英伟达给机器人装上龙虾大脑量子位
Harness(驾驭)的风,终究还是从大模型,吹到了机器人!
刚刚,英伟达开源了一个全新的机器人操控框架——CaP-X。
基于这一框架,机器人能盯着摄像头看懂环境,然后现场写一段Python代码来控制自己。
关键,这还不是一次性的。如果某段代码成功完成任务,它会被自动存进技能库,而且适用于不同本体、形态的机器人系统。
最离谱的是,这一框架还能把具身大模型(比如VLA)当作API来用,直接一个大脑harness各类小脑(感知与控制)。
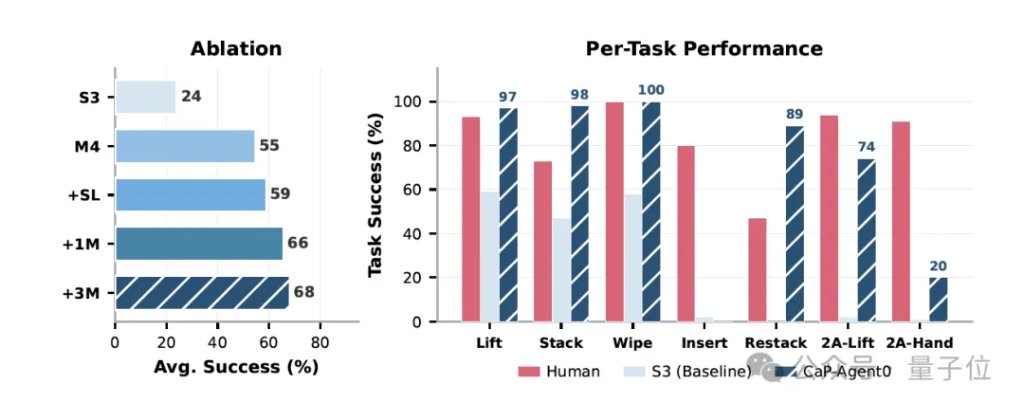
在实测表现中,基于这一框架打造的CaP-Agent0,在7项核心任务中,有4项成功率追平甚至超过人类专家手写程序。
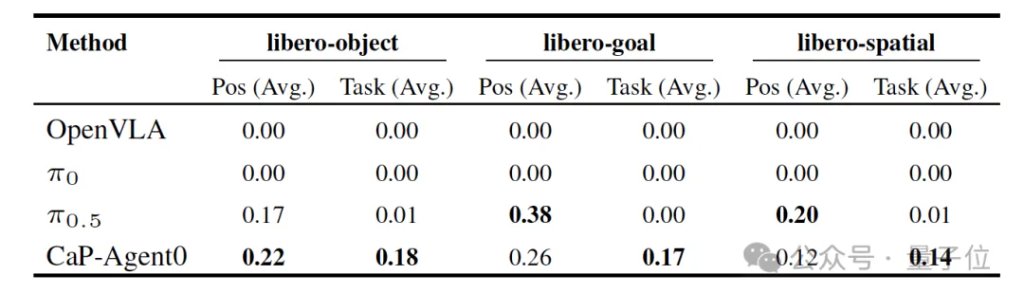
即便面对OpenVLA、Pi系列等基于预训练的端到端大模型,CaP-X这种“靠逻辑取胜”的方案也展现出了旗鼓相当、甚至更领先的性能。
英伟达机器人总管Jim Fan直接下结论:
智能体机器人(Agentic robotics)的时代,来了!
如果说Harness之于大模型,是把引擎装进一辆车;
那么CaP-X之于机器人,就是让这台引擎学会了根据路况自己写驱动程序,并随时给自己升级“代码外挂”。
这一框架的发布,标志着机器人领域正式迎来了属于自己的“Harness”时代。
对此,UCB教授Ken Goldberg评论道:
对机器人「代码即策略」(CaP)的前景感到非常兴奋!
从“人工脚手架”到“代码即策略”
要理解CaP-X在做什么,咱们先简单回顾一下当前机器人控制的主流做法。
在传统的机器人控制中,工程师得逐行编写感知、规划和反馈逻辑(比如经典的TAMP框架),也就是所谓的Human-in-the-loop(人工干预)。
这种方法虽然精准透明,但泛化性极差——经常是“换个杯子,代码重写”。
后来,受到大模型Scaling Law的启发,机器人领域开始采用基于数据驱动范式的、端到端的视觉-语言-动作(VLA)模型。
在过去的一年里,VLA 架构(视觉-语言-动作)战绩斐然,机器人开始能叠衣服、干杂活。
但问题在于,VLA是个“黑盒”,一旦出错很难调试,而且遇到新任务还得重新收集数据训练。
也就在最近,受到龙虾(OpenClaw)、Claude code等一系列编程智能体进展的启发。
研究人员开始思考,能否用Gemini、GPT这样的大模型来替代传统控制中工程师的角色,用Python代码直接调用机器人的接口?
而这,就是CaP-X产生的背景,它让大模型从“发号施令的指挥官”,变成了“能写代码的程序员”。
更进一步,在CaP-X框架里,连VLA策略也只是一个可以被随时调用的 API。
简单来说,以往的VLA是机器人的“全脑”,从看图像到动手指全靠它。但在CaP-X里,VLA变成了代码里的一行函数。
比如,当机器人需要“把盖子拧开”这种极高频、重手感的精细活时,编程智能体不再自己写复杂的几何坐标,而是直接调用VLA,让VLA来执行精细的复杂操作。
就这样,CaP-X用通用的编程智能体取代了人类工程师,配齐了全套的感知和驱动接口,甚至能在干活的过程中自动合成技能库,调用专攻操作的具身模型。
接下来,我们具体来看。
具身智能的Harness
CaP-X本质上不是一个模型,而是一整套驾驭框架,包括:交互式训练环境CaP-Gym、层级化基准测试CaP-Bench、无需训练的智能体框架CaP-Agent0和强化学习进化算法CaP-RL。
CaP-Gym
作为整个框架的核心,CaP-Gym是一个基于标准Gymnasium接口构建的层级化控制框架。
它将数字大脑和物理身体连接起来,大模型每写出一行代码,物理世界(模拟器或真机)就会实时给出反馈。
在框架上,CaP-Gym统一了感知基元与控制基元:
在感知方面,智能体通过模块化的感知基元从环境中获取数据,这些基元将原始传感器数据抽象为结构化的语义对象。
它内置了SAM3(语义分割) 和Molmo 2(点选) 等工具,把原始图像直接变成“这里有一个苹果”、“那里有一个杯子”这种结构化的语义对象。
在控制方面,智能体不直接发布关节空间动作指令,而是调用运动规划器或逆运动学(IK)解算器(如PyRoki)自动处理碰撞检测和路径规划。
也就是说,无论是单手抓取、双臂协作还是移动机器人,CaP-Gym提供了一个让大模型能直接在笛卡尔空间里进行“逻辑编程”的交互式沙盒。
CaP-Bench
在CaP-Gym的基础上,研究还推出了CaP-Bench,用来衡量模型能不能“驾驭”机器人。
它专门用来测试当模型被推到第一线去“写动作代码”时,它的代码质量、逻辑严密性以及面对物理反馈时的纠错能力到底如何。
CaP-Bench主要从三个维度进行测试:
抽象层级(Abstraction Level): 将动作空间从人工设计的宏命令(高层)转变为原子级的基本基元(底层);
时间交互(Temporal Interaction): 对比零样本单轮程序生成与多轮交互,以量化故障恢复和迭代推理能力;
感知落地(Perceptual Grounding): 评估不同形式的视觉反馈如何影响智能体将任务相关的视觉特征转化为代码生成的能力。
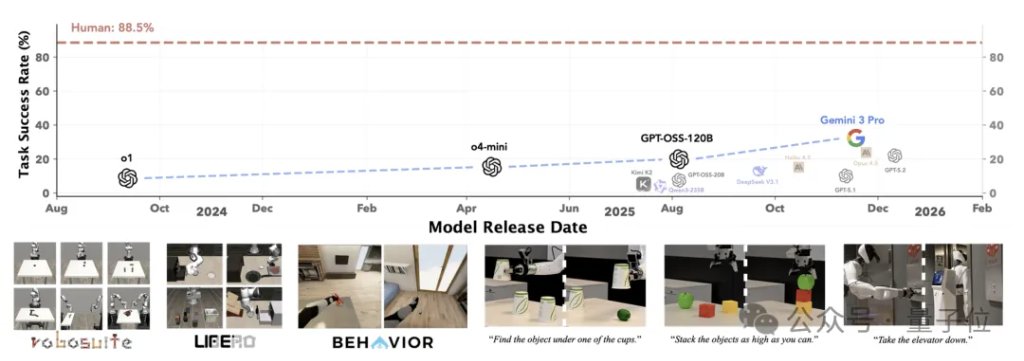
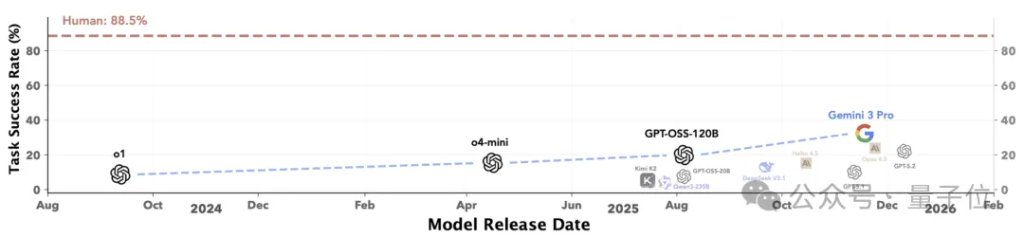
在对12个最先进的大模型(包括 OpenAI o1、Gemini 3 Pro 等)进行单轮盲测后,结果表明:
随着人类先验(脚手架)的移除,所有前沿模型的性能断崖式下跌,没有一个能在底层基元上达到人类专家的零样本成功率。
这证明了:如果没有好用的接口,目前强如GPT、Gemini 3 Pro的模型,在底层动作逻辑面前依然会“抓瞎”,离人类专家的水平还差得远。
CaP-Agent0
基于CaP-Bench的失败模式与经验,研究又进一步推出了CaP-Agent0。
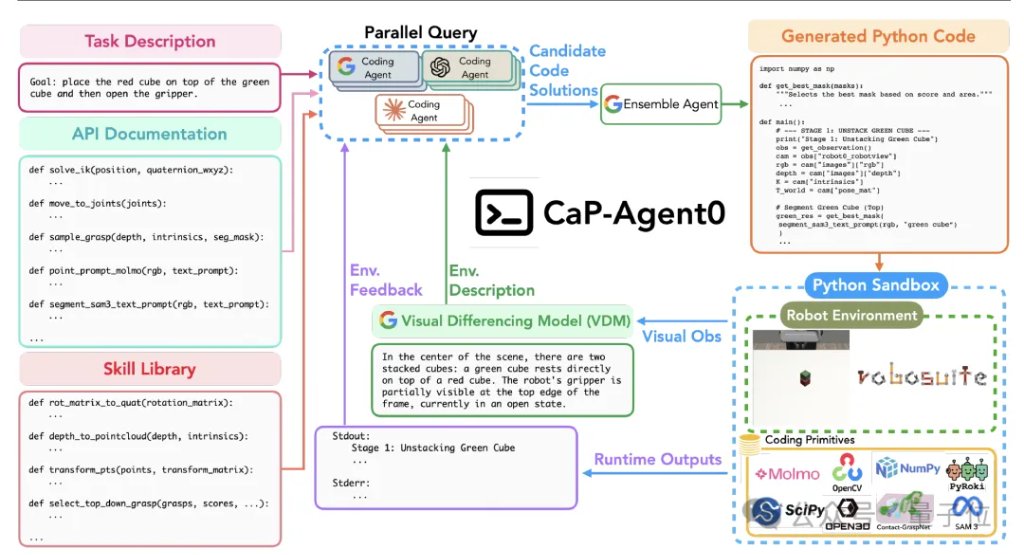
CaP-Agent0通过专门的多轮推理循环和动态合成的技能库增强了基础模型,核心组件如下:
多轮视觉差异比对(VDM): 模型直接看原始图像往往会“瞎”,VDM能将前后帧的视觉差异转化为结构化的自然语言反馈,智能体再基于语言反馈进一步修改代码。
自动合成的持久化技能库: 当模型在底层瞎摸索偶然成功后,CaP-Agent0会自动提取这段成功的代码,封装成一个可复用的“技能(Skill)”。随着尝试的增多,它自己攒出了一个庞大的技能库,把复杂问题越做越简单。
并行集成推理: 遇到难题,同时生成多种方案并行尝试,在每一轮中,同时采样多个候选方案。
此外,团队还推出了CaP-RL,直接利用环境反馈的成功与否作为可验证奖励,用强化学习(GRPO)来后训练编程模型本身,让它的写码直觉越来越准!
如开头所说,在CaP-Bench的7项核心任务中,即便剥离了所有高级接口、只给最底层的原子基元,CaP-Agent0依旧表现优异。