一文读懂GTC 2026:给“龙虾”装安全围栏腾讯科技
北京时间3月17日凌晨,英伟达(股票代码:NVDA)GTC2026大会拉开帷幕。作为全球AI产业最受关注的年度时刻之一,GTC大会被称为“AI春晚”,其中黄仁勋的主题演讲亦备受关注。
大会之前,黄仁勋抛出过一个产业模型为GTC预热,指出“AI是一块五层蛋糕(AI is a Five-Layer Cake)”,从底座向上分别为:能源、电力,芯片、算力基础设施,再到模型与应用,AI已经形成一个全新的产业技术栈,并正在引发人类历史上规模最大的基础设施建设之一。
黄仁勋说:“这次大会将覆盖人工智能五层架构的每一层,当然还有最重要的一层,也是最终真正推动这个行业腾飞的——应用。”
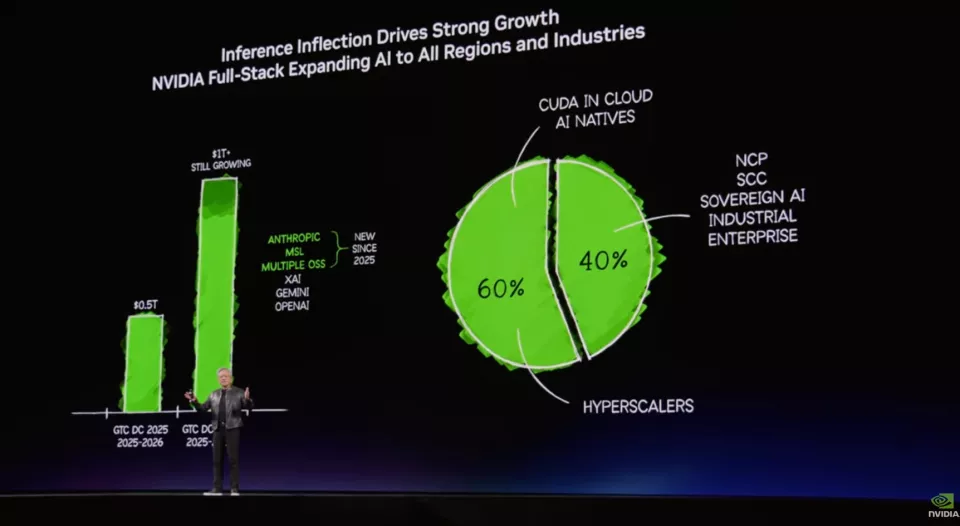
黄仁勋指出,随着推理需求的爆发,正在推动英伟达的市场规模和客户结构同步扩张。
回望2025年10月的华盛顿GTC大会,黄仁勋曾指出,到2026年底,英伟达凭借现有及未来的数据中心芯片,将撬动约5000亿美元的收入规模。
这次GTC的演讲台上,老黄再次给出预判:几个月后,随着 Blackwell与Rubin架构的全面接力,他所预见的市场机会已翻倍跨越。他明确表示,预计到2027年底,英伟达新一代AI芯片的累计营收将正式跨入1万亿美元时代。
本次GTC 2026发布的最核心主题——以Vera Rubin为代表的“芯片全家桶”,构成了这一代Vera Rubin机架的系统级基础设施,其中包括:Vera CPU、Rubin GPU、NVLink 6 Switch(高速互联)、ConnectX-9 SuperNIC(超级网卡)、BlueField-4 DPU(数据处理单元)、Spectrum-6 以太网交换机。
英伟达甚至还准备将AI算力“送上天”,推出面向轨道环境运行的Vera Rubin Space Module,用于支持卫星和空间任务中的边缘智能计算。
值得注意的是,此次GTC,Groq 3 LPU推理加速器也完成了首秀。
此前,2025年12月,英伟达以约200亿美元完成了对Groq核心技术资产的收购,Groq创始人Jonathan Ross加入英伟达担任首席软件架构师,Groq 3 LPU正是这笔收购正式落地的第一个公开成果。
另外,席卷中美两地开发者社区的“龙虾热”,在本次GTC上也得到了体现。
黄仁勋推出面向OpenClaw生态的NemoClaw方案,在OpenClaw原有智能体能力的基础上,叠加了NVIDIA Nemotron开放模型,可以让龙虾更聪明,同时内置一套实时安全管控机制,相当于给智能体配了一个全程在线的“保安”。
整个2个多小时下来,英伟达GTC给人“系统级”概念印象非常深刻:早期突出的是算力、互联,到最近两年强化对系统级能力,甚至是AI工厂这种综合型基础设施的探索,所以大家会看到,黄仁勋在大会上已不再是单纯强调单一的算力芯片,取而代之的“芯片全家桶”、“算力全家桶”这种系统级解决方案。
01. Vera Rubin 平台:推理效率提升10倍,token成本降至十分之一
早在2024年Computex上,黄仁勋就首次披露了Rubin架构,并宣布其将接替Blackwell 成为下一代AI GPU架构。随后在2025 GTC上,展示了搭载Vera CPU与Rubin GPU的Superchip原型,但当时仍停留在单板级产品阶段。
2026年CES,Rubin首次以完整平台形态出现,由六颗核心芯片协同工作,构成一台机架级AI超级计算机。
而在本次GTC 2026上,英伟达又进一步将Groq的LPU推理架构整合进平台,并首次将AI工厂、电力调度与智能体运行环境纳入统一架构。
Vera Rubin平台主要芯片和组件包括Vera CPU、Rubin GPU、NVLink 6 Switch、ConnectX-9 SuperNIC、BlueField-4 DPU、Spectrum-6 Ethernet switch,也包含了新整合的 Groq 3 LPU,组成一台超级 AI 计算机。
相当于把过去只有超大型科技公司才能搭建的AI超算能力,做成了一套可直接部署的标准机架。既能训练更大的模型,也能让AI像人一样持续工作、更低成本地处理复杂任务。
黄仁勋表示:“Vera Rubin NVL72机架:集成72颗Rubin GPU和36颗Vera CPU,通过NVLink 6高速互联。相比上代Blackwell平台,NVL72训练大型混合专家(MoE)模型所需GPU数量仅为四分之一,推理吞吐量/瓦特提升高达10倍,单token成本降至原来的十分之一”。
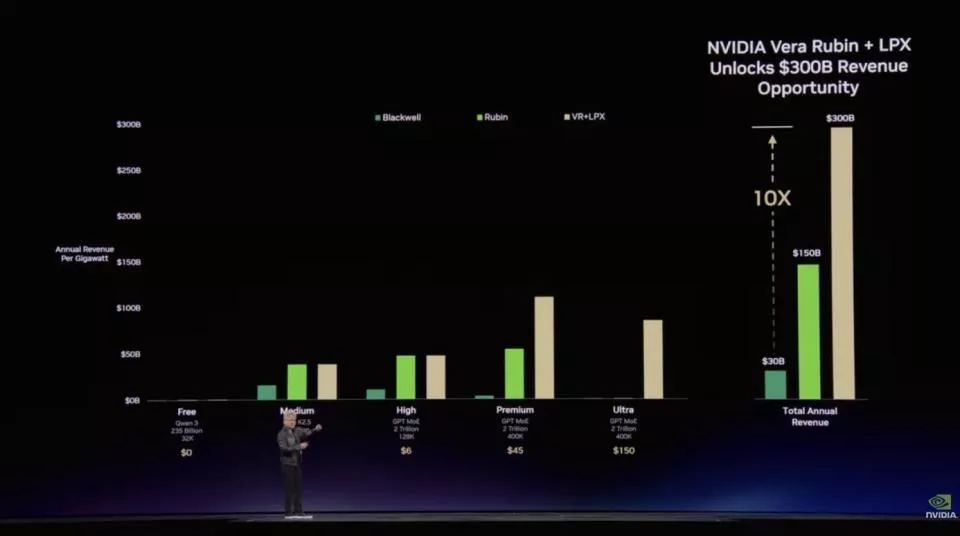
黄仁勋指出,Vera Rubin架构与LPX软件平台的深度协同,将通过单体算力价值的10倍跃升,开启高达3000亿美元的年收入机遇。
02. Vera CPU:专为 Agentic AI 打造的新一代处理器
英伟达正式发布了自研Vera CPU。
黄仁勋表示,这是全球首款专为“AI 智能体时代”与“强化学习”设计的处理器。该芯片搭载88颗自研Olympus核心,性能较传统CPU快50%,能效提升达 2倍。
Vera CPU更像是智能体系统背后的“指挥与调度中心”。因为进入AI智能体时代后,很多工作并不只是生成答案,还需要同时管理大量并发任务,例如运行强化学习环境、调用外部工具、执行代码、校验数据结果。这类复杂的编排任务对CPU的单线程性能和带宽提出了前所未有的要求。
也正因为如此,Vera CPU的设计重点不只是单纯提升算力,而是让大量AI环境能够同时稳定运行,基于NVIDIA 空间多线程(Spatial Multithreading)技术,每颗核心可同时处理两个任务,确保了大规模AI服务的响应速度。
Vera CPU采用LPDDR5X内存,带宽高达1.2TB/s,是同类通用CPU的两倍,功耗仅为一半。结合NVLink-C2C技术,其与GPU间的互联带宽达1.8 TB/s,是传统PCIe Gen 6的7倍。
单个 Vera CPU机架可集成256颗液冷方案Vera CPU,支持超过22500个并发线程独立满负荷运行,专为大规模“AI工厂”而生。
据介绍,目前已计划部署Vera CPU的云客户包括:Meta、Oracle Cloud、CoreWeave 等;制造合作商涵盖戴尔、HPE、联想、超微电脑、华硕、富士康等。Redpanda 的测试显示,Vera在处理实时数据流时的延迟降低了 5.5倍。相关产品预计将于2026年下半年上市。
03 Groq 3 LPX/LPU:填补GPU推理短板,超低延迟推理加速器
Groq 3 LPU芯片是英伟达专为极致低延迟推理设计的全新处理器。
在AI智能体时代,推理侧需求正加速分化:大模型训练依赖GPU的高吞吐算力,而面对需要极高交互性、超短响应时间的智能体任务,传统GPU架构存在性能冗余。为此,英伟达正式引入LPU架构,专注于“极致低延迟的token生成”。
在硬件设计上,Groq 3 LPU芯片展现了与传统GPU截然不同的技术路线。它摒弃了容量大但延迟相对较高的HBM显存,单颗芯片集成了500MB的片上SRAM。虽然容量仅为Rubin GPU 的五百分之一,但其提供的带宽高达150 TB/s,是HBM4(22 TB/s)的近7倍。
基于该芯片,英伟达推出了Groq 3 LPX平台(机架)。该平台采用液冷散热,单个机架配备 256颗LPU处理器,累计提供128GB片上SRAM,总扩展带宽达640TB/s。LPX平台作为Vera Rubin架构中的关键补齐,专注于承载大规模、高并发的低延迟推理工作负载。
当Groq 3 LPX平台与Vera Rubin NVL72结合使用时,这种混合架构实现了GPU强劲算力与 LPU极致带宽的完美互补。在百万token上下文场景下,其收益潜力可大幅提升。 该芯片及平台预计将于2026年下半年正式上市。
04 Vera Rubin Space Module:AI 算力飞向太空
英伟达这次还把AI算力直接送上了太空,发布了专门面向轨道数据中心(ODC)和太空操作的 Vera Rubin Space Module。
根据介绍,传统卫星的工作模式是拍摄后将海量数据下载到地面处理,但这套流程正被“数据洪流”压垮。因为一颗地球观测卫星每天可产生数TB数据,而星地通信带宽有限、窗口期短,大量数据积压等待传输。从拍摄到分析结果返回可能耗时数小时,错过灾害预警等场景的黄金窗口。
Vera Rubin Space Module 的核心思路是边缘智能,让卫星在轨完成目标检测和变化分析,只下传有价值的结果而非原始数据,从而大幅降低传输压力。
英伟达表示,目前,像Axiom Space、Planet Labs这些太空赛道的头牌公司,已开始用英伟达的加速平台来跑下一代太空任务了。有了这种算力加持,无论是卫星自主运行还是地理空间智能分析,都将从“慢动作”变成实时响应。
黄仁勋表示:“相比H100 GPU,Rubin Space Module在太空推理算力上提升最高25倍,真正将数据中心级AI算力带入太空”。