DeepSeek-V4报告亮了新智元
DeepSeek-V4的技术报告,简直诚实得令人震惊。V4发布延迟的秘密,被正式透露了!这颗大雷的背后,究竟是指谁?研究者们已经纷纷展开了猜测。并且,论文中用硬核工程暴力重构Agent的操作,也让社区直呼:国产之光,实至名归。
昨天,是名副其实的AI圈「春晚」。
DeepSeek-V4的技术报告一出,近60页的篇幅,从架构到训练到后训练全部摊开。
484天,对这个团队来说不寻常。V3从V2到发布只用了不到8个月。V4为什么多花了将近一倍的时间?
认真研读完这篇报告,我们发现了背后可能的原因,以及这家「国产之光」令人震撼的工程底色实。
可以说,DeepSeek-V4真正令人深思的,不是它堆了多少算力,而是它在Agent训练、工程底座、以及处理「训练震荡」时的那种近乎残酷的理性和透明。
今天,我们直接拆开V4的引擎盖,看看里面藏着哪些不为人知的硬核细节。
33T Token + 万亿参数
难度直接拉满
距离V3发布整整484天,V4才以「preview version」的姿态上线。
论文里虽然没有解释这个时间跨度,但有一段内容或许能提供线索。
V3用了14.8T token做预训练,V4直接翻倍,V4-Flash训了32T,V4-Pro训了33T。参数量同样大幅扩张,V4-Pro总参数1.6T,V4-Flash也有284B。
数据翻倍、参数翻倍,训练稳定性的难度也跟着上了一个量级。
报告里非常诚实:DeepSeek明确点名了「训练稳定性挑战」。
谷歌DeepMind研究者Susan Zhang表扬说:这种透明的做法值得称赞。这个说法还得到了龙虾之父的转发
在超大规模集群上,当参数量和训练数据达到某个临界点时,硬件的细微误差会被无限放大。
论文里,「stability」这个词出现了十余次。
放在一篇技术报告里,这个频率本身就是信号。正常情况下,稳定性是默认前提,不值得反复提。反复提,说明它确实是个问题。
具体来看,DeepSeek发现MoE层中的数值异常值(outlier)会通过路由机制不断放大,形成恶性循环,最终触发loss spike,训练曲线突然飙升。
团队祭出的主要补救措施是两招。
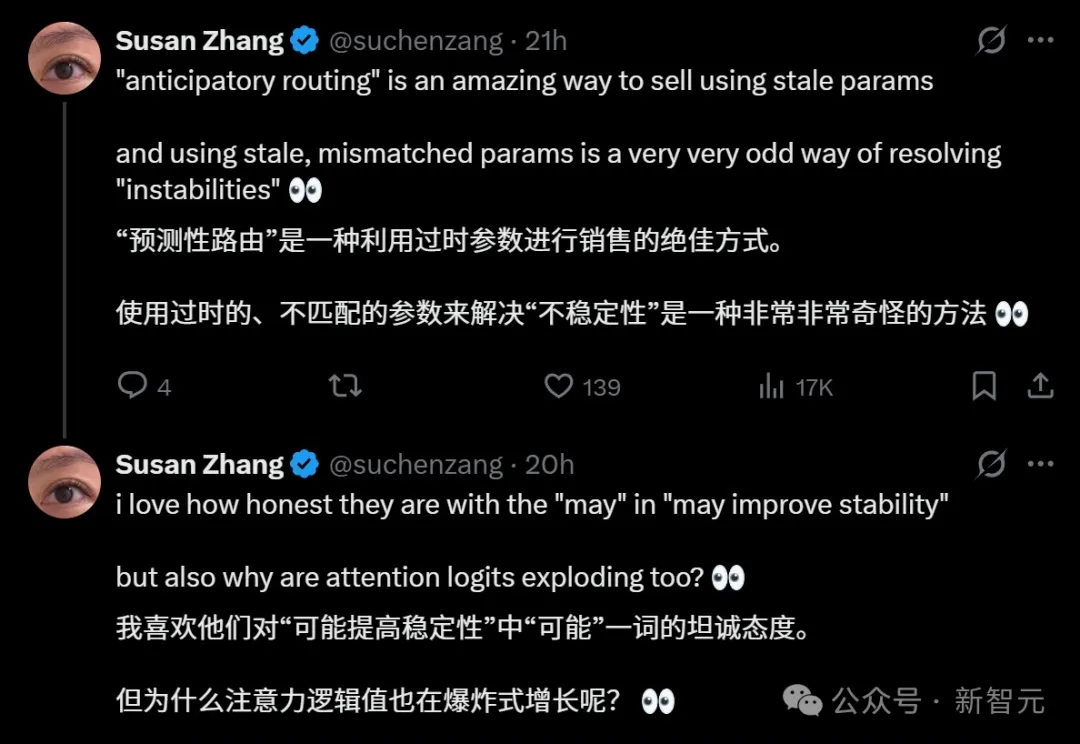
第一招叫Anticipatory Routing。它本质上就是在路由阶段使用稍早版本的参数,把骨干网络和路由网络的更新解耦,打破两者之间的恶性循环。
第二招是SwiGLU Clamping。它直接把SwiGLU的数值范围钳制在[-10, 10]以内,从源头压制异常值,虽然暴力但很有效。
当前大模型训练已进入硬件底层、编译器栈、以及数学架构三位一体的无人区
论文里有个细节很耐琢磨。
Anticipatory Routing和SwiGLU Clamping,DeepSeek确认「显著有效」,但紧跟一句「底层机理仍是open question」。
连Q/KV归一化这种已经被广泛验证的基础操作,论文的措辞都只敢写「may improve training stability」。
一个「may」字,足以说明在万亿参数MoE的训练里,没有什么是百分百靠得住的。
从15T到33T,数据量翻倍带来的不是线性增长的困难,而是指数级放大的系统性风险。
每一层网络、每一个梯度更新、每一次通信同步,都在更大的规模下被放大成潜在的崩溃点。
而DeepSeek选择把这些全写进论文里,这在业内几乎没有先例。
硬件的锅,还是软件的锅?
所以,技术报告中明确提出的「训练稳定性挑战」,指的到底是谁家的硬件?
虽然论文里没有明确点名任何硬件平台,但已经有嗅觉敏锐的人开始猜测了。
有观点直接指出:所谓「训练稳定性挑战」,很可能就是算力平台的问题。而且不只是DeepSeek一家踩坑,各大厂商都遇到过。
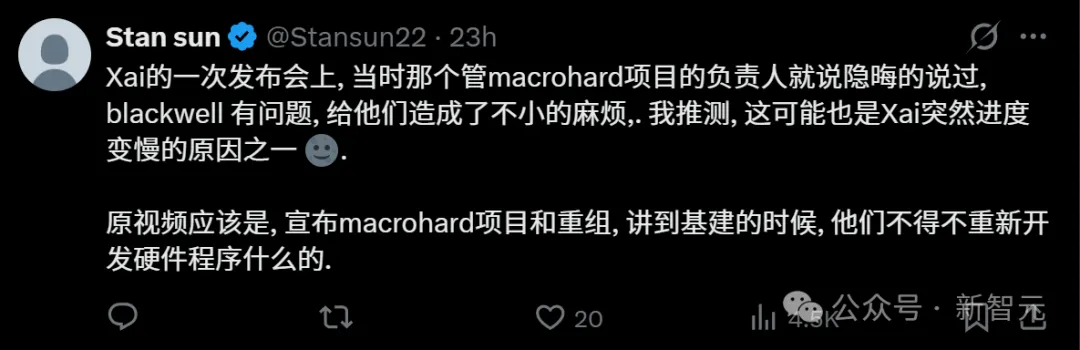
xAI在一次发布会上,Macrohard项目的负责人曾隐晦提到,英伟达最新的芯片给他们造成了「不小的麻烦」,不得不重新开发硬件适配程序。这或许也解释了xAI进度突然放缓的原因之一。
不过,这件事当然没那么简单。
大型算力集群涉及的变量太多:芯片本身、互连架构、散热系统、电力供应、驱动版本、编译栈适配。训练不稳定未必等于芯片级缺陷,也可能是系统集成层的问题。
不过,目前还没有任何官方文件给出答案。
一切都还在猜测之中。
Agent训练体系
工程能力让人肃然起敬
如果说V4的预训练是在和硬件博弈,那么它的Post-training则展现了教科书级别的工程审美。
可以说,Agent能力的工程化路径,是V4论文里最值得细读的部分。
以往我们认为Agent能力是「教」出来的,但DeepSeek认为,Agent能力应该是「长」出来的。
拒绝「硬迁移」,预训练阶段的「血脉注入」