大厂token排行榜,摸鱼的人排第一?Kevin Roose
美剧《火线》里有条贯穿多季的暗线:巴尔的摩警察局为了让犯罪数据好看,把重罪降级为轻罪,让强奸案凭空消失。上级看着报表上的数字逐月下降,在市政厅汇报时满脸骄傲。
只有街区的居民知道,街上枪声一点没少。
剧里有句台词:You juke the stats and majors become colonels. 刷刷数据,少校能升上校。
但谁也没想到,2026 年,这句话的新版本正在中国互联网大厂上演。
只不过被刷的不是犯罪率,而是AI token 消耗量。只要你刷刷 token,摸鱼也能变劳模。
最近,小红书上有个帖子很火。
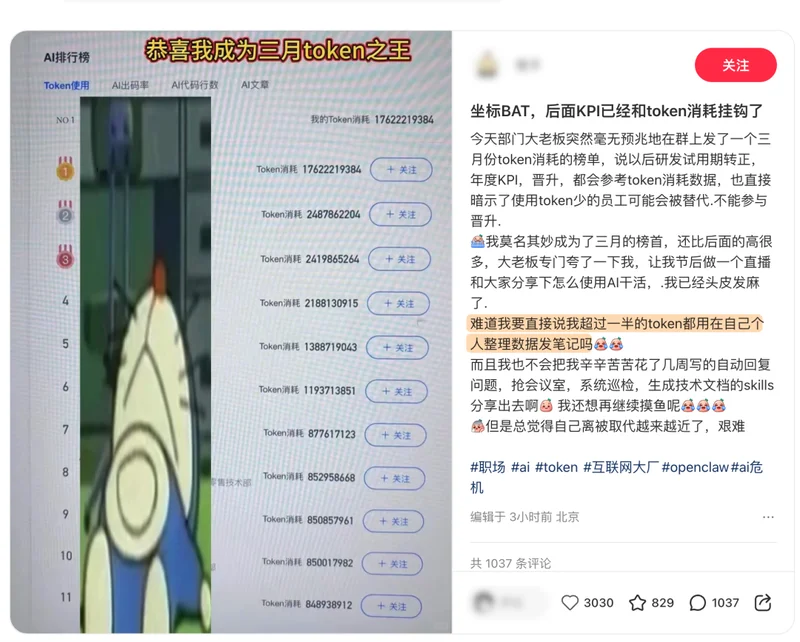
一个自称在 BAT 大厂(首先 B 排除百度)的网友说:部门突然开始搞 token 消耗排行榜,以后试用期转正、年度KPI、晋升,都要参考这个数据,甚至用得少的人,可能被替代。
他是三月份的榜首,还遥遥领先,被老板点名夸了一顿,让他节后给全部门做直播分享怎么用 AI 干活。
但他没敢说的是,自己超过一半的 token,是在整理个人数据发笔记。。。
不光是大厂噢。
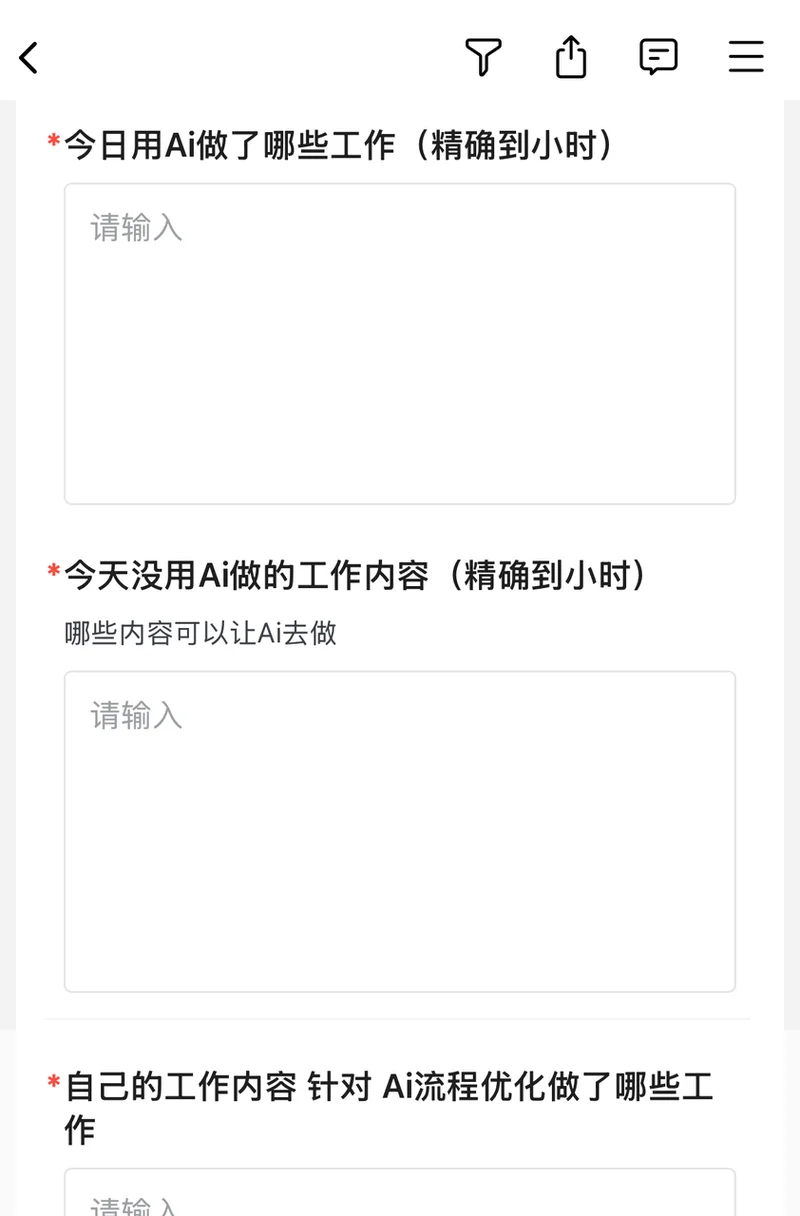
我身边有个发小在一家公司干了三年,前几天突然被要求:日报里要填写今天用 AI 做了哪些工作,提高了多少产能,还要精确到小时。
搞得他现在动不动要打开AI软件,想想怎么刷。
看到这些,差评君第一反应是迷惑,这不就是 2026 年版的工位亮灯等于加班吗??
在聊这事之前,咱先简单解释一下 token。
token 是 AI 处理信息的最小计量单位,你可以把它理解成 AI 世界的字数/货币,一个中文字大约等于 1 到 2 个 token。
你和AI对话一轮, 消耗的 token = 你发给 AI 的字 + AI 思考推理 + AI 回复的字。
AI 模型公司呢,就按 Token 消耗量去收钱。
理论上,token 消耗量和 AI 交互是成正比的。你消耗越多,就能说明你跟 AI 交互越频繁。
听起来没毛病,黄仁勋也这么想的。
3 月下旬的英伟达GTC大会上,黄仁勋说公司应该给每个工程师配一笔 token 预算,金额大约是基本工资的一半,让 AI 把他们的产出放大十倍。
后来他在 All-In 播客上又举了个例子:
假设有一个年薪 50 万美元的工程师,年底你问他今年花了多少 token,如果没花到 25 万美元,老黄说会“ deeply alarmed ”,深感震惊。
他要说 5000 美元呢?
老黄直接“I will go ape something else”,中文大概就是气得跳脚,当场发疯,叼你 MD(最后一句我加的戏)。
在老黄看来,优秀的工程师就应该大量使用 AI,用得越多产出越高。
毕竟公司给你配了 AI 资源,你用资源提效,产出放大,你要是不用,确实说不过去。
这套逻辑,不只老黄一个人这么想。
2025 年 4 月,Shopify CEO Tobi Lutke 给全公司发了封备忘录:申请加人之前,必须先证明 AI 做不了这个工作,而 AI 的使用情况也要纳入绩效考核。
硅谷甚至出现了一个专门的词来形容这股风气:Tokenmaxxing,token 最大化。
《纽约时报》科技记者 Kevin Roose 给它做了专题报道,里面数据很夸张:OpenAI 有工程师一周处理了 2100 亿 token,Anthropic有用户一个月在 Claude Code 上烧掉了 15 万美元。
而现在,这股风终于吹到了国内,企业们开始把 token 消耗、AI 使用时长绑进绩效。。。
不是兄弟。。。
和 AI 互动得多,不代表解决的问题就多啊。就好比我们去健身房,不是去了 100 次体重就一定减少的。
好,退一万步讲:
就算我们暂且接受“用得多=产出高”这个前提。那至少这个指标应该很难造假吧?
恰恰相反,刷 token,可能是 2026 年最容易的一件事。
差评君简单露几手,看完你就知道这玩意作为指标有多差劲了。
第一种,上下文滚雪球。
为了联系上下文,AI 的每次回答都会把之前的所有对话从头重读一遍。对话越长,每轮重读消耗的 token 越多。第 1 轮只要 1500 个 tokend,但到了第 20 轮、第 50 轮光重读就要烧好几十万、百万 token。
你就这么无限对话下去,就算被领导质疑,你就说:这可是我反复追问了好多轮才得到满意的结果。
懂不懂“深度思考”啊。
第二种,开 50 个AI Agent(代理)让它自动跑任务。
Agent 会自己派活、自己重试、遇到问题自己绕路,每个步骤都在烧 token,思考过程也算钱,跑一晚上第二天你就是部门劳模。