Jeff Dean最新访谈:人均50个智能体量子位
谷歌首席AI科学家、传奇工程师Jeff Dean,在最新访谈中放出了一个炸裂预言:
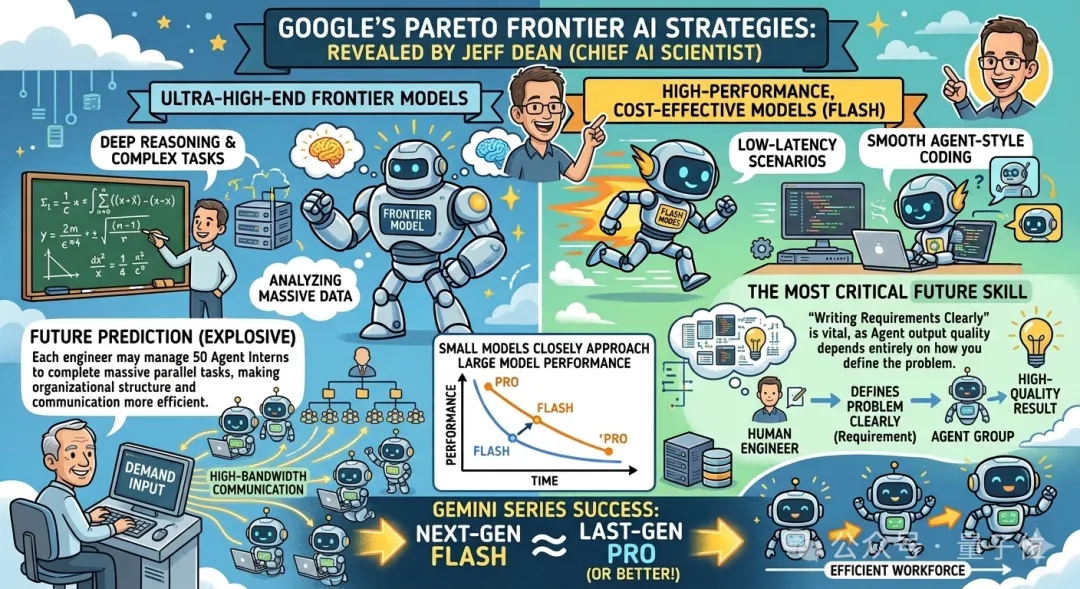
未来每个工程师可能会各自管理50个智能体实习生,完成大量并行任务,而且沟通效率会比人更高效。
未来最重要的技能将会是“写清楚需求”,因为Agent的输出质量完全取决于你如何定义问题。
好家伙,那以后岂不是……写需求比写代码还重要?
Jeff Dean还揭秘了谷歌目前遵循的帕累托前沿策略,新模型的推出主要有两条路线:
一方面是高端前沿模型,用于深度推理、复杂数学问题等高难任务;
另一方面是高性价比模型,用于低延迟场景,比如更流畅的Agent式编程。
想必大家都知道了,Gemini 3 Flash能做到又快又智能,最大的秘诀就在于蒸馏。
Jeff Dean在这期访谈中亲口认证:通过蒸馏,小模型可以非常接近大模型性能。
他们让小模型在大量训练数据上多次迭代学习,同时利用大模型输出的logits信息,让小模型学到更细腻的行为。
这就是为什么Gemini能够做到“下一代Flash ≈ 上一代Pro,甚至更好”。并且他也透露,谷歌内部会持续推进这条路线。
另外,Jeff Dean非常相信“低延迟”的价值:他认为如果延迟降低20-50倍,用户体验会彻底改变。
他还指出,内部一开始就希望Gemini是个多模态模型,但多模态不只是文本、图像、视频、音频这些,让模型理解“非人类”的模态同样非常有用。
比如Waymo车辆的LIDAR传感器数据,或者机器人数据、医疗影像数据等等。未来可能有数百种模态。
在这期访谈中,你还可以了解到:
Jeff Dean早在几十年前就坚信规模化终将取胜,以及“更大的模型、更多的数据、更好的结果”这一信条,这一信条持续了15年;
LLM训练与推理不仅关心计算量,也关心数据搬运成本;对硬件优化、batch size、延迟、吞吐量的设计,都可以用能量消耗作为第一性原则衡量;
TPU和ML研究团队必须紧密互动、协同设计,硬件设计需预测未来2–6年的模型趋势;
Gemini早期资源太分散,Jeff Dean称“这是愚蠢的”;
Jeff Dean给出两个预测:未来真正“个性化”的模型会极其重要,以及低延迟会改变很多应用场景。
以下为本场访谈重点内容实录,围绕核心观点做了摘选整理,部分文字在不改变原意的基础上做了适度删改,enjoy!
蒸馏是Flash模型突破的关键
Shawn Wang:首先得说一句,恭喜你们占据了帕累托前沿。
(编者注:帕累托前沿描述的是多个目标之间权衡时的最优解集合。此处指谷歌既能推出高性能的前沿模型,又能推出低成本、低延迟的高性价比模型,在性能 vs 成本/延迟这两个维度上已经达到了最优权衡状态)
Jeff Dean:谢谢。能站在帕累托前沿当然是好事。
Shawn Wang:是的。我觉得你们做的不只是追求最强能力,还同时兼顾效率,真正“拥有”了帕累托前沿——既有顶级性能,也有成本与效率控制,还提供了完整的模型梯度供用户选择。
这里面有一部分来自你们的硬件工作,一部分来自模型设计,还有很多长期积累的“秘密武器”。看到这一切整合起来,确实令人印象深刻。
Jeff Dean:确实,这不是单一因素,而是从硬件到软件、从系统到模型的全栈协同。
所有这些结合在一起,才能既做出能力极强的大模型,也能通过软件技术把这些能力“压缩”到更小、更轻量、更低成本、更低延迟的模型里,同时仍然保持相当强的能力。
Alessio Fanelli:你们内部,会不会对帕累托前沿的“低端”也有很大压力?
新实验室往往拼命往性能最前沿冲,因为需要融资。但你们有数十亿用户。早年做CPU规划时,如果每个用户每天多用三分钟语音模型,算下来都需要翻倍的算力。
现在在谷歌内部是怎么权衡的?如何在“追求前沿”和“必须规模化部署”之间做决策?
Jeff Dean:我们始终希望拥有站在前沿、甚至推动前沿的模型,因为只有在那里,你才能看到“新能力”的诞生——那些上一代模型不具备的能力。
但我们也清楚,这类模型通常更慢、更贵。很多广泛场景其实更需要低延迟、低成本的模型。
所以我们的策略是同时做两件事:一方面有高端前沿模型,用于深度推理、复杂数学问题等高难任务;
另一方面有高性价比模型,用于低延迟场景,比如更流畅的 Agent 式编程。两者都重要。
而且通过蒸馏技术,我们可以把前沿模型的能力迁移到小模型上。因此这不是“二选一”,反而是相辅相成——没有前沿模型,也很难得到高质量的小模型。
Alessio Fanelli:蒸馏这个方法你和Geoffrey Hinton早在 2014 年就提出了。
Jeff Dean:别忘了Oriol Vinyals。
Alessio Fanelli:这么多年过去,你怎么看待这些技术理念的“周期性”?比如稀疏模型。很多想法在当时未必看起来重要,但后来影响巨大。你们如何判断哪些值得在下一代模型中重新审视?
Jeff Dean:当年做蒸馏,动机其实来自图像任务。
我们有一个 3 亿张图片的数据集。如果针对不同类别训练“专家模型”——比如一个专门识别哺乳动物,一个专门识别室内场景——然后做成 50 个模型的集成,效果会很好。但显然不可能线上部署50个模型。
于是我们想:能否把这些专家模型“压缩”进一个更小、可部署的模型里?这就是蒸馏的由来。今天其实逻辑类似,只不过我们不是蒸馏50个模型,而是从一个极大规模模型蒸馏到小模型。
Shawn Wang:蒸馏和强化学习革命之间是不是也有关联?比如RL会在某些能力分布上“打尖”,但可能牺牲其他区域。
如果能通过蒸馏把能力重新平衡回来,实现“能力合并而不退化”,那是不是理想状态?
Jeff Dean:蒸馏的关键优势之一,是小模型可以在大量训练数据上多次迭代学习,同时利用大模型输出的 logits 信息,而不仅是硬标签。这能引导小模型学到更细腻的行为。
实践中我们确实发现,小模型可以非常接近大模型性能。
这也是为什么在多个Gemini世代中,我们都能做到“下一代Flash ≈ 上一代Pro,甚至更好”。这是一条我们会持续推进的路径。
Shawn Wang:那Ultra呢?是不是内部有一个“母体模型”一直在蒸馏?
Jeff Dean:我们有很多不同规模和用途的模型,有些不对外发布,有些是Pro级别。蒸馏可以来自不同来源。另外,推理阶段扩展也是提升能力的重要方式。
Shawn Wang:Flash的经济性确实带来了规模优势。听说已经50万亿tokens?
Jeff Dean:市场份额方面,希望还在增长。
Shawn Wang:Flash现在几乎无处不在——Gmail、YouTube、搜索AI模式。
Jeff Dean:是的。Flash的优势不仅是便宜,还有低延迟。而延迟非常关键。
未来模型会被要求完成更复杂任务,比如写整个软件包,而不仅是一段循环代码。这会生成大量token,因此低延迟系统至关重要。
Flash 是一个方向。硬件层面,比TPU芯片之间的高性能互联,也对长上下文attention或稀疏专家模型的可部署性至关重要。
Alessio Fanelli:那你们会不会担心某种“饱和”?比如两代之后Flash就能覆盖大多数需求,那还有动力继续推Pro前沿吗?
Jeff Dean:如果人类提问的分布是静态的,那可能会。但事实是,模型能力越强,人们问的问题越复杂。
一年前我只会让模型做简单coding,现在我会让它做复杂系统分析。用户需求本身在进化。前沿模型推动能力边界,同时也让我们看到瓶颈在哪里,从而改进下一代。
Alessio Fanelli:内部还依赖公开benchmark吗?
Jeff Dean:公开benchmark有价值,但生命周期有限。理想benchmark初始分数应在 10%–30%,然后通过改进提升到80%–90%。