Claude Opus 4.7连夜突袭新智元
Anthropic 正式发布 Claude Opus 4.7,核心升级落在复杂任务执行、高清视觉理解和更稳的长链路工作流上。对普通用户来说,最直接的变化是更听指令、更会看图、产出更接近成品,同时也要注意Token也会烧得更快了。
就在刚刚,Anthropic 正式发布 Claude Opus 4.7,并将它定义为当前可广泛使用的最强 Claude 模型。
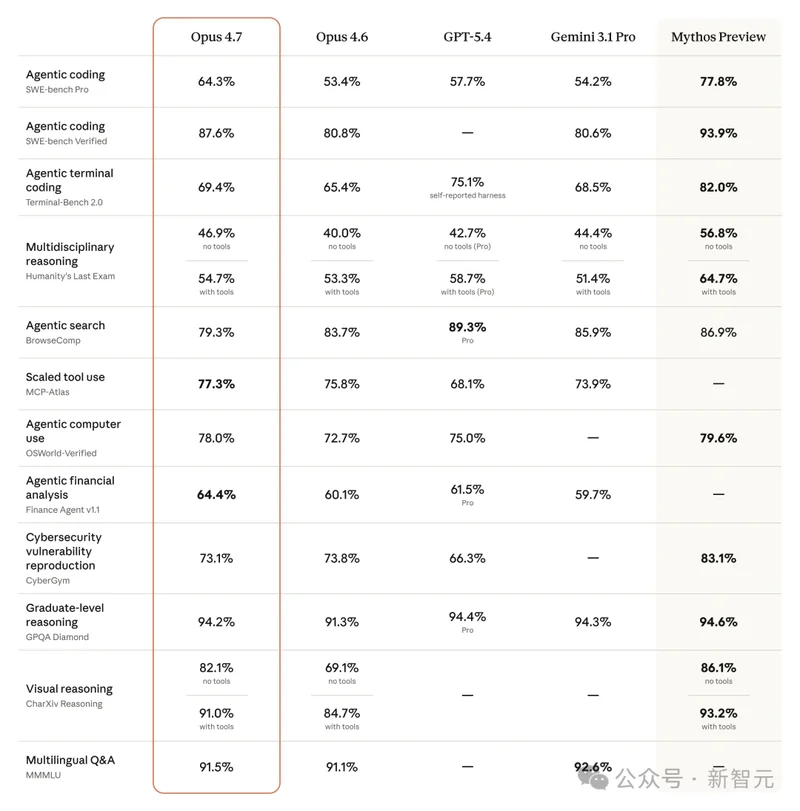
性能不如此前曝光的新一代Claude Mythos Preview那么炸裂,但比普通用户能真正用到的Opus 4.6强了太多,除了Agentic搜索能力略有下降外,实现了全面碾压!
官方给出的本次升级的关键词:复杂任务、更强视觉、更稳的长链路执行,以及更少需要人工参与。
只要还在用大模型写文档、读截图、做演示、整理材料,Opus 4.7 带来的体验变化,很难绕开。
本次更新最大的亮点,是Opus 4.7的视觉能力大幅提升,在测试中从Opus 4.6约50%的分数,直接飙升到接近满分!而这,补上了AI目前最大的视觉短板,或许已经不知不觉地迈过了替代人类工作的那道最重要的槛!GPT-5.4 Thinking是这样评价它的对手Claude Opus 4.7发布给打工人带来的影响的:
本次升级的关键在于复杂任务的完成度
Anthropic 把 Opus 4.7 的核心升级点放在了高级软件工程和长时间任务执行上。
用户已经可以把过去需要密切监督的高难度编码工作交给它处理,它会更严格地执行指令,也会在回报结果前主动想办法验证输出。
API 发布说明里,Anthropic 也把它称为当前最强的通用可用模型,面向复杂推理和代理式编码场景。
大模型竞争的焦点,正在从答得像不像,转到做得完不完。只会写一段漂亮答案,已经不够了。
能不能把一份长文档改干净,能不能把一套资料串起来做成可交付物,能不能持续几十分钟甚至更久不跑偏,这才会决定它在日常工作里能不能真的替人扛起一片天。
这能够从 Opus 4.7 的官方发布重点里直接看出来。
纯编程只是开胃菜
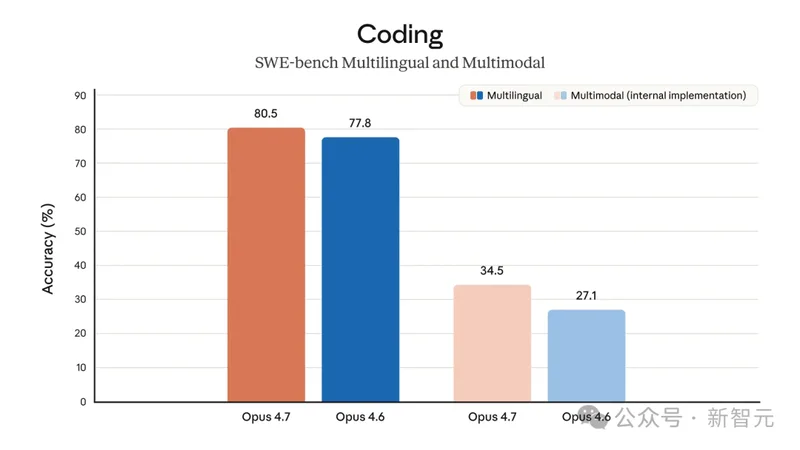
SWE-bench Multilingual 测的是模型修复真实 GitHub issue 的能力,覆盖多种编程语言。
Opus 4.7 拿 80.5%,Opus 4.6 拿 77.8%,涨 2.7 个百分点。
单看这个数,似乎只是一次常规迭代。但同一张图右边那组数据更有意思,后面回头讲。
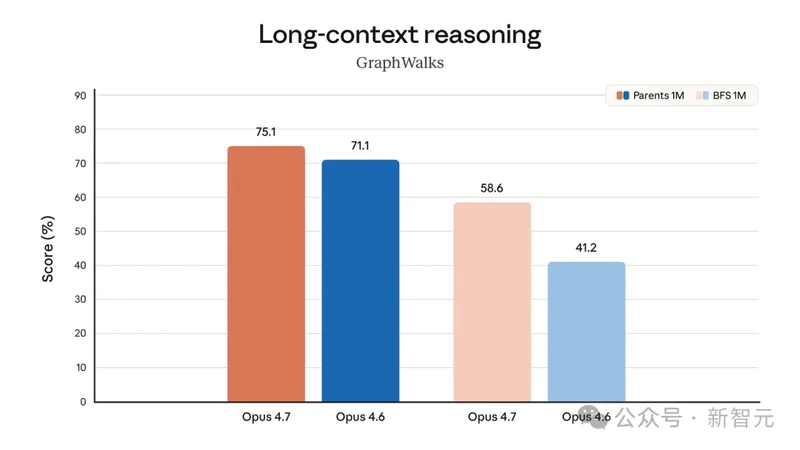
1M token 里的长任务
GraphWalks 是 OpenAI 做的长上下文基准,把一张有向图用边列表塞满 1M token 上下文,让模型做图遍历。
两种考法:一种是 Parents,给一个节点让模型找出所有直接指向它的父节点;另一种是 BFS 广度优先搜索,从起点出发一路找到特定深度可达的节点,对 Agent 跑多步骤长任务是硬指标。
在 Parents 1M 这趴,Opus 4.7 从 71.1% 提到 75.1%,4 个百分点的常规改进。
而到了 BFS 1M,Opus 4.7 则从 41.2% 一口气干到 58.6%,拉开 17.4 个百分点。
换个场景再看。
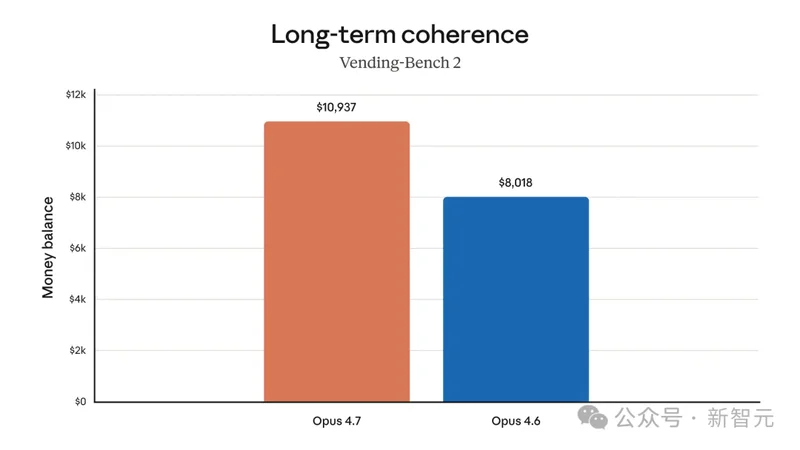
Vending-Bench 2 让模型模拟经营一台自动售货机,测长时间工作流里的决策连贯性。
Opus 4.6 最终余额 8,018 美元,Opus 4.7 做到 10,937 美元。
同一台售货机,同一个时间窗口,Opus 4.7 多挣了 36%。
Agent 的眼睛换了代
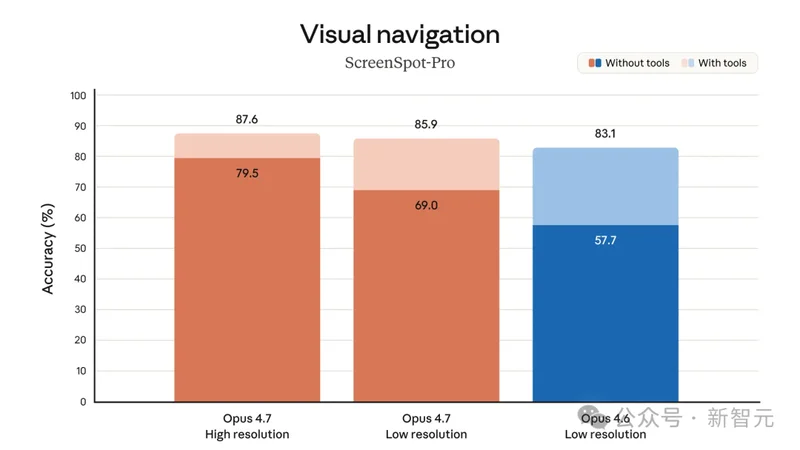
ScreenSpot-Pro 测的是 Agent 的屏幕定位能力。
给模型一张 VSCode、Photoshop、AutoCAD 这类专业软件的高分辨率桌面截图加一条自然语言指令,让它定位到具体的 UI 元素。在高分辨率屏幕里,目标 UI 元素往往只占整张图的 0.07%,极考验精细视觉。
同样低分辨率不带工具,Opus 4.6 拿 57.7%,Opus 4.7 拿 69.0%,拉开 11.3 个百分点。
切到高分辨率,Opus 4.7 不带工具就达到了 79.5%。叠加工具调用,跑分直接来到 87.6%。
视觉能力在一些测试(如XBOW的基准测试)中,Opus 4.7相比Opus 4.6得分直接翻倍,从54.5%跃升到接近满分98.5!