AI大模型的中文税:中文比英文更费Token极客公园
模型不是中性的,它内置了语言偏好。
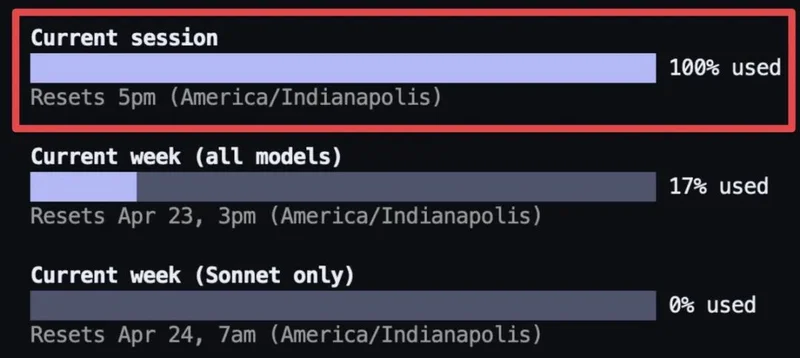
Opus 4.7 刚发布那几天,X 上怨声载道。有人说一次对话就把她的 session 额度用光了,有人说同一段代码跑完的成本比上周翻了一倍多;还有人晒出自己 200 美元 Max 订阅不到两小时就触顶的截图。
独立开发者 BridgeMind 承认 Claude 是世界上最好的模型,但同时也是最贵的模型。他的 Max 订阅用不到两小时就限额了,但幸好——他买了两份。|图片来源:X@bridgemindai
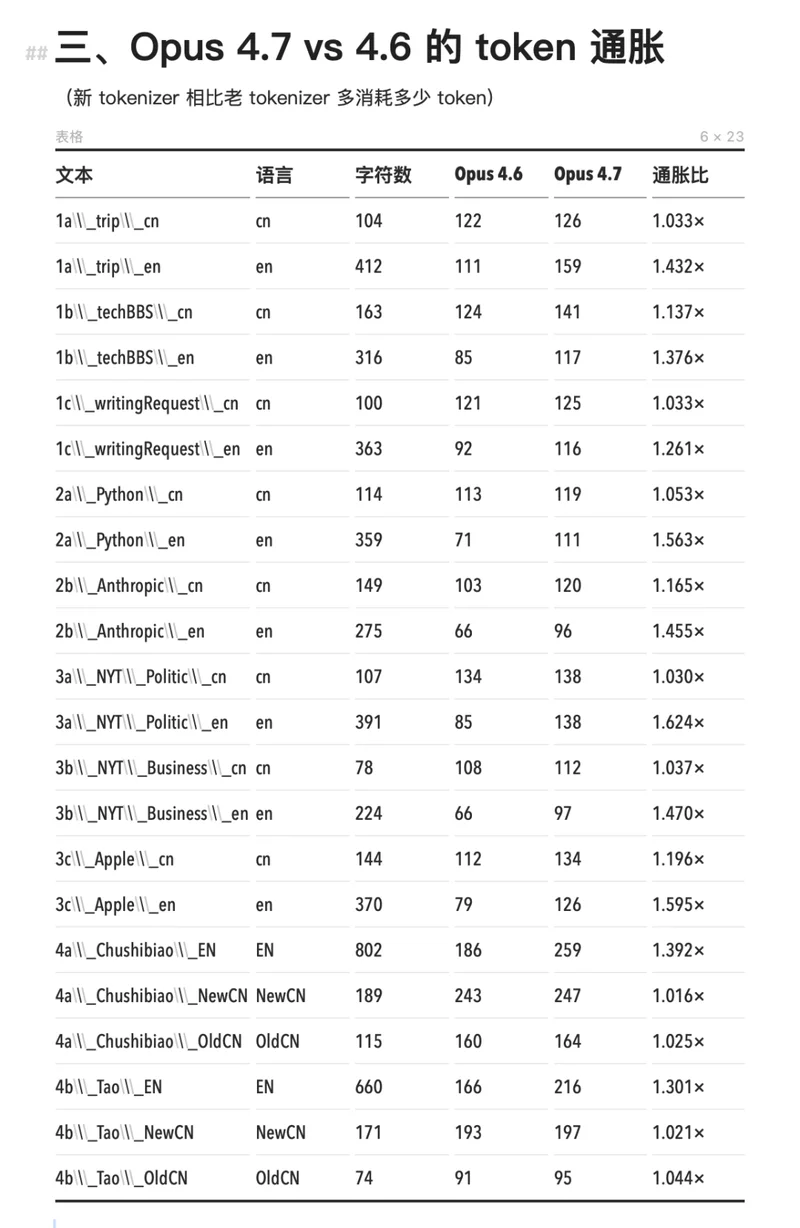
Anthropic 官方价格没变,每百万输入 token 仍是 5 美元,输出 25 美元。但这个版本引入了新 tokenizer,同时 Claude Code 把默认 effort 从 high 提到了 xhigh。两件事叠加,同一份工作消耗的 token 变成了以前的 2 到 2.7 倍。
我在这些讨论里看到两个和中文有关的说法。一个是:中文在新 tokenizer 下几乎没涨,中文用户躲过了这次涨价。另一个更有意思:古文比现代汉语还省 token,用文言文跟 AI 对话可以节省成本。
第一个说法暗示 Claude 对中文做了某种优化,但 Anthropic 的发布文档里,没提过任何和中文相关的调整。
第二个说法则更难解释。古文对人类读者来说显然比现代汉语难懂,一个对人类更复杂的文本,怎么会对 AI 更容易?
于是我做了一次测试,用 22 段平行文本(包含商业新闻、技术文档、古文、日常对话等类型),同时送进 5 个 tokenizer(Claude 4.6 和 4.7、GPT-4o、Qwen 3.6、DeepSeek-V3),读取每段文本在每个模型下的 token 数,做横向对比。
1、日常对话中英文(旅行、论坛求助、写作请求)
2、技术文档中英文(python 文档、Anthropic 文档)
3、新闻中英文(NYT 时政新闻、NYT 商业新闻、苹果公司官方声明)
4、文学选段中英古汉语(《出师表》《道德经》)
测完之后,两个说法都得到了部分验证,但事实会比传言更复杂一些。
1、在 Claude 和 GPT 上,中文一直比英文贵
2、在 Qwen 和 DeepSeek 上,中文反而比英文便宜
3、Opus 4.7 这次引发震荡的 tokenizer 升级,通胀几乎只发生在英文上,中文纹丝不动
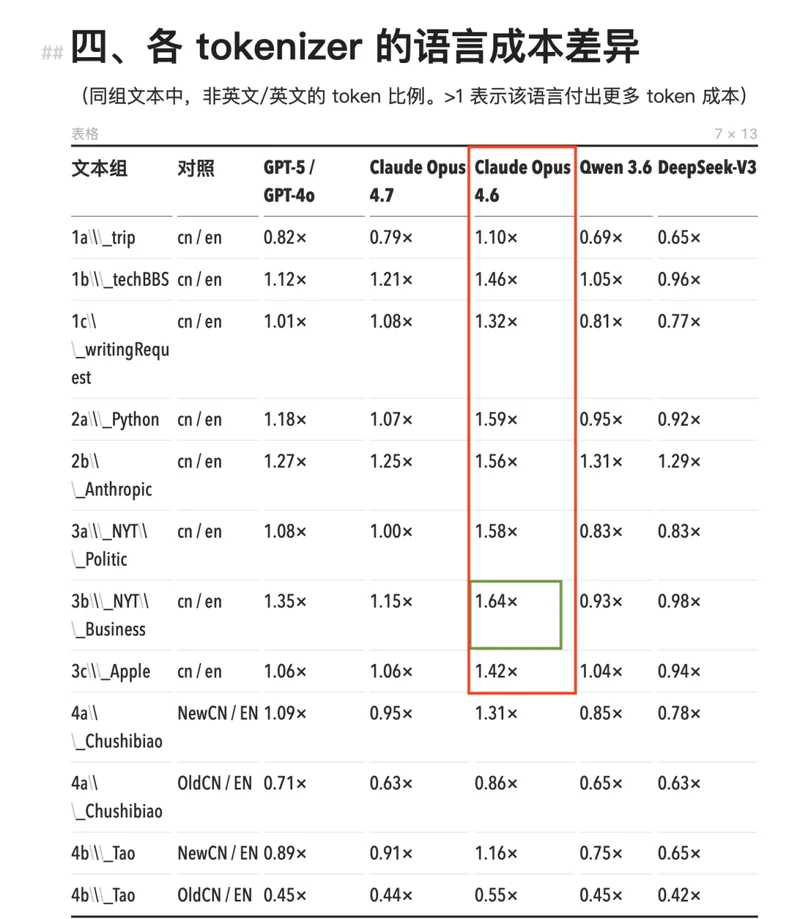
看具体数字。Claude Opus 4.7 之前的全系列模型(包括 Opus 4.6、Sonnet、Haiku),使用的是同一个 tokenizer。在这个 tokenizer 下,中文的 token 消耗全线高于等量英文内容,cn/en 比值范围在 1.11× 到 1.64× 之间。
最极端的场景出现在 NYT 风格的商业新闻:同一段内容,中文版要多消耗 64% 的 token,等于多付 64% 的钱。
Opus 4.6 及其之前的 Claude 模型,中文 token 的消耗量显著高于其它模型(红框)
最极端的场景出现在 NYT 风格的商业新闻:同一段内容,中文版要多消耗 64% 的 token(绿框)
GPT-4o 的 o200k tokenizer 好一些,cn/en 比值多数落在 1.0 到 1.35× 之间,部分场景低于 1。中文仍然整体偏贵,但差距比 Claude 小得多。
国产模型 Qwen 3.6 和 DeepSeek-V3 的数据则完全反了过来。两者的 cn/en 比值大面积低于 1,这意味着同样的内容,中文版反而比英文版省 token。DeepSeek 最低做到了 0.65×,同一段话中文版比英文版便宜三分之一。
Opus 4.7 的新 tokenizer 通胀几乎只发生在英文上。英文 token 数膨胀了 1.24× 到 1.63×,中文大量维持在 1.000×,几乎没有变化。开头那些英文开发者的账单震荡,中文用户确实没感受到。原因可能是中文在旧版上已经被切到了单字颗粒度,可拆分的空间极小。
Opus 4.7 对比 4.6,英文消耗的 token 更多了,中文反而没变
测试过程中我还注意到一件事。token 消耗的差异不只是账单问题,它直接影响工作空间的大小。同样 200k 上下文窗口,用旧版 Claude tokenizer 装中文资料,能塞进去的内容量比英文少 40% 到 70%。
同一类工作,比如让 AI 分析一份长文档或者是总结一组会议记录,中文用户能喂给模型的材料更少,模型能参考的上下文更短。结果就是付了更多的钱,但得到的是更小的工作空间。
四组数据放在一起看,一个问题自然浮出来:
为什么同一段内容换个语言,token 数就不一样?为什么 Claude 和 GPT 的中文贵,Qwen 和 DeepSeek 的中文反而便宜?
答案藏在上文多次提到的概念 tokenizer(分词器)上。