北大团队改造DeepSeek注意力:快四倍量子位
就在大家都急头白脸地等待DeepSeek-V4的时候,冷不丁一篇新论文引起了网友们的注意——
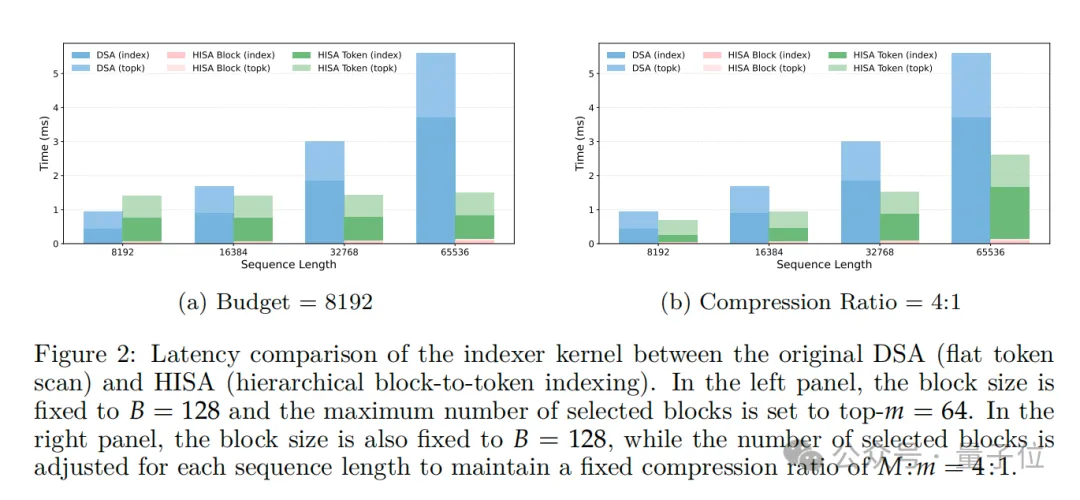
提出新稀疏注意力机制HISA(分层索引稀疏注意力),突破64K上下文的索引瓶颈,相比DeepSeek正在用的DSA(DeepSeek Sparse Attention)提速2-4倍。
不仅做到了大幅提速,而且几乎不丢精度、即插即用不用重新训练。
论文直接在DeepSeek-V3.2和GLM-5上替换索引器,无需微调。
并且在找关键信息、长文本理解等任务上,精度都和原方法几乎持平。
两步消除上下文索引瓶颈
这篇论文想解决的问题很明确:给大模型的稀疏注意力机制换个更高效的 “检索器”。
现有主流的DSA等token级稀疏注意力,核心就是通过只计算关键token的注意力,降低了核心计算成本。
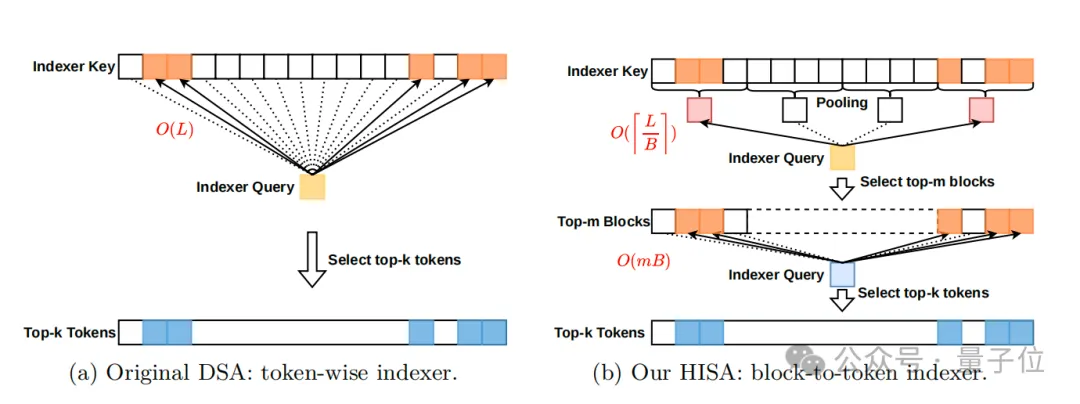
但这个设计有个致命隐藏问题:要挑出相关字符,得靠一个 “索引器”——它需要把每个待查字符,和前面所有字符挨个打分,再选分数最高的。
文本长度L越长,这个打分的工作量是L的平方级增长。比如长度翻倍,工作量就会翻4倍。
到超长文本时,这个索引器的平方级成本,反而成了拖慢速度的元凶,甚至反而比真正的注意力计算还耗时。
基于此,研究团队开始思考一个问题:能否在不改变最终稀疏注意力结果的前提下,降低索引器的搜索成本?
于是,他们提出了HISA(分层索引稀疏注意力),核心思路也很简单:
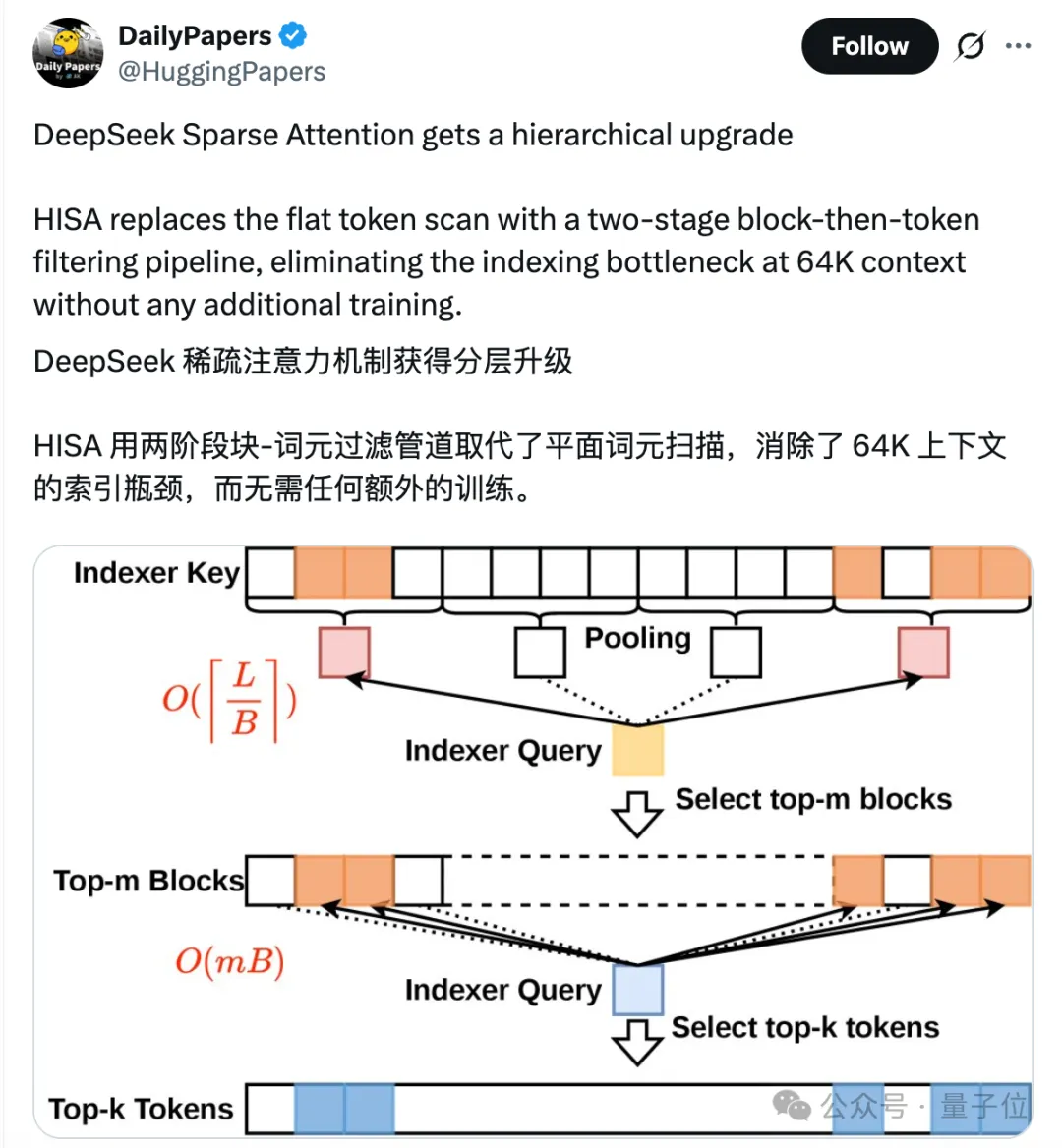
既然挨个打分太费时间,那就先按块筛掉大部分无关内容,再在剩下的小块里精细选。
在功能逻辑上实现对原有模块的等价替换,无需修改后续注意力计算逻辑,相当于 “换了个更高效的筛子,筛出来的东西几乎没变”。
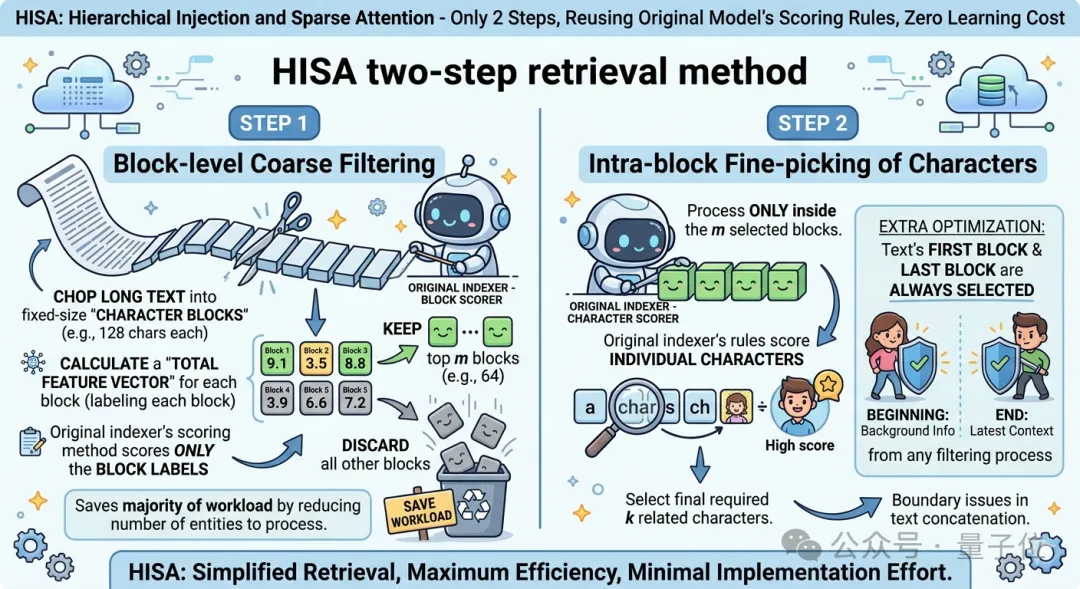
具体就两步,全程复用原模型的打分规则,零学习成本:
第一步,块级粗过滤。
把长文本切成固定大小的 “字符块”(比如128个字符一块),给每个块算一个 “整体特征向量”(相当于给每块贴个总标签);
用原索引器的打分方式,只给这些块标签打分;
挑出分数最高的m个块(比如64个),直接扔掉剩下的所有块——块的数量远少于字符数。
这一步能省掉绝大部分工作量。
第二步,块内精挑字符。
只在第一步选出来的m个块里,用原索引器的规则给单个字符打分,再挑出最终需要的k个相关字符。
还加了个小优化:文本的第一个块和最后一个块必选,保证开头的背景信息、结尾的最新上下文不被误筛,也能处理文本拼接的边界问题。
HISA的关键优势在于:复杂度骤降,还能 “无缝替换”。
HISA把原索引器每一层 O (L²) 的算力成本,降到了O(L²/B + L×m×B)(B 是块大小、m 是选的块数)。
文本越长、块选得越精准,提速效果越明显。
更重要的是它的工程友好性:
输出和原索引器完全一致,下游的注意力计算模块不用改;
不用重新训练模型、不用调整KV缓存结构,直接替换原索引器就行;
短文本时会自动 “退化” 成原方法,只有超长文本时才触发分层筛选,全程自适应。
实测提速超猛,精度几乎没丢
论文在DeepSeek-V3.2、GLM-5两大主流大模型上做了全面测试,结果很亮眼:
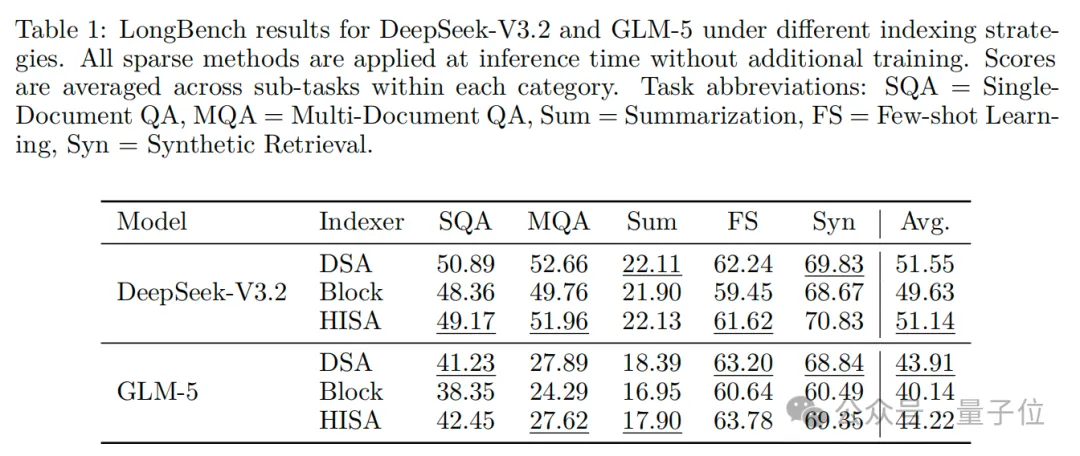
速度上,在64K长度的文本下,HISA 比原DSA索引器最高提速3.75倍,常规设置也能提速2倍多。
上下文长度越长,HISA的提速效果越显著,完全契合超长上下文(128K/1M) 的实际应用需求。
精度上,HISA也几乎完全保留原DSA的精度,且显著优于纯块稀疏方法。
论文进行了“大海捞针”测试,该测试衡量在超长无关文本中,精准检索指定位置关键信息的能力。
结果HISA和DSA几乎一样准,在所有长度和插入深度下,检索精度均接近DSA的近乎满分。