南大终结「肉身排雷」:别再炼丹新智元
具身智能正站在一条分界线前:VLA的下一步,靠模仿学习已经越来越难撑起来了。一篇南大重磅论文再次瞄准「世界模型」,让机器人先在脑中练会再上手,少在真机上「交学费」。
刚刚出炉的一篇论文《Towards Practical World Model-based Reinforcement Learning for Vision-Language-Action Models》,把目光重新投向了「世界模型」这条老问题、新战场。
作者给出的判断很直接:机器人并不缺一个更会模仿的模型,缺的是一个能让它安全、高效「先想一遍再动手」的训练机制。
这项工作不只是提出了一个新方法,更切中了当前具身智能里一条越来越清晰的分界线:
VLA下一步的能力增长,还能继续主要靠模仿学习撑起来吗?还是说,机器人终究要拥有自己的「想象空间」?
机器人训练,正卡在「现实世界太贵」上
过去两年,VLA的进展让人很容易产生一种乐观印象:
只要把视觉、语言和动作放进同一个大模型里,再给它足够多的数据,机器人似乎就能越来越像一个「通用体」。
这条路线确实跑出了不少结果。
从OpenVLA到π0系列,VLA模型已经表现出相当强的跨任务泛化能力。
它们能看懂场景,理解人类语言指令,输出连续动作,在一些任务上已经不像传统机器人那样依赖重工程规则。
支撑这波进展的核心训练范式,仍然是模仿学习。
简单说,就是让机器人看大量人类示范,学习「这个画面下该怎么做」。
这件事很符合直觉,也很符合工程现实:
训练过程稳定;
不需要机器人自己乱试;
只要示范足够多,模型能力就能持续堆高。
问题也越来越具体。模仿学习擅长的是「照着做」,不擅长的是「自己摸索更优解」。
现实任务一旦变长、变复杂,或者加入视角变化、环境扰动、失败恢复,单靠示范会慢慢碰到天花板。
示范数据本身也越来越贵:一个人类操作员、一个真实机器人平台、一段高质量轨迹,背后都是成本。
这也是为什么强化学习又重新回到VLA的讨论中心。
强化学习真正吸引人的地方,从来都不是「会试错」这么简单,而是它让系统有机会学到示范之外的策略改进。
很多任务里,专家数据只告诉模型「怎么完成」,强化学习能进一步回答「怎样完成得更稳、更快、更泛化」。
难点出在物理世界。
让机器人做强化学习,意味着它要一遍遍在真实环境里尝试。
插线缆、叠毛巾、擦白板、抓杯子,听上去只是几个动作,训练起来却是巨大的现实开销:
采样速度慢;
机器磨损高;
错误动作存在安全风险;
长程任务常常要靠大量试错才能学到有效信号。
这也是眼下VLA强化学习最尴尬的地方:
大家都知道强化学习能带来增益,也都知道真机试错很难规模化。
世界模型,为什么又成了关键变量
这个背景下,世界模型的意义重新凸显出来。
「世界模型」这个词并不新。
在强化学习领域,它一直对应着一个非常朴素、也非常强大的想法:让智能体先学会预测环境如何变化,再在这个预测出来的环境里练策略。
放到机器人里,世界模型可以理解成一个「脑内模拟器」:
当前看到什么;
执行动作之后会发生什么;
未来画面会怎么变;
任务会不会成功;
奖励会不会出现。
这套能力一旦可靠,机器人就不必把每一次试错都放在真实世界里完成。
它可以先在「想象出来的环境」里训练,再把学到的能力迁移回真实机器人。
这个方向之所以重要,是因为它同时指向了具身智能的三件大事:
成本:真实数据永远昂贵。能在模型内部生成训练数据,意味着同样的硬件预算可以换来更多策略更新。
安全:机器人在现实里做高风险探索并不理想。尤其涉及接触、精密操作和移动平台时,代价不是一两次失败那么简单。
泛化:模仿学习偏向「复现已有行为」,世界模型强化学习有机会让机器人学会「如果这样做会怎样」,这类因果式的能力,往往更接近真正的泛化基础。
也正因为此,世界模型长期被视为通向更强具身智能的一条主线。
VLA与世界模型
这场争论本质上在争什么
现在的机器人研究里,有一条潜在分歧越来越明显。
一条路继续押注纯VLA/模仿学习。
这条路线的核心信念是,随着模型规模、数据规模、预训练能力继续上涨,机器人对「视觉-语言-动作」的统一建模会越来越强。很多难题最终可以交给更大的模型和更多的真实数据去解决。
另一条路则在强调世界模型。
它不否认大模型的价值,反而把它当成前提。只是在此基础上,它认为机器人最终不能只会「看到输入就输出动作」,还要具备某种内部模拟能力。换句话说,机器人不能只学会答案,还要学会预判后果。
这场分歧很容易被理解成「谁对谁错」,其实更接近一个发展阶段问题。
纯VLA的成功已经证明:大模型能够显著提升机器人理解世界、响应指令和跨任务迁移的能力。
世界模型路线反复遇到的问题也是真实存在的:一旦模型预测不准,后面的强化学习就会被错误信息带偏,长程推演里误差越滚越大,最后在论文图里看着热闹,在真实机器人上并不稳定。
这篇论文真正重要的地方,恰恰就在这里。
它没有试图否认VLA的价值,也没有把世界模型神化成万能钥匙。
作者做的是另一件更务实的事:把世界模型真正嵌进VLA的后训练流程里,并把最容易失控的几个环节逐个处理掉。
世界模型放到VLA上,难点比想象中大得多
很多人第一次听到「世界模型」,直觉会把它理解成视频生成:给定当前画面,预测下一段画面。
对机器人来说,这远远不够。
像素预测不是重点,关键是「能不能拿来控制」
VLA直接吃图像输入,意味着世界模型必须在像素层面生成未来观测。
这看上去像生成问题,本质上却是控制问题。
插头有没有对准插孔,机械臂末端偏了几毫米,毛巾是不是被正确翻折,腕部相机里看到的接触状态是不是和头部相机一致,这些都不是「画得像」就能过关的事。
它要画得对,而且是对控制有用的那种对。
多视角一致性是机器人特有的硬约束
机器人常常同时依赖多个摄像头。
头部相机看全局布局,腕部相机看近距离细节。
精细操作里,后者几乎不可或缺。问题也因此变得棘手:如果未来的不同视角是分别生成的,它们很容易各自合理、彼此矛盾。
头部视角说机械臂已经靠近物体,腕部视角还停留在远处;头部视角里毛巾被抓起,腕部视角里接触关系却对不上。
这类不一致,对机器人策略来说比模糊还危险。
模糊意味着信息少,矛盾意味着信息错。
长程推演的误差,会在稀疏奖励下被放大
世界模型最经典的问题是误差累积。
第一步偏一点,第二步在「偏了一点的世界」里继续预测,第三步偏差再放大。长程任务做下来,生成轨迹和真实环境之间很快就会分道扬镳。
VLA场景下这件事更难,因为很多机器人任务都是稀疏奖励。
毛巾叠好了没有,插头插进去了没有,白板擦干净了没有,常常只有成败两种判断。
这意味着很小的视觉偏差,就可能把一个状态从「成功」翻成「失败」,或者反过来。强化学习如果用的是这种被翻转的奖励,后果可想而知。
这也是为什么过去一些世界模型方法虽然思路很漂亮,真正落到机器人上时,效果常常局限在短任务或比较受控的环境里。
不把参数做更大
而把世界模型做得更能用
论文提出的方法叫VLA-MBPO。从名字就能看出作者的目标很明确:不是做一个概念性的世界模型,而是做一个能实用的、适合VLA强化学习后训练的世界模型框架。
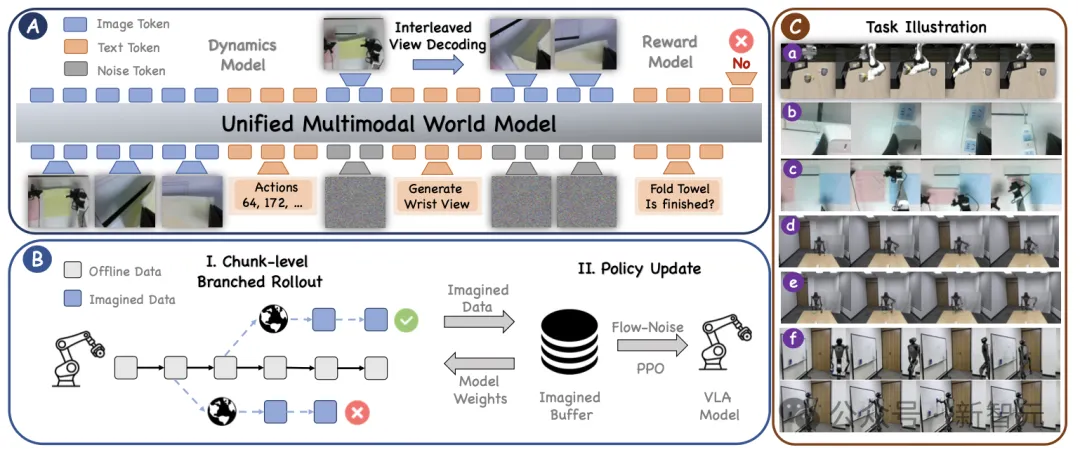
整套方法可以放在论文图1中理解。
图1. VLA-MBPO架构
它有三个关键设计,分别对应前面提到的三类现实难点。
统一多模态世界模型:预测未来观测和奖励
过去一些方法会把「未来画面预测」和「奖励判断」分成两套系统:一个模型负责动力学,另一个模型负责根据图像判断任务是否完成。
这种设计并非不能用,只是系统复杂、部署开销大,速度也未必理想。
VLA-MBPO采用的是一条更干净的路线:直接用统一多模态模型(Unified Multimodal Model, UMM)作为世界模型骨干,把视觉、文本和动作统一到一个模型里,让它一起完成未来观测预测和奖励预测。
作者在实现中使用了Bagel作为基础模型,并把连续动作离散成token序列输入模型。这样一来,世界模型接收的信息就不再只有图像和文本,还能直接读入机器人动作切块。
这件事很实际。
一方面,UMM能直接利用预训练多模态模型已有的视觉语义能力。机器人场景的数据规模远远比不上互联网图文数据,能借到的先验越多,越容易在少量离线数据下泛化。另一方面,统一建模省掉了「两套大模型并排跑」的工程负担。模型不需要先用视频世界模型滚出一段未来,再单独把图像丢进另一个视觉语言模型里判定奖励。
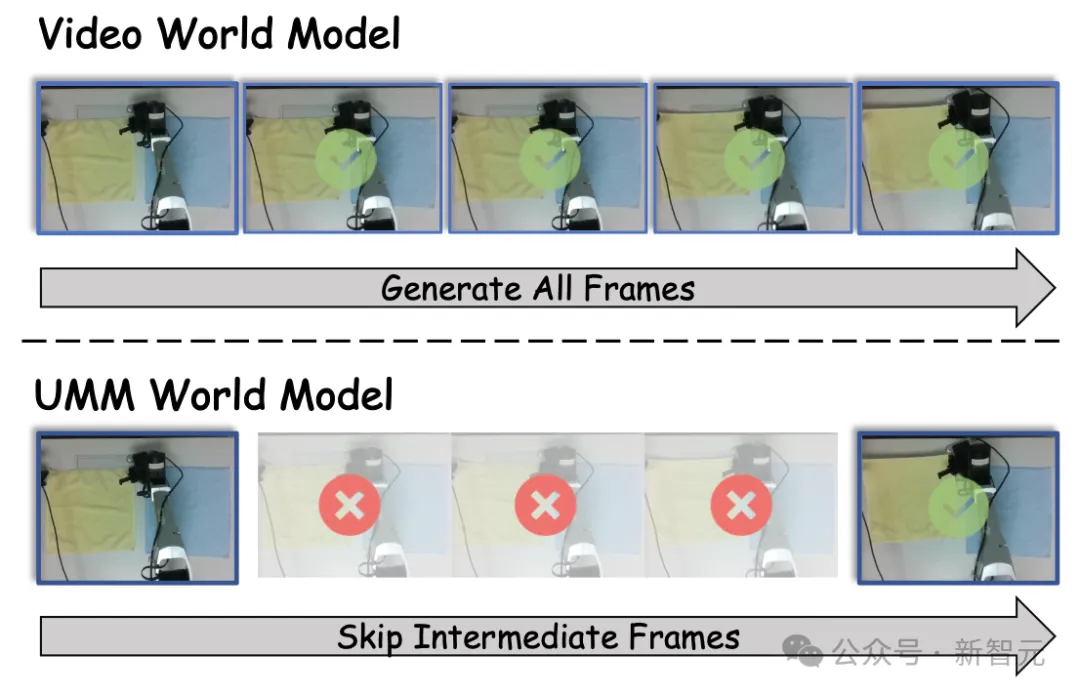
论文还特别强调了一个效率优势。
传统视频世界模型往往要生成所有中间帧,作者的UMM-World可以跳过中间帧,直接预测动作切块之后的未来状态。图2给出的就是这一路线和视频模型思路的直观对比。
图2. UMM可跳过中间帧,直接预测动作切块之后的未来状态