谷歌Gemini最强性价比模型发布:1块8,3本三体量子位
谷歌深夜放大招,正式推出Gemini 3.1 Flash-Lite。
从名字就能看出,这款模型主打轻量快速。
官方给的title则更为直接——
迄今为止性价比最高的Gemini 3系列模型。
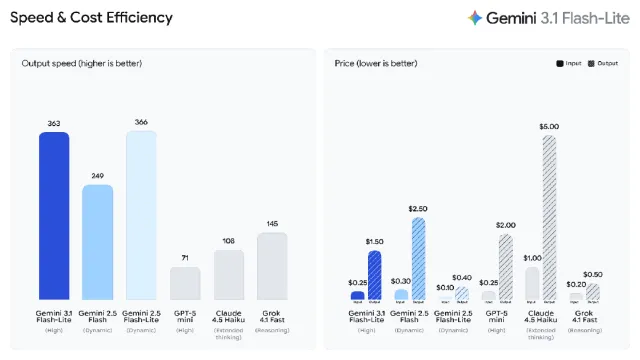
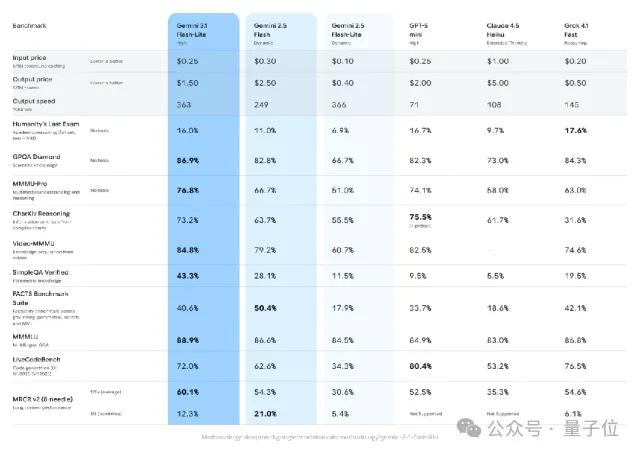
有多便宜呢?每百万输入token仅需0.25美元,百万输出token 1.5美元。
举个直观的例子就是,只需要折合人民币1.8元,就能让AI读完3本《三体》全集。
同时始终保持高性能表现,对比上一代主力Flash模型Gemini 2.5 Flash,首次响应token时间快2.5倍,输出速度提升45%。
而且专为大规模智能应用而生,能够低成本高效率地实现模型批量部署。
如此看来,OpenClaw这盘龙虾肉,谷歌也想尝一尝了(doge)
拉爆极致性价比
官方介绍中,Gemini 3.1 Flash-Lite是Gemini 3系列中速度最快、成本最低的一款模型,目前已经可以通过Google AI Studio中的Gemini API和Vertex AI平台获取。
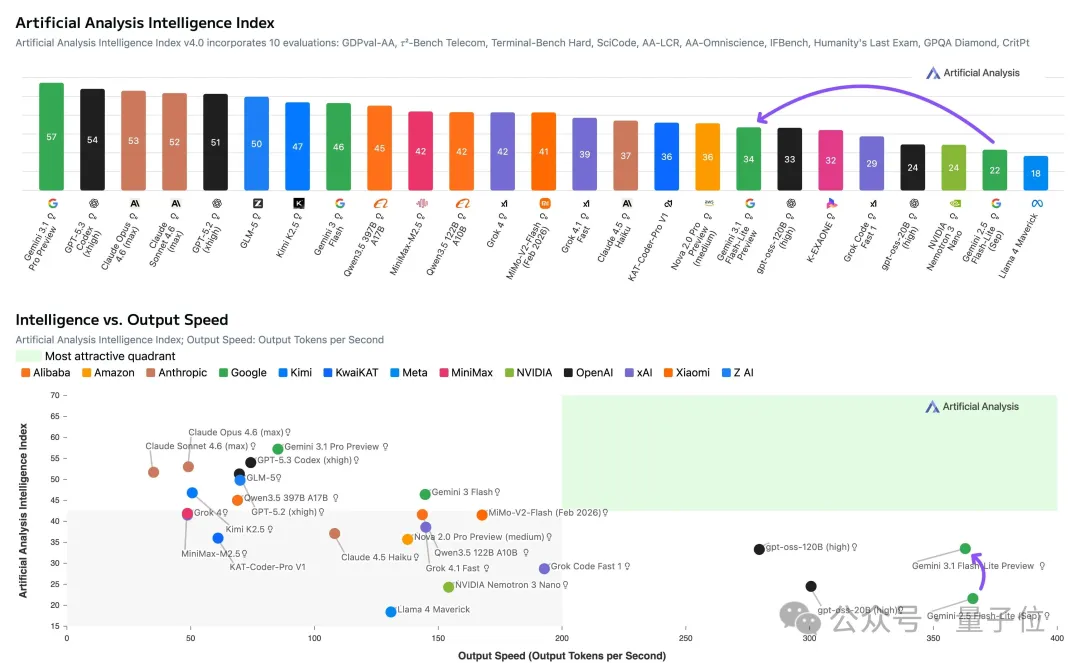
在Artificial Analysis基准测试中,输出速度显著优于Gemini 2.5 Flash,价格同时得到大幅度削减。
不过值得注意的是,谷歌官方并没有将其与Gemini 3 Flash对比,而且讨巧地选择了更旧版本的Gemini 2.5 Flash。
二者在定位上有所不同,Gemini 3 Flash侧重逻辑推理效率,Gemini 3.1 Flash-Lite更关注极致性价比。
此外,对比市面同等轻量级模型,如GPT-5 mini、Claude 4.5 Haiku,无论是速度还是成本,Gemini 3.1 Flash-Lite都优势显著。
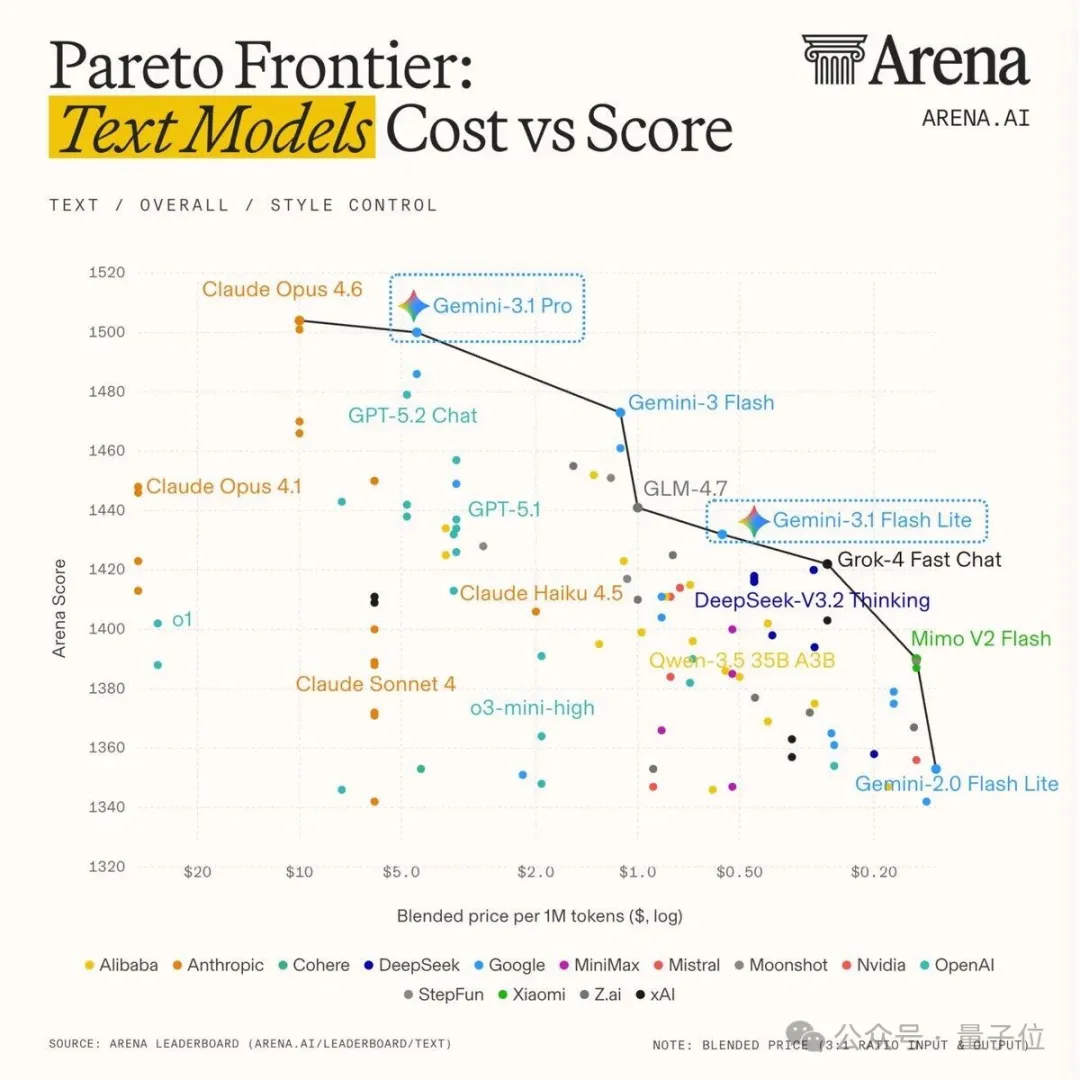
在Arena测评中,也取得了1432分的亮眼成绩,与Grok-4.1-fast水平相当,在创意写作和长篇查询方面表现出色,领跑低价位段模型。
而Gemini-3.1 Pro则持续在高价位型号中保持第一梯队,Gemini 3 Flash处于二者之间。
在Code Arena中也与Qwen3-coder并列第35名,表现出优秀的智能Web开发能力。
另外,在GPQA Diamond和MMMU Pro上,Gemini 3.1 Flash-Lite也分别斩获86.9%和76.8%的分数,超越了前几代更大的Gemini模型。
除了强大的性能以外,模型还额外支持可调思考层级,开发者能够根据当前任务复杂度,自由选择模型的思考深度。
这对于处理高频的大量请求场景相当重要,能够更好地平衡速度与效果。
换言之,该模型既能处理低成本批量任务,如长文本翻译,也能做那些需要深度思考的任务,比如生成用户界面、严格按指令执行复杂逻辑等。
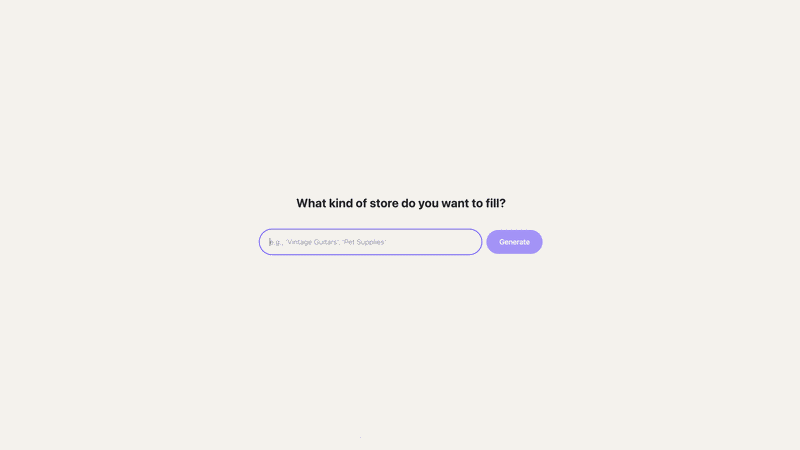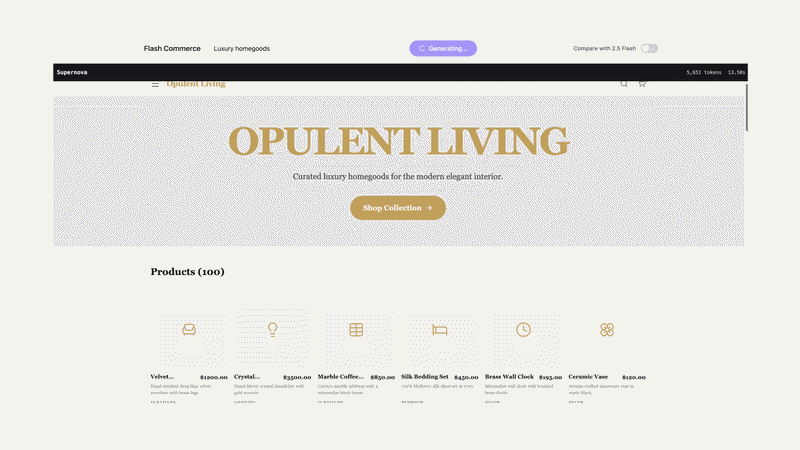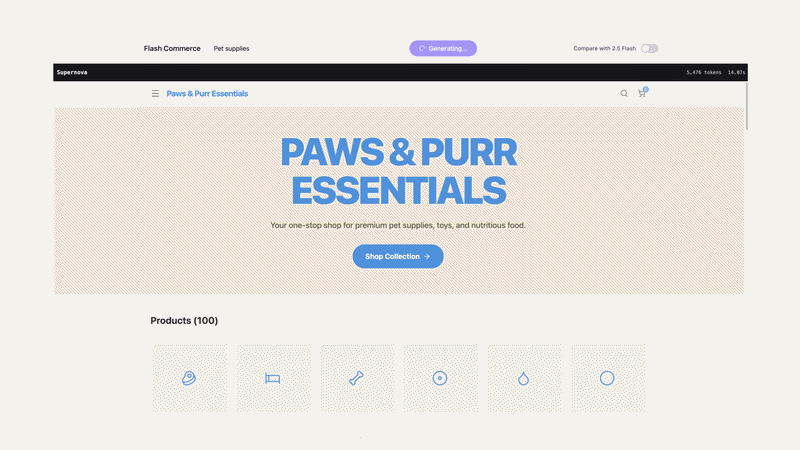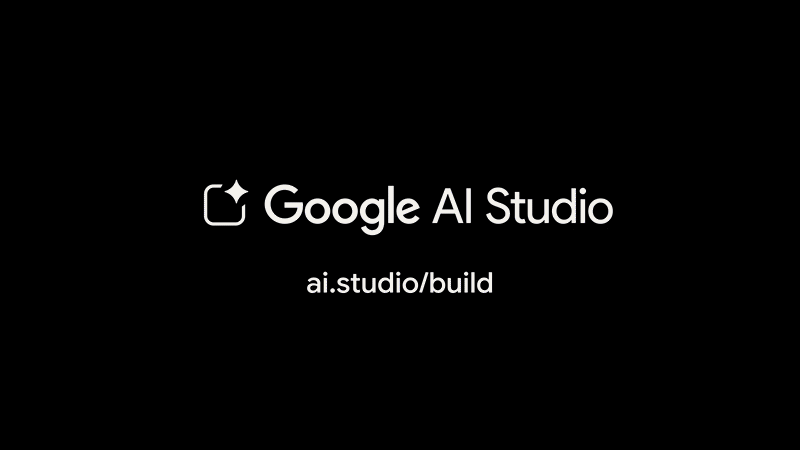
在官方给出的示例中,Gemini 3.1 Flash-Lite能够迅速将上百种不同类别的产品填充到电子商务线框图中。
简单来说,就是该款模型更适用于企业与开发者在生产环境中用于实时响应与大规模处理任务,高性价比也让它极具竞争力。