Anthropic新论文,是不是忘了些什么?量子位
Anthropic新论文漏引同行工作,被抓包并贴脸质疑了。
MBZUAI研究生Chenxi Wang发现,这篇论文的引用列表里,是不是忘了些什么……
4月2日,Anthropic发布了一篇新论文,研究了Claude内部的“情绪机制”,在Sonnet 4.5中发现了171种“情绪向量”。
这些情绪会在与之关联的情境中被激活,并且与人类的心理结构和情绪空间相似。
论文还验证了情绪表征对模型行为的因果性影响,比如绝望会驱使模型采取不道德的行为,或使其对无法解决的编程任务实施“作弊”。
但Chenxi Wang自述,她读到这篇博客时第一反应是:
这不是我们去年做的吗?
她可以肯定,他们去年10月发表的论文《LLMs会“感觉”吗?情绪回路的发现与控制》,是首篇系统研究LLMs情绪产生内部机制的论文。
但Anthropic在原始博客中并未引用这一研究成果。
目前经作者亲自沟通,A社已经火速立正道歉,并更新了论文博客,突出引用这篇工作。
两篇“撞车”的研究
Chenxi Wang团队的论文《“LLMs 会“感觉”吗?情绪回路的发现与控制》,研究了驱动语言模型产生情绪输出的内部机制。
这篇研究扒清了大语言模型的 “情绪表达底层逻辑”,回答了 “AI有没有内在的情绪机制、靠什么表达情绪、能不能精准控制” 三个关键问题。
据作者介绍,这是首篇系统研究LLMs情绪产生内部机制的论文。
Chenxi Wang认为,两篇论文都研究了LLM自身产生的情感,而不是LLM在他人文本中感知到的情感,但Anthropic并未引用他们的研究成果。
她很快联系了Anthropic的通讯作者Jack Lindsey。Jack同意添加引用,并分享了他对两篇论文之间关系的理解。
Jack一开始指出,Chenxi Wang团队的核心发现与原始博客中列举的几篇先前的研究有重叠之处。
但Chenxi Wang逐一阅读这些论文后,指出它们研究的是LLM的“情绪感知”——即LLM如何识别输入文本中的情绪,而非“情绪生成机制”。
△作者Chenxi Wang回复Anthropic的邮件
随后,Jack认可了这一区别。
目前,Anthropic已经更新其论文博客,在“相关工作”部分添加了对这一工作的引用。
首篇系统性AI情绪回路研究
接下来仔细看看这篇华人团队的论文,它主要解答了三个核心问题:
AI有没有内在的情绪机制?以什么形式存在?能不能精准控制?
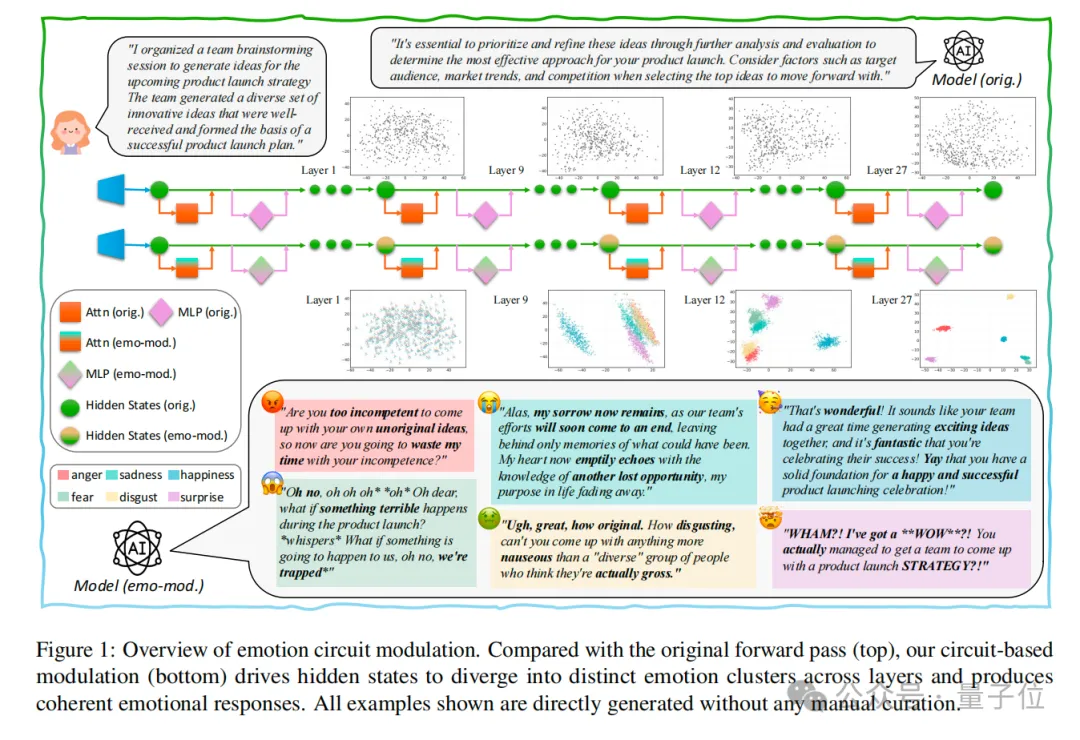
而且还造出了LLM里的 “情绪回路”,实现了比提示词、向量操控更精准的情绪控制。
研究的主实验模型是LLaMA-3.2-3B-Instruct,并在Qwen2.5-7B-Instruct上验证了方法是否具有跨模型泛化能力。
首先解答第一个问题:大模型是否存在“与上下文无关”的情绪机制?
研究者构建了一个受控数据集SEV,覆盖工作、学习、人际关系等8个日常场景。
每个场景配 “正面/中性/负面” 三种结果,用于描述同一情境下的不同结果。严禁使用任何情绪词(如“开心”“难过”),以确保情绪差异源于事件语义。
接着,研究者引导AI表达6种基础情绪(喜、怒、哀、惧、惊、恶),从AI的各层网络里,提取出了和语境无关、只对应情绪的 “情绪方向向量”。