长期开放问题,AI进化为数学家的真正研究搭档。
人类数学家,终于等来了自己的「超级队友」!
就在刚刚,谷歌云首席科学家、DeepMind研究副总裁Pushmeet Kohli重磅官宣AI co-mathematician——一套专为数学研究设计的多智能体协作系统。
这玩意儿多猛?
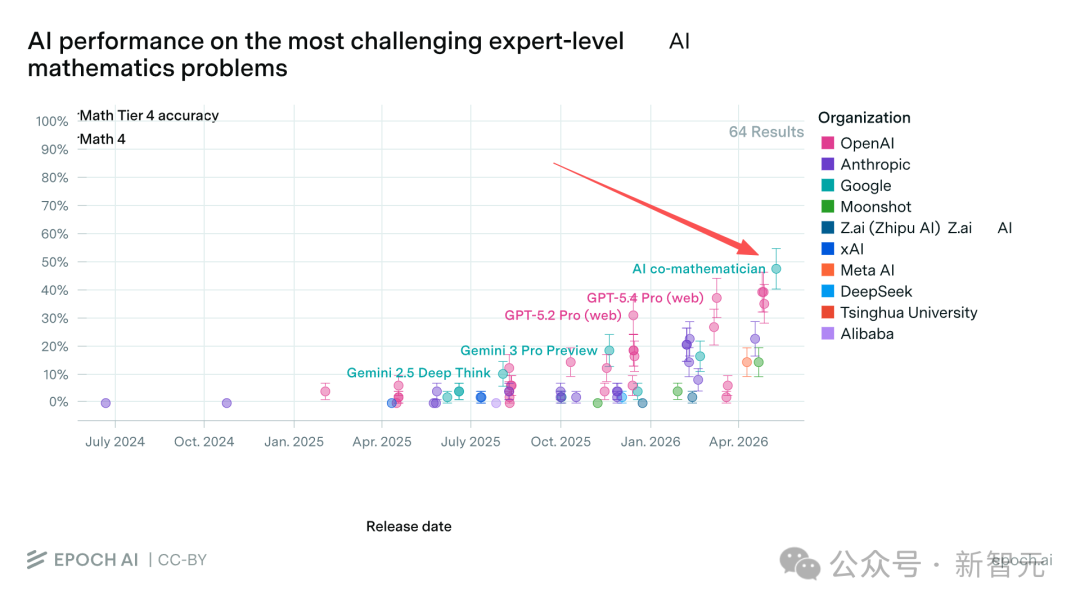
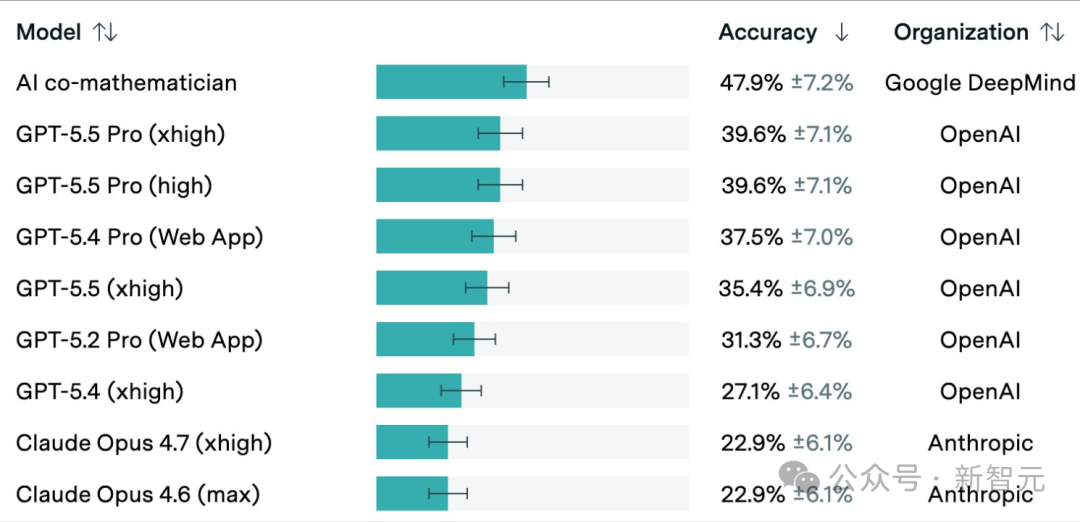
在Epoch AI组织的FrontierMath Tier 4基准测试中(50道由教授和博后专门设计的「短期科研项目」级别超难题,专业数学家也得花上数天乃至数周),AI co-mathematician在自主模式下拿下48%的正确率,解决了48道非公开题中的23道。
刷新所有AI系统的历史最高纪录!
作为对比,它底层用的Gemini 3.1 Pro基座模型,独立作战只能拿到19%。从19%到48%,整整跃升了29个百分点。
更狠的是,它还超越了GPT-5.5 Pro的39.6%和Claude Opus 4.7的22.9%。
其中有3道题,是此前所有被测系统都没能攻克的。
Pushmeet Kohli在社交媒体上兴奋地写道:数学的未来,是数学家和AI智能体一起工作。
不是更聪明的模型
而是更聪明的「编排」
AI co-mathematician最有意思的地方在于:它的突破不是靠换一个更大的模型,而是靠系统设计。
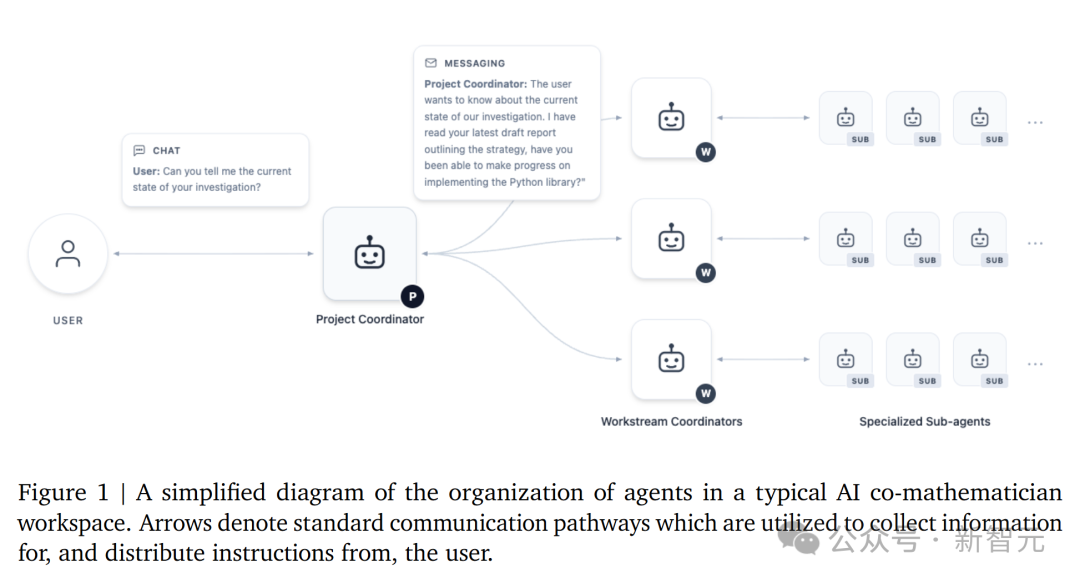
整个系统采用了一种层级式多智能体架构:一个「项目协调员」智能体坐镇中央,负责把数学问题拆解成多个并行的「工作流」,再分派给不同的专项子智能体去执行。
这些子智能体各有专长——有的负责文献检索,有的负责计算探索,有的负责证明推导,还有的专门负责「挑毛病」。
没错,这里有一个专职的审稿人智能体。
每条证明路径写出来之后,都必须经过审稿人的交叉审查,发现逻辑漏洞就打回重做。
这种「强制审查循环」机制,直接把传统LLM最头疼的「自信地胡说八道」问题压了下去。
更关键的是,整个工作台是异步、有状态的。
它能记住之前尝试过哪些失败的假设,能追踪每一条探索分支的进展,还能输出带有边注和内部引用的工作论文。
就像是一个能跟你「泡」在一个项目里、持续数天迭代的研究伙伴。
DeepMind论文中举了几个让人印象深刻的案例:
▪︎面对一道几何铺砖问题时,系统把核心挑战归约为布尔可满足性(SAT)问题,然后用PySAT库求解;
▪︎在一道表示论题目中,它通过文献搜索工具精准检索到特定定理的精确表述,而基线模型只能凭「大概印象」答题,结果条件都没对上;
▪︎在组合数学题中,它把理论推导和计算验证拆成两条独立工作流,让审稿人智能体在最终拼装前就揪出了逻辑错误。
牛津教授实战:攻克60年老本子里的开放问题
数字好看归好看,但AI到底能不能在真正的数学前沿派上用场?
牛津大学数学家Marc Lackenby的亲身经历给出了最有说服力的回答。
他用AI co-mathematician研究了群论中的一个经典开放问题——Kourovka Notebook第21.10题。
这本「笔记本」可不是普通笔记,而是群论领域从1965年传承至今、汇集了全世界未解难题的「圣经级」问题集。
Lackenby把问题直接输入系统后,AI co-mathematician自动创建了两条并行工作流:一条尝试证明,一条尝试反证。
第一条路径很快返回了一个「证明」,但系统自己的审稿人智能体随即发现了其中的漏洞,标记为不正确。
关键转折来了:Lackenby看到被打回的证明和审稿人指出的缺陷后,突然意识到——自己作为领域专家,恰好知道怎么填补这个缺口。
于是他补上了关键的一步,问题迎刃而解。
这个故事的精髓在于,人和AI谁都没法独自在这个速度下完成这件事。
AI提供了证明策略和计算探索的「暴力搜索」,审稿人智能体及时发现了错误,而人类数学家的深层直觉完成了最后的临门一脚。