罗福莉一场“伏击”,让雷军腰杆硬起来了蓝鲸新闻
3月19日,小米新一代SU7发布会如期举行。雷军站在聚光灯下,神态笃定,言辞从容。这份底气,并非只来自新SU7。真正的惊喜,还来自另一条战线。前DeepSeek工程师、现小米大模型团队负责人罗福莉,带领团队在大模型领域完成了一场“悄无声息的伏击”。
当日晨间,雷军通过个人社交媒体对外发布了Mimo-v2-Pro模型降临的消息。此前在OpenRouter悄然出现的两款匿名模型亮明身份,其中代号“Hunter Alpha”的模型调用量一度登顶日榜,累计突破万亿次。OpenClaw创始人Peter Steinberger曾在X平台上公开溯源询问,如今得到了雷军的正式回应。
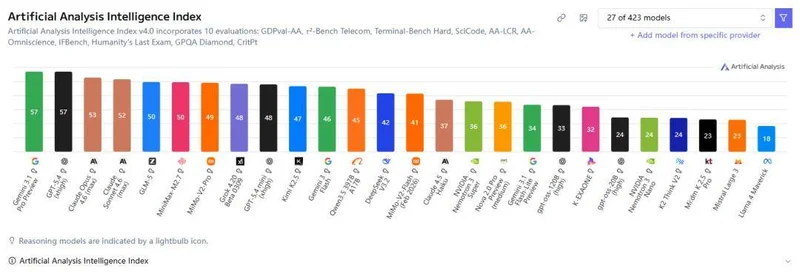
两款模型迅速登上Artificial Analysis排行榜,在智能水平与代理能力两个维度上均进入国产模型前列。在AI开发者社区,小米以一种出人意料的方式完成了“后来者居上”的亮相。
然而,也有开发者实测指出,MiMo-V2-Flash存在“输出无限循环”的偶发问题。更关键的质疑来自基准测试本身:OpenAI Frontier Evals团队曾明确指出,小米引以为傲的SWE-bench Verified“实际上已经饱和且高度被污染”,建议行业转向更难的SWE-bench Pro。这意味着,部分亮眼数据需要在更严格的测试框架下重新验证。
罗福莉也在发布声明中直言,“会开源——当模型足够稳定值得开源的时候”。言下之意,眼前的MiMo-V2-Pro尚未达到她心中“值得开源”的标准。雷军的表态同样坦诚:“我们模型刚刚完成,未来一段时间,还会快速迭代增强。”这既是对外界的承诺,也是对现状的坦率承认——MiMo-V2-Pro确实还有不少短板需要弥补。
但瑕不掩瑜的是,MiMo-V2-Pro真正经得起审视的,是ARL-Tangram这项系统级创新。它才是罗福莉这场伏击的真正杀招,也是雷军腰杆挺直的底气所在。
01 MiMo-V2-Pro的最大亮点
为了让大语言模型具备在真实世界中执行任务的能力,罗福莉带领的研究团队做出了一个极其准确的判断:
针对智能体的强化学习是不可或缺的核心技术。
与大语言模型不同,要想训练这些更聪明的智能体,就必须让它疯狂调用外部资源,比如用CPU跑代码、用GPU跑奖励模型打分,甚至是消耗海量的外部搜索引擎API配合。
毫无疑问,结果必然伴随指数级增长的成本。
但研究团队却在这个过程中发现了一个问题:
现有的AI系统面对这些复杂的需求时,往往采用简单粗暴的“过度资源配置”,算力浪费甚至高达70%以上。
为了打破这个瓶颈,研究团队提出了一项系统级创新,名为ARL-Tangram。
在这个系统中,“动作级编排”这个概念令人眼前一亮,它能将外部资源分配的粒度细化到极致,不仅能让动作完成时间(ACT)提速4.3倍,还能节省71.2%的外部算力资源。
更重要的是,它不是只停留于实验室的想法,而是已经在小米MiMo两款新模型的训练中实际落地的策略,商业化价值初步显现。
02 走上牌桌的“智能体强化学习”
在细聊ARL-Tangram这项技术之前,首先得了解“智能体强化学习”这个概念。
一般来说,强化学习此前针对的都是大语言模型(LLM)的训练过程,传统LLM训练主要在GPU集群内闭环完成。
但是,现在人们已经不需要一个网页中的聊天助手,而是需要一个能操控设备的“数字牛马”。
智能体应运而生,它的底层是大语言模型,自然也需要类似的训练过程。
在采样展开(Rollout)阶段,模型需要不断地与Shell命令、Python解释器、搜索引擎API等外部工具和真实环境交互。
为了完成一项复杂的任务,与外部环境进行的“多轮交互、反复试错”这一系列环节被定义为轨迹。整条轨迹结束后,还需要调用奖励模型来进行打分。
因此,智能体强化学习的训练过程,高度依赖于大语言模型训练集群之外的异构外部资源。
而现有的开源强化学习框架在处理这些外部资源的分配问题时,往往采用的是“宁滥勿缺”的过度配置策略,这在两个层面上同时造成了算力的“黑洞”:
一是轨迹内的过度配置。
为了保证智能体在“反复试错”的过程中能够保证环境隔离,现有的系统大多会在一条执行轨迹的整个生命周期内,为它锁定一块专属的硬件资源。
论文中的实测数据更是超乎所有人的设想:在AI编程任务中,智能体真正在运行代码的时间平均只有47%。
而剩下53%的时间,底层的大模型正在思考或生成下一步的代码,但此时被强制占用的CPU资源完全处于闲置状态。
二是任务内的过度配置。
到了奖励模型打分的阶段,情况变得更加严重。
不同的强化学习任务一般需要调用不同架构的参数的专属奖励模型,为了保证打分的低延迟,开发者往往会为每一个奖励模型挂载多张昂贵的GPU。
但在强化学习训练的全过程中,这些奖励模型大多时间都处于“零请求”状态。
实测数据显示,在某个业务线并行的12个奖励模型所在的GPU集群,流式多处理器的平均活跃度连3%都不到。
英伟达的“卡脖子”越来越紧,宝贵的算力被霸占却空无产出,烧钱的同时,延迟和并发吞吐量也被限制,从商业角度看,这完全是不可接受的事实。
03 ARL-Tangram与动作级调度
为了解决这种无意义的资源浪费问题,小米的研究团队试图通过将任务流程进一步细分来优化资源分配,也就是所谓的“动作级调度”。
类似于化学中分子和原子的概念,一个“动作”指的就是底层大模型与外部资源进行的一次不可分割的交互。
它可以是执行一行Python代码,也可以是向Google发起一次网页查询API。
在这些动作的发生期间,大模型本身无需生成任何文本,只是纯粹在等待外部环境给出执行结果。
ARL-Tangram的核心逻辑很简单:既然大模型只有在这个瞬间才需要外部资源,那就只在这个瞬间给大模型分配资源。
不得不说,小米的研究团队很会给技术起名,Tangram就是七巧板的意思,而这套系统恰好能像七巧板一样灵活地拼装和调度资源。
按照这个理念,ARL-Tangram的核心操作一共有两项:
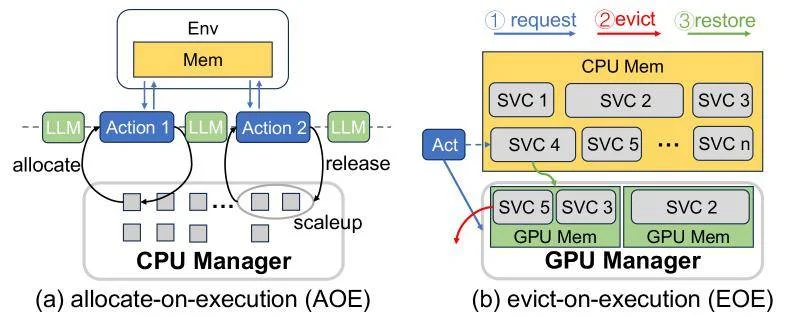
一是拆解(Breakdown):打破长生命周期环境对物理资源的持续占用。
只要一个动作执行完毕,系统马上把CPU和GPU资源抽走并释放,同时保留环境的上下文状态,等下一次动作来临时再恢复。
二是池化(Pool):将所有释放出来的闲置资源放进一个全局统一的资源池中。
智能体的实际应用过程中往往有海量的动作并发到来,系统会根据排队情况,弹性地按需分配资源给最需要的动作。
04 ARL-Tangram的核心架构
理念简单而美好。但要在复杂的GPU集群中跑通这套逻辑,就会有很多工程挑战摆在眼前:
智能体要求动作执行时间极短、资源类型复杂多样、环境状态需要瞬间保存和恢复。
为此,研究团队为ARL-Tangram设计了三个核心组件:
①统一的动作建模(Unified Action Formulation)
面对CPU的内核、GPU的显存、搜索引擎网站的API调用次数这些截然不同的物理资源,要想在同一个队列内进行统筹调度,就必须有一个统一的度量方法。
ARL-Tangram的方法是将每一个动作的资源成本都抽象为一个多维向量。
更重要的是,它还引入了弹性建模技术。
系统会自动识别哪些动作具备弹性:例如,4个CPU核心运行测试用例需要10秒,而16个CPU核心只需要3秒,这就为后续的动态智能调度提供了明确的数学依据。
②弹性资源调度算法(Elastic Resource Scheduling)
智能体运行的过程中,调度时间只有几毫秒,面对海量并行而来的动作,算法必须在此期间最小化所有排队动作的总体完成时间(ACT)。
系统采用的是一种基于“贪心驱逐(Greedy Eviction)”的轻量级启发式算法。
简单来说,面对一大堆正在排队的动作,调度器首先实现“保底”,给每个候选动作分配仅能满足其运行的最小资源。
然后,算法会贪婪地尝试从队列末尾的动作手中“抢走资源”,并把这些资源加码分配给排在队列前面的具备弹性的动作。
如果经过计算,这种“集中力量办大事”的方法能够让总体等待和执行时间变得更短,那就毫不犹豫地立刻执行。
③异构资源管理器
调度机制已经清晰,接下来就该处理底层硬件资源的落地问题了。
ARL-Tangram针对CPU和GPU集群,研发了一套专用的底层管理机制: