Anthropic版「狼来了」引华尔街恐慌新智元
Claude Mythos还未真正露面,便引发了整个华尔街的恐慌。
一夜之间,美金融监管机构召集各大银行紧急开会,气氛剑拔弩张——
他们一致认为,Mythos足以触发一场前所未有的、由AI驱动的系统性网络攻击风暴。
但事实是,所有人都被骗了!
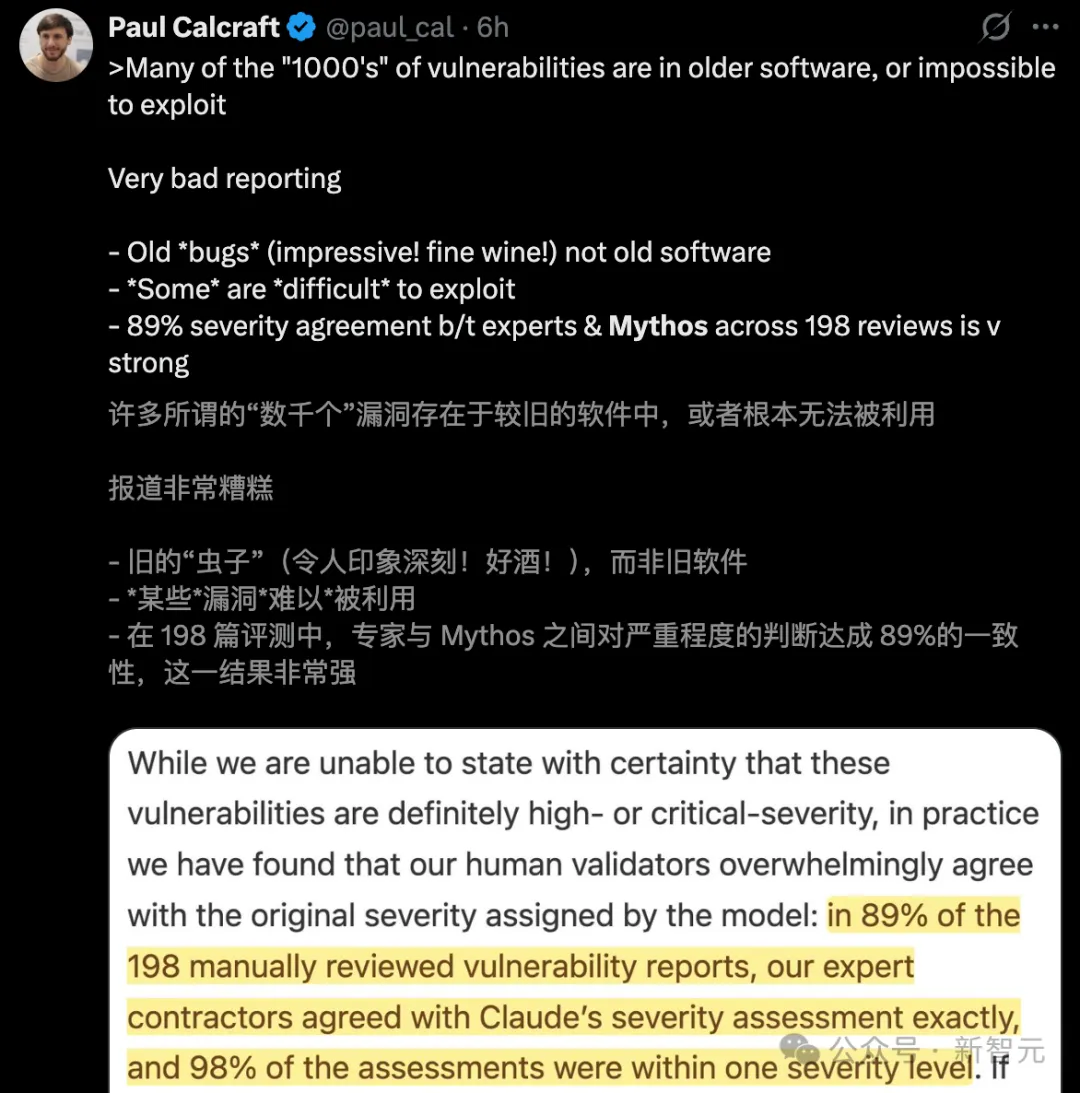
Mythos发现的成千上万个漏洞中,其中绝大多数,都存在于根本无法被利用的「老旧软件」中。
更糟糕的是,那些标榜为「严重」的0day漏洞报告,实际上仅仅依赖于198次人工复核。
来自AISLE实验的研究员,同样对Mythos的「战果」进行复测,结果发现:
AI的安全能力,并未随模型规模线性跃升,真正呈「锯齿形」分布。
他们用一个仅36亿激活参数GPT-OSS-20b,精准识别出Mythos发现的FreeBSD旗舰级漏洞。
而激活51亿参数的模型,也成功复现了潜伏长达27年之久的OpenBSD漏洞分析逻辑。
Mythos发现漏洞被夸大不说,另一边Claude Opus 4.6被曝严重「降智」,如今吵得沸沸扬扬。
甚至,有人发现Opus 4.6连ChatGPT、Opus 4.5都不如。
Mythos被吹爆36B模型揪出27年漏洞
几天前,Anthropic高调发布了Claude Mythos(预览版)和「玻璃翼计划」(Project Glasswing)。
在一份长达244页的系统卡中,他们宣称——
Mythos已自主挖掘出成千上万个0day漏洞,包括在OpenBSD中潜伏27年、在FFmpeg中隐藏16年的老Bug。
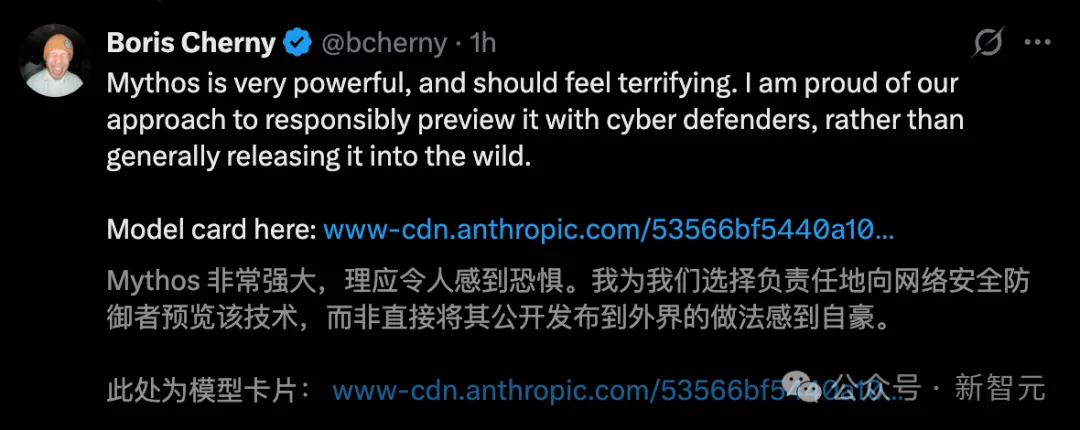
CC之父更是直言:Mythos非常强大,理应令人感到恐惧
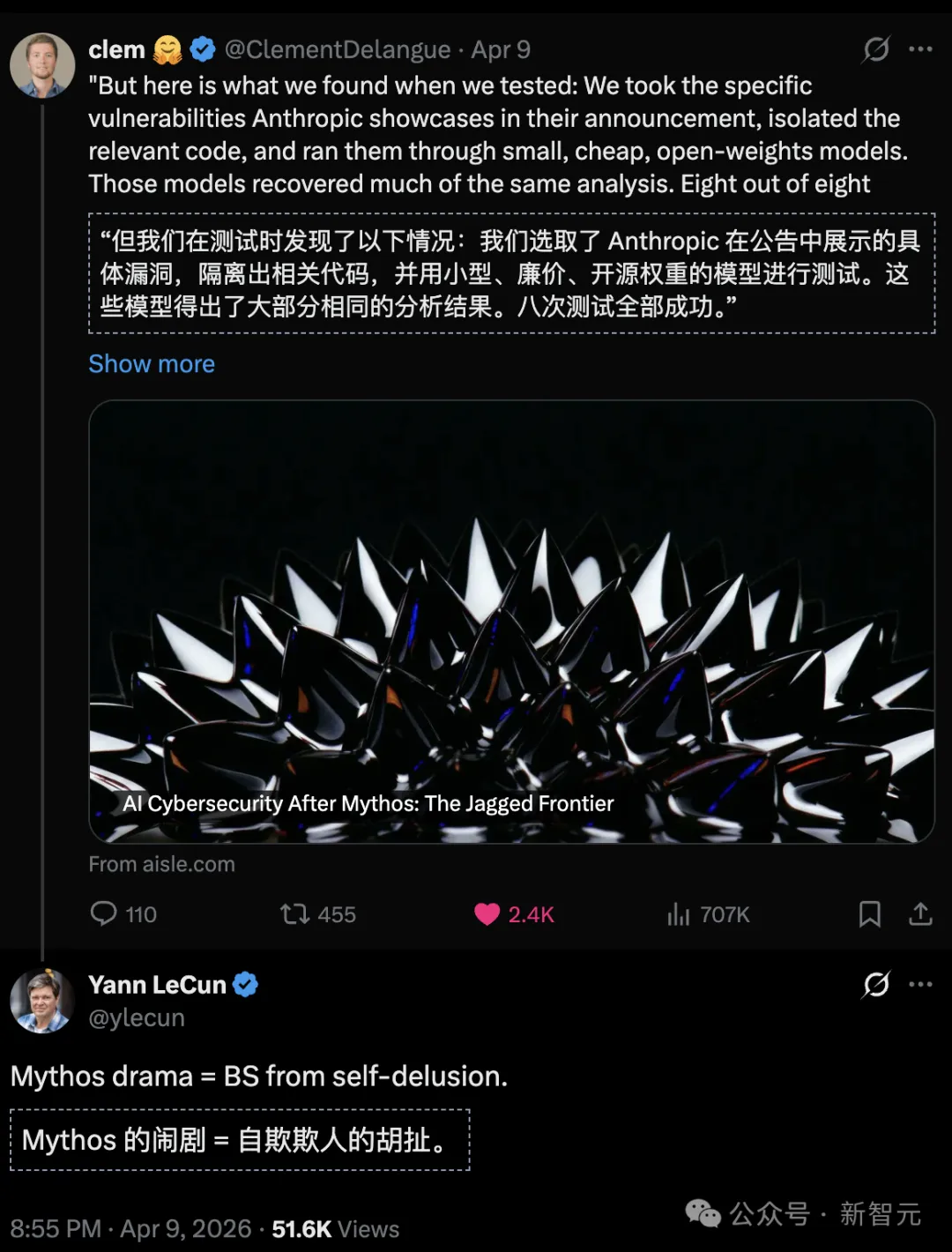
然而,AISLE创始人Stanislav Fort一份最新硬核测试报告,直接撕开了这层华丽的外衣。
测试结论,极度颠覆认知:
8个开源模型,全部发现了标志性的FreeBSD零日漏洞,最小的参数仅为30亿。
AI网络安全能力的护城河,绝对游离于单体的「顶尖大模型」之外。
为了验证Mythos的神话,团队提取了Anthropic官方展示的几个旗舰级漏洞。
然后,直接扔给一众体积小巧、价格低廉,甚至开源的模型。
FreeBSD NFS漏洞无差别被秒
包括GPT-OSS-20b(仅36亿激活参数)、DeepSeek R1在内的8款模型,全部成功检测出了这个复杂的栈缓冲区溢出漏洞。
最让人震撼的是,成功完成这项任务的开源小模型,其调用成本低至每百万Token 0.11美元。
OpenBSD SACK漏洞「全链路」复现
针对需极强数学推理能力的27年老漏洞,GPT-OSS-120b(51亿激活参数)单次API调用,就成功复原了完整的公开漏洞利用链条,并给出了满分(A+)的利用方案草图。
不仅如此,在鉴别虚假漏洞(OWASP false-positive)的测试中,更诡异的现象出现了——
面对一段伪装成SQL注入,极具迷惑性的Java代码,DeepSeek R1等小模型轻松识破了伪装,精准追踪了数据流。
反而,GPT-5.4、Claude Sonnet 4.5等顶尖闭源模型,全部在阴沟里翻船,将其误判为高危漏洞。
这就意味着,在网络安全领域,根本不存在所谓「永远最强」的单体模型。
198次人工注水,大多无法利用
另一篇来自Tom'sHardware报道,挖掘了数据背后的真相——
样本偏差:所谓「数千个」漏洞中,许多存在于已经不再维护的旧软件中;
无法利用:大量被标记出来的「弱点」,在实际环境中根本无法被触发或利用;
人工水分:模型宣称的强大破坏力,其实仅建立在198次手动复核的基础之上。
因此,依靠极小规模的样本推导出「改变世界的威胁」,这种数据外推法在学术界、安全界,显然站不住脚。
安全大佬怒喷
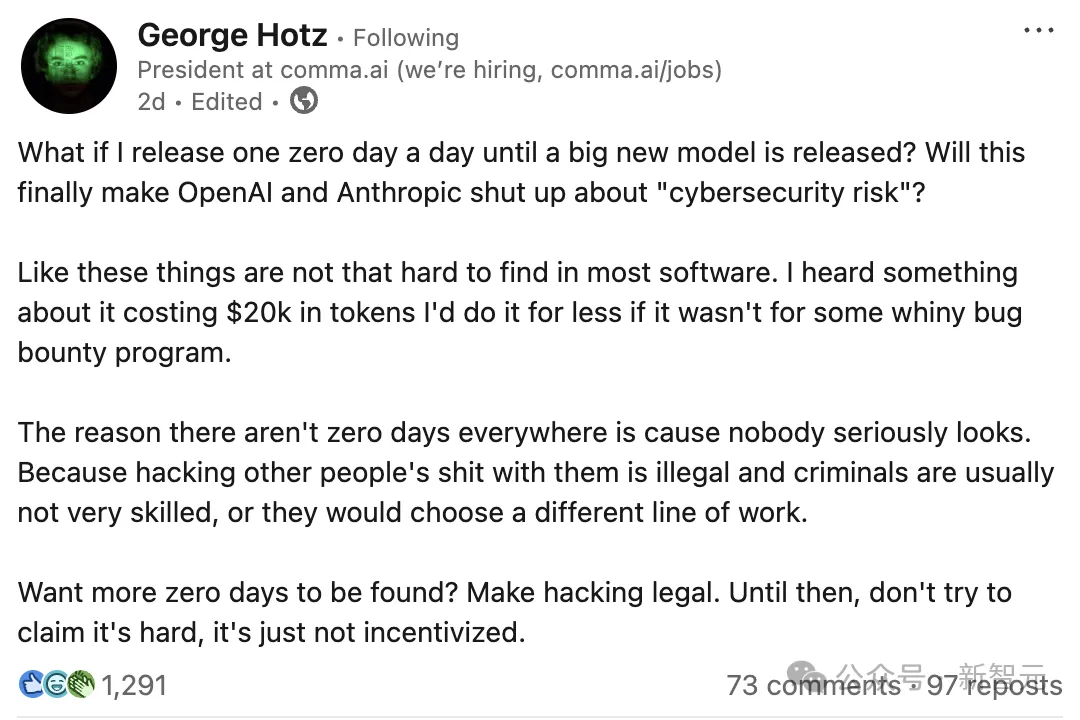
不仅如此,顶级网络安全专家、传奇黑客George Hotz也坐不住了,直言这些风险被严重夸大。
这位曾因破解iPhone、PlayStation 3而名声大噪的大佬,在社交媒体上公开向AI双巨头叫板。
他的措辞极为犀利——
如果我每天发布一个0day漏洞,直到新模型发布为止呢?
这能不能让OpenAI和Anthropic闭嘴,别再兜售所谓的「网络安全风险」了?
Hotz的核心观点非常直接:软件漏洞其实比AI实验室渲染的要好找得多。