当AI第一次读完整本基因之书:能干什么?新智元
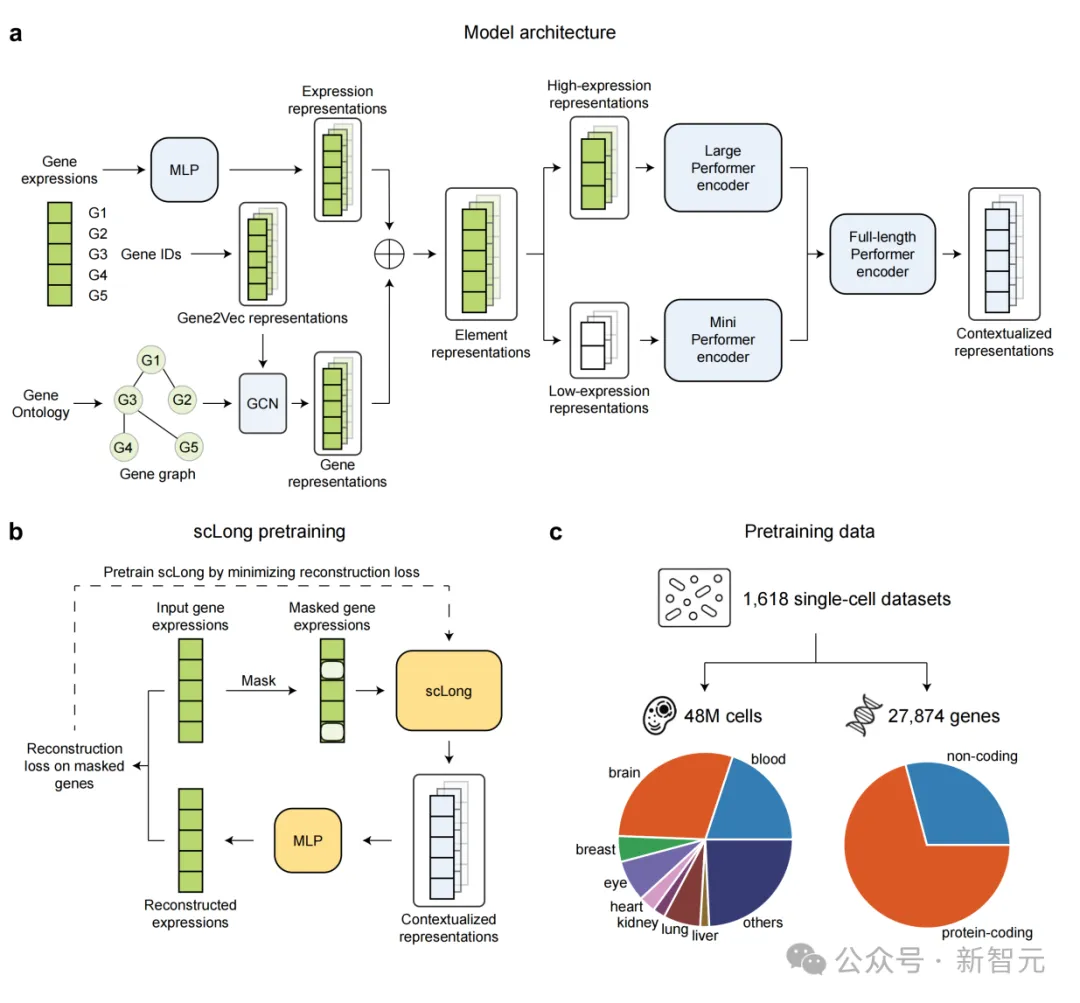
十亿参数单细胞基础模型scLong不再只看少数高表达基因,而是把一个细胞里接近 2.8 万个基因 都纳入建模,并结合 Gene Ontology(GO) 的生物学知识,去理解更完整的基因上下文。
在单细胞转录组学领域,研究者希望从每个细胞的基因表达中读出细胞状态、调控关系,甚至预测当某个基因被敲除、某种药物被加入后,细胞会发生什么变化。
过去几年,foundation model(基础模型)开始进入这一领域,显示出强大的迁移能力;但长期以来,现有方法往往为了节省计算,只关注少量高表达基因,忽略了大量低表达甚至零表达基因,同时也缺少对外部基因功能知识的系统整合。这不仅会丢失重要调控信号,也容易让模型对复杂生物过程「只见树木,不见森林」。
近日,MBZUAI、加州大学圣地亚哥分校(UC San Diego)等机构联合团队在 Nature Communications 发表研究成果scLong。
论文链接:https://www.nature.com/articles/s41467-026-69102-y
这是一种拥有10亿参数的单细胞基础模型,基于约4800万个细胞进行预训练,能够在整个人类转录组范围内对约27874个基因建模,并将GO(Gene Ontology) 提供的结构化生物学知识融入模型中。
论文报告显示,scLong在遗传扰动预测、化学扰动预测、癌症药物反应预测、基因调控网络推断等多项任务上,均优于现有单细胞基础模型和多种任务专用模型。
为什么单细胞领域需要一个「更长」的模型?
因为一个细胞并不是只由少数几个「明星基因」决定的。很多现有模型只在约 1500 到 2000 个高表达基因上做 self-attention,这样确实更省算力,但代价是:大量低表达基因被排除在外。
而这些低表达基因虽然「声音不大」,却常常扮演调控开关、信号微调器,甚至在稀有细胞类型、应激反应、疾病进展中发挥关键作用。
换句话说,过去很多模型更像是在读「摘要」,而不是在读「全文」。
另一个问题是,单靠表达矩阵本身,模型未必能真正理解「这个基因是干什么的」。
而Gene Ontology恰恰提供了基因在生物过程(Biological Process)、分子功能(Molecular Function)、细胞组分(Cellular Component)上的结构化知识。过去很多模型主要从数据里「自己悟」,但没有显式利用这些成熟的生物学先验,因此在理解功能关联、调控关系和跨条件泛化时仍然受限。
于是,scLong想做的事情很直接:不仅把基因看全,还要把基因「看懂」。
把一个细胞,读成一整句话
如果用自然语言来打比方,scLong的核心思想很有画面感:把一个细胞的整条基因表达谱,当成一句非常长、非常复杂的话来读。
在这个「句子」里,每个「词」不是普通单词,而是一个 「基因 ID + 表达值」 的组合。模型先用一个表达编码器,把数值型表达量映射成向量;再用一个基因编码器,为每个基因生成带有生物学含义的表示;两者相加后,就得到这个「词」的初始表示。
随后,模型通过上下文编码器,让这些基因彼此「看见对方」,从而学习基因之间在当前细胞中的上下文关系。
这里最有意思的一点是:scLong并没有粗暴地把低表达基因扔掉。 它采用了一个双编码器设计:对高表达基因使用更大的Performer编码器,对低表达基因使用更小的Performer编码器,最后再通过一个full-length Performer把全体基因整合起来。这样既尽量保住了全基因组范围的上下文信息,又在计算量和建模能力之间做了平衡。