老黄杀入OpenClaw战场新智元
OpenClaw又迎重磅玩家!英伟达深夜带着Nemotron 3 Super炸场,1200亿参数专为Agent打造,性能直逼Claude Opus 4.6。推理狂飙3倍,吞吐量猛涨5倍,「龙虾」这是要上天了。
全球市值一哥,也杀入OpenClaw战场了!
昨夜,英伟达重磅祭出新一代「开源模型」Nemotron 3 Super,专为大规模AI智能体打造。
它共有1200亿参数,120亿激活参数,100万token上下文,推理狂飙3倍,吞吐量暴涨5倍。
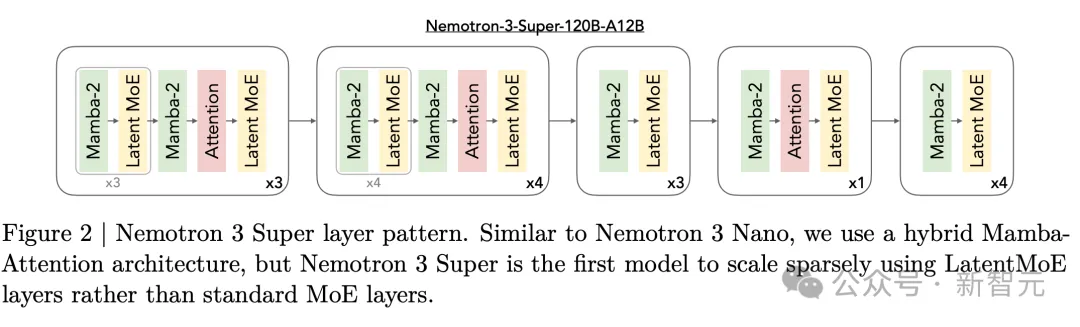
Nemotron 3 Super采用了创新的Mamba-MoE混合架构,彻底解决了多Agent协同中的性能瓶颈。
而且,它还是「Nemotron 3家族」中,首个实现以下三大突破的模型:
原生采用NVFP4精度进行预训练;
全新的LatentMoE混合专家架构,把「单位算力准确率」和「单位参数准确率」优化到了极致;
引入MTP(多Token预测)层,通过原生「投机解码」让推理速度狂飙。
在Pinchbench基准上,Nemotron 3 Super一骑绝尘,稳坐开源第一。
在OpenClaw任务成功率上,它拿下了85.6%的高分,性能直逼Claude Opus 4.6、GPT-5.4。
可以说,完美适配OpenClaw的「最强开源模型」,诞生了!
今天,Nemotron 3 Super超过10万亿Token的预训练和后训练数据集、完整训练方法论,以及15个强化学习环境全部开源。
地址:https://huggingface.co/collections/nvidia/nvidia-nemotron-v3
英伟达1200亿巨兽炸场
OpenClaw绝配
如今,聊天机器人阶段迈向多Agent应用,通常会装上「两堵墙」。
第一个是上下文爆炸。
多智能体工作流生成的Token数,比常规对话多出高达15倍。
因为每一次交互都需要重新发送完整的历史记录,包括工具输出和中间的推理过程。
在执行长周期任务时,这种巨大的上下文数据量不仅推高了成本,还容易导致目标偏移(goal drift),即逐渐偏离了Agent最初设定的目标。
第二个是「思考税」(thinking tax)。
复杂的Agent必须在每一步都进行推理,但如果在每个子任务上都调用LLM,会让多Agent应用的成本,变得极其高昂且反应迟缓,难以在实际应用中落地。
为此,英伟达开源的Nemotron 3 Super,彻底击碎了Agent应用的「两大枷锁」。
论文地址:https://research.nvidia.com/labs/nemotron/files/NVIDIA-Nemotron-3-Super-Technical-Report.pdf
如上所述,Nemotron 3 Super拥有100万Token上下文。
尤其是在运行OpenClaw环境下,AI能将整个工作流状态完整保留在内存中,确保从第一步到最后一步的逻辑一致性。
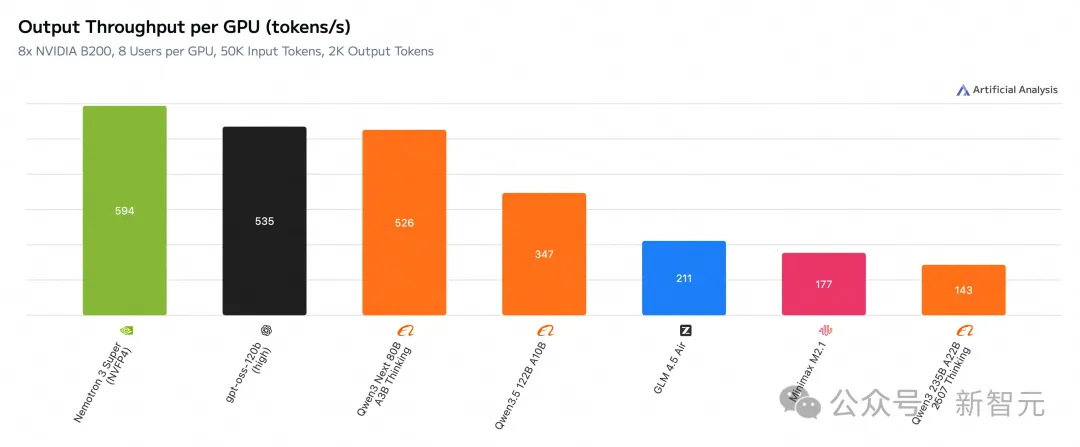
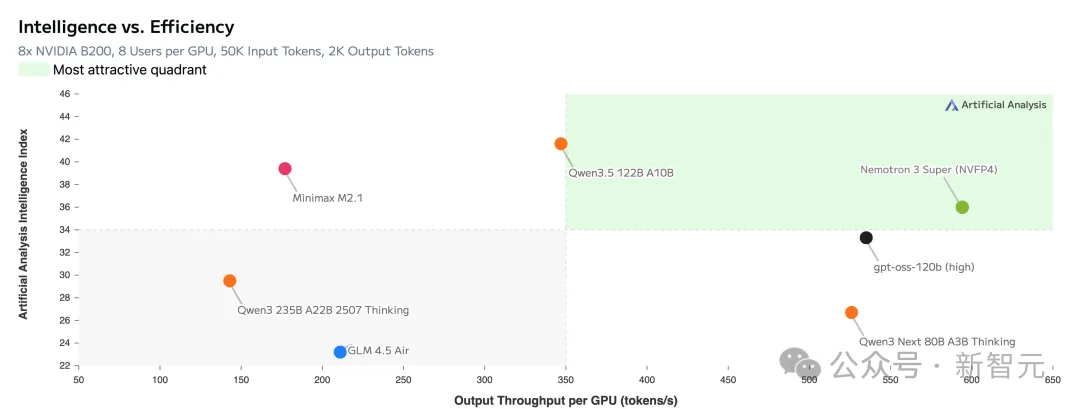
在Artificial Analysis上,Nemotron 3 Super刷新了SOTA,登上了效率和开源榜一。
在同等规模开源模型中,新模型准确率也是遥遥领先。
同时,新模型加持的NVIDIA AI-Q研究型AI智能体,在DeepResearch Bench 和 DeepResearch Bench II排行榜上拿下第一。
未来五年,英伟达将投入260亿美元,用于打造全球顶尖的开源模型
混合架构革命,吞吐狂飙5倍
这一次,英伟达对Nemotron 3 Super底层架构进行了重构。
88层网络采用了周期性交替排列,其中Mamba-2层负责高效的序列建模,提供线性时间复杂度。
而少量Transformer注意力层则作为「全局锚点」穿插其中,负责跨位置的长距离信息路由和高精度推理。
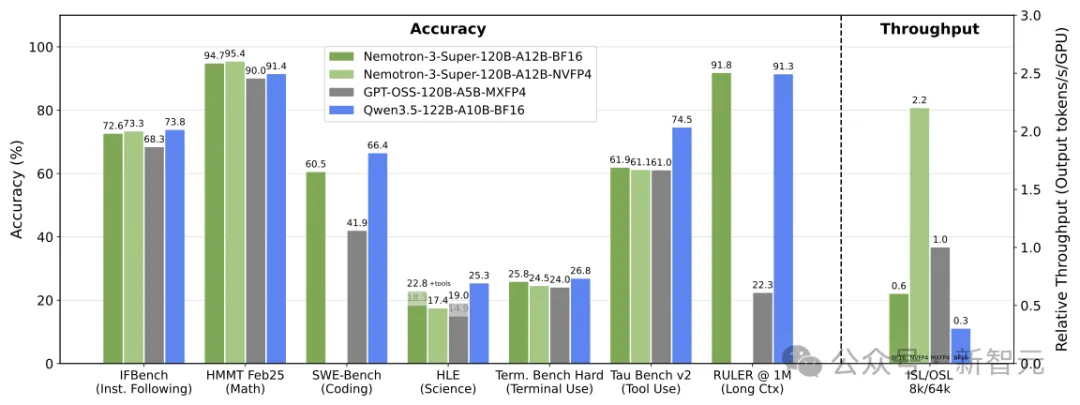
结果,与上一代Nemotron Super模型相比,吞吐量提升高达5倍,准确率提升高达2倍。
与GPT-OSS-120B、Qwen3.5-122B对比,Nemotron 3 Super均拿下了最高成绩。
而且,在输入序列长度为8k、输出序列长度为64k时,它的吞吐量分别比GPT-OSS-120B和Qwen3.5-122B高出多达2.2倍和7.5倍。