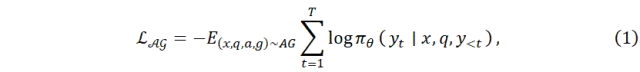北大Venus,帮你拍好照量子位
你随手拍下一张照片,AI也许只会夸“真好看”,却说不出一句真正有用的建议。
面对构图失衡、主体模糊的照片,现有大模型往往停留在泛泛而谈的“赞美式反馈”上:既识别不了问题出在哪里,也无法给出具体、可操作的拍摄指导。
针对这一挑战,北京大学彭宇新教授团队在美学理解领域开展了最新研究,定义了美学指导这一任务,并构建了首个美学指导数据集AesGuide。该数据集包含超过一万张照片,以及与之配套的专业分析和拍摄建议。在此基础上,团队进一步提出美学指导大模型Venus,通过渐进式审美问答与思维链裁剪推理赋予大模型美学理解能力,使AI从“被动描述图像”迈向“主动指导拍摄”。相关论文已被CVPR 2026接收,并已开源。
从“图像描述”到“摄影指导”
智能手机的普及使拍照融入日常生活中,成为人们留存记忆、分享生活、记录情绪的便捷方式。但“拍得到”不等于“拍得好”,由于缺乏专业的摄影经验与审美训练,许多用户在构图布局、取景视角与人景关系等关键环节难以做出准确判断,导致照片无法拍好,在质感与表现力上与专业摄影作品存在巨大差距。
相比之下,专业摄影师不仅能够精准识别照片中的核心美学问题(如构图失衡、机位不当、主体不突出等),还能在拍摄时给出具体、可操作的改进建议(如调整构图比例、变换拍摄机位、优化用光角度与人物姿态等),从而提升照片的美学质量与表达张力。
本文将这种“识别美学问题并给出专业指导”的能力定义为美学指导(Aesthetic Guidance,AG),如图1所示,旨在帮助非专业用户拍摄出媲美专业摄影水准的照片,具有重要的研究意义与应用价值。
△ 图1. 美学指导任务示意图
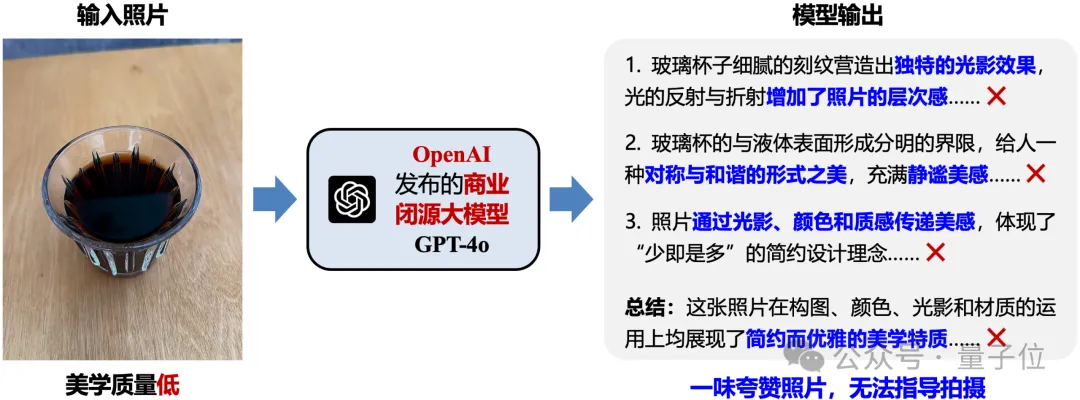
△ 图2. 现有大模型在美学指导任务中的失败案例
近年来,多模态大模型凭借强大的视觉-语言联合建模能力,在图像理解、描述生成、开放域问答等通用任务上取得了显著进展。然而,当任务从“被动描述图像”进一步走向“主动指导拍摄”时,现有模型仍存在明显不足:即使面对构图失衡、主体模糊、画面杂乱等存在明显缺陷的照片,模型也常常倾向于给出赞美式的正向评价,既难以准确识别照片的美学问题,更无法提供与照片内容强对应、可直接操作的调整建议,如图2所示。
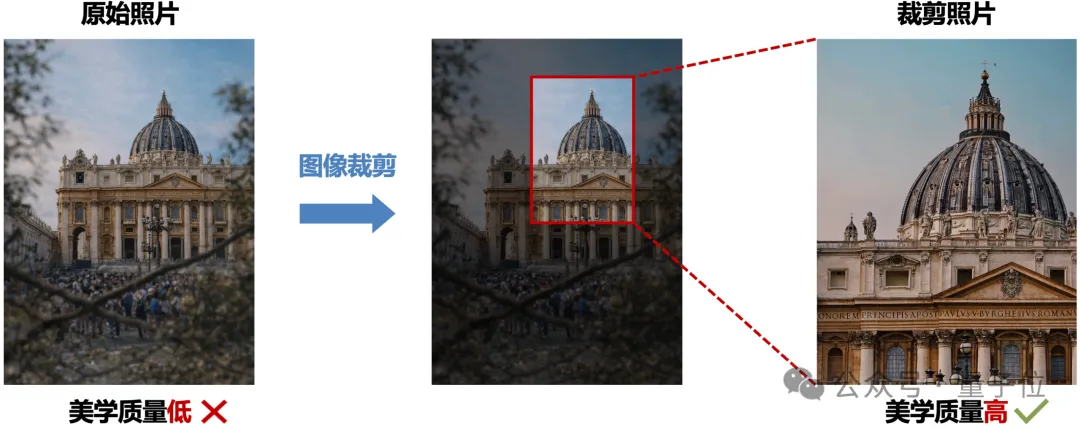
进一步地,这种美学指导能力的缺失还会传导至另一项紧密相关的任务——美学裁剪(Aesthetic Cropping, AC)。美学裁剪旨在通过二次取景突出照片主体并优化整体构图,进而提升照片美感,如图3所示。
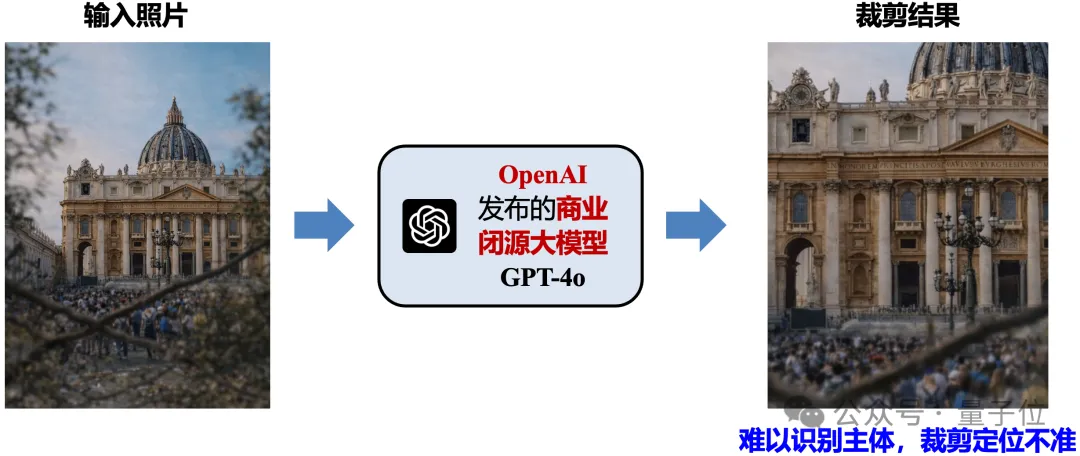
然而,现有多模态大模型难以定位视觉重心并区分干扰区域,因此无法确定合理的裁剪范围,导致裁剪结果偏离理想构图,无法实现照片美感的提升,如图4所示。
△ 图3. 美学裁剪任务示意图
△ 图4. 现有大模型在美学裁剪任务中的失败案例
针对上述问题,北京大学彭宇新教授团队构建了一个新的美学指导数据集与评测基准AesGuide,并提出美学指导大模型Venus:
(1)首先,通过渐进式审美问答赋予大模型美学指导能力,使其从“客观描述”进一步走向“识别问题+提供建议”;
(2)其次,通过思维链裁剪推理激活模型的美学裁剪潜能,提高其对裁剪边界的定位能力。
实验结果表明,Venus在AesGuide和开源美学裁剪评测基准FLMS上均取得了优于现有方法的效果。本文将美学理解从“被动描述”推进到“可操作、可解释、可交互”的视觉优化,为创作更贴近人类审美的智能影像提供了新的思路。
为支撑美学指导的训练与评测,本文构建了一个新的美学指导数据集与评测基准AesGuide。
AesGuide共包含10,748张真实照片,每张照片均标注美学分析与美学指导,如图5所示。不同于以往偏“描述/夸赞”的数据,AesGuide面向真实拍摄场景,强调可操作的拍摄建议,主要体现在两点:
1. 美学评价:每张照片配有专业美学评价,明确指出构图松散、光线失衡、人景关系不协调等关键问题;
2. 拍摄指导:在美学评价的基础上进一步给出具体可操作的调整方案,形成“问题-原因-调整”的完整闭环。
△ 图5. AesGuide数据集样本示例
为解决大模型对照片过度正向评价、美学裁剪定位不准的问题,本文提出了美学指导大模型Venus。如图6所示,Venus的构建过程包含2个主要步骤:
1. 美学指导能力构建:通过渐进式审美问答,引导模型形成更接近人类的审美推理路径,赋予大模型美学指导能力;
2. 美学裁剪能力激活:通过思维链裁剪推理,联合学习几何取景决策与构图逻辑,提高对裁剪边界的定位能力。具体如下:
阶段I:美学指导能力构建。
开源多模态大模型通常采用两阶段训练范式:第一阶段利用海量数据对齐视觉编码器与大语言模型的表征空间;第二阶段在人工标注数据上进行监督指令微调。本文在此基础上,进一步在AesGuide数据集上进行微调,赋予大模型美学指导能力。具体而言,本文参考人类审美推理过程,构建“整体印象-细致分析-可操作建议”的渐进式审美问答思维链,通过由浅入深、难度递增的美学问答训练,引导模型形成更接近人类的审美推理路径。
每条训练样本记为(x,q,a,g),其中x为输入图像,q为用户指令,a为美学分析,g为美学指导。训练目标为最大化模型在给定(x,q)条件下生成a和g的条件概率,即:
其中,AG为AesGuide数据集,y为a和g的拼接序列,πθ为大模型的词元分布。训练过程中,冻结视觉编码器与模态连接器,仅更新大语言模型参数。为验证通用性与跨架构适配性,本文对5个不同架构的开源大模型进行微调,包括Qwen-VL-Chat、InternVL 2.5、MiniCPM-V 2.6、LLaVA-1.5-7B和LLaVA-1.5-13B。微调后的模型分别记为Venus-Q、Venus-I、Venus-M、Venus-L-7B和Venus-L-13B。