万亿字节,LLM 如何把互联网装进一个模型?AI-lab学习笔记
你这辈子大概会读 5000 万个字。GPT-4 在训练时"读"过的量,相当于你读两万辈子。然后,它把这些内容"装"进了一块硬盘里——不仅能回忆大部分内容,还能自己写出从未存在过的文章。
这是压缩吗?是理解吗?如果互联网消失了,能靠 LLM 复原吗?为什么微调只需万分之一的数据就能改变模型的"性格"?
① 你读一辈子的书,GPT 几秒就读完了 → ② 这不是 ZIP 压缩 → ③ 死记硬背 vs 举一反三 → ④ 记忆与泛化的共生 → ⑤ 微调与对齐 → ⑥ 表面对齐假说 → ⑦ 全景总结
一、你读一辈子的书,GPT 几秒就读完了
1.1 一个人的一生,有多少"语言量"?
在谈 LLM 之前,我们先看看自己。
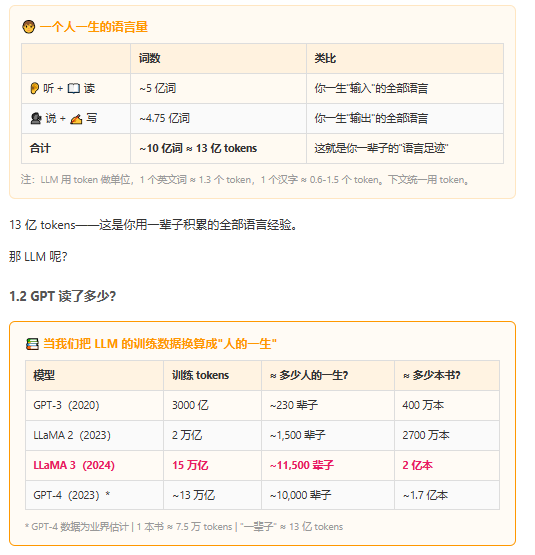
心理学家 Mehl 等人 2007 年在 Science 上发表了一项经典研究:一个人平均每天说 16,000 个词。一辈子说的话加起来,大约 4.7 亿个词。
那阅读呢?按每天阅读半小时、每分钟 250 词估算,一辈子大约读 5000 万个词——相当于 625 本书。再加上你写过的所有文字——邮件、聊天记录、朋友圈——一生大约 500 万个词。
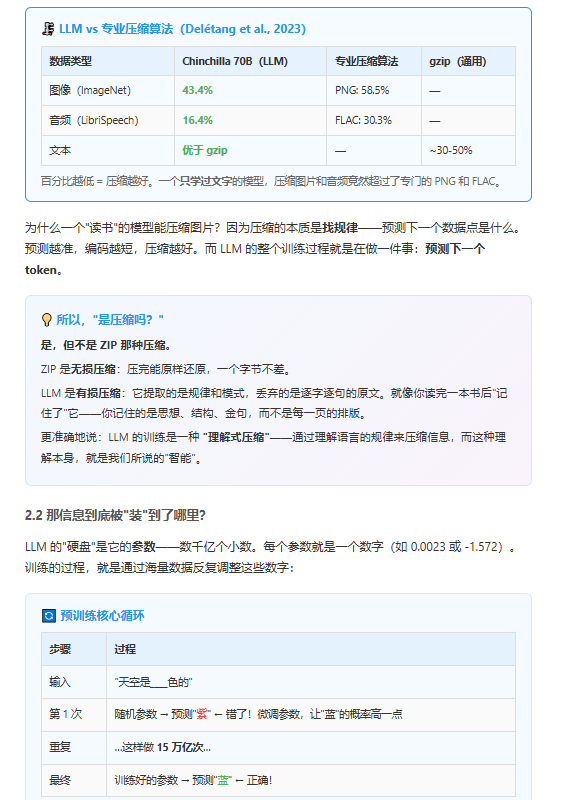
换一个角度感受:Google Books 项目估计,人类有史以来一共出版了大约 1.3 亿本书。LLaMA 3 的训练数据相当于 2 亿本书——超过了人类文明全部出版物的总和。
当然,训练数据不全是书。它还包括网页、论文、代码、论坛帖子、维基百科……几乎是人类写下的一切文字的数字化快照。
1.3 一个思想实验:如果互联网消失了
假设明天,全世界的服务器同时宕机,互联网上所有内容永久消失。我们手边只有一个训练好的 LLM。
问:能靠它"还原"互联网吗?
🟢 能做到的:告诉你水的沸点是 100°C、二战在 1945 年结束、Python 的语法、相对论的基本思想——高频知识的大部分可以重建。
🔴 做不到的:逐字还原维基百科的某个词条、找回你去年写的那篇博客、查到某小镇的邮编——精确细节和低频信息大量丢失。
📊 研究数据:Carlini et al.(2021)发现,GPT-2 生成的内容中只有约 0.1% 可以逐字匹配到训练数据。也就是说,模型"背下来"的原文不到千分之一。
类比一下:你读了一千本医学教科书,你的脑子里"压缩"了这些书的知识。你能诊断疾病、开处方、做学术讨论——但你能逐字默写出其中任何一本书吗?不能。
LLM 也是这样。它记住的不是原文,而是从原文中提取的模式和规律。
那么,这些模式到底是怎么被"装进"模型的?
二、这不是 ZIP 压缩——信息如何被"装进"参数
2.1 先回答那个直觉问题:这是"压缩"吗?
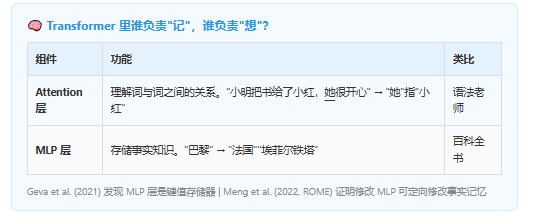
2023 年,DeepMind 的 Delétang 等人发表了一篇标题直白的论文:"Language Modeling Is Compression"——语言建模就是压缩。
他们做了一个惊人的实验:让一个只用文本训练的 LLM 去压缩图片和音频,结果——
一个常见的误解是:每条知识存在某个特定的参数里,就像数据库一样。实际上,知识是分散编码的——"巴黎是法国首都"分布在数千万个参数的组合激活中,而这些参数同时也参与编码"埃菲尔铁塔在巴黎""法语是法国的官方语言"。像全息照片,每一小块都携带整体信息的一部分。
不过,研究者们确实找到了一些规律——
2.3 "喂"多少才能"学"好?——Chinchilla 定律
2022 年,DeepMind 做了一个大规模实验(训练了 400 多个模型),得出一个关键结论:
Chinchilla 定律(Hoffmann et al., 2022):在固定计算预算下,模型的参数量和训练数据量应该等比例扩大。粗略地说,每个参数至少需要"看"20 个词才能学好。
类比一下:一个学生如果每个知识点只看 1 遍(相当于早期的 GPT-3),和每个知识点看 20 遍(相当于 Chinchilla),学习效果天差地别。而 LLaMA 3 的小模型(80 亿参数)更极端——每个参数"看"了将近 2000 个词,就像一个学生把课本翻烂了,虽然脑容量不大,但对每个细节都反复咀嚼。
这揭示了一个有趣的权衡:一个"笨但努力"的小模型,可以在实用场景中击败"聪明但不够勤奋"的大模型——因为小模型部署更便宜、推理更快。
三、死记硬背 vs 举一反三
3.1 什么东西被"背"下来了?
Kandpal et al.(2023)发现了一个关键规律:模型回答的准确率,与该知识在训练数据中出现的频率呈对数关系。翻译成大白话就是——
而且,模型越大,记忆力越强。Carlini et al.(2023)发现:模型规模每增大 10 倍,可逐字复现的训练数据量大约增加 19 倍。大脑袋装得下更多细节。
3.2 但"背"太多了,反而会变笨
⚠️ 数据重复的危害(Hernandez et al., Anthropic, 2022)
仅将训练数据中 0.1% 的内容重复 100 次,就能让一个 8 亿参数的模型退化到只有 4 亿参数的水平——尽管 90% 的数据仍然是唯一的!
更关键的发现:重复数据会损伤"归纳头"(Induction Heads)——这是模型里负责泛化推理的核心电路。重复把模型从"理解"推向了"死记硬背"。
这就好比一个学生如果把同一道题抄了一百遍,他记住的只是这道题的答案,而不是解题方法。换一道稍有变化的题,他反而不会做了。训练数据的去重比增量更重要。
3.3 "理解"到底长什么样?
当你让模型"用李白的风格写一首关于 996 的诗",它做了什么?