Claude崩了,全球AI因何“熔断”?华尔街日报
Claude全球性宕机持续超24小时,根源或指向地缘冲突引发的中东数据中心遭袭。此次事件暴露AI基础设施的致命脆弱:高度依赖少数算力节点与物理网络。更深远影响在于,Claude已从工具进化为嵌入开发者工作流的“AI操作系统”,系统性依赖之下,一次宕机即可引发全球生产力“熔断”。
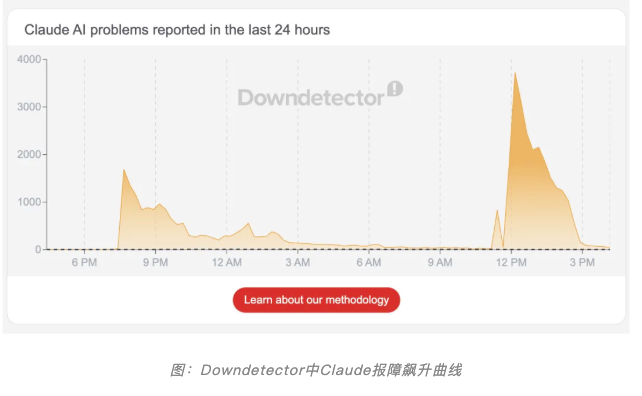
北京时间2026年3月2日晚间19点49分,Anthropic的AI助手Claude在全球范围内突然陷入大面积服务中断。claude.ai网页端、开发者控制台、AI编程工具Claude Code以及移动端应用几乎同时亮起红灯,数千名用户涌入Downdetector报告故障,高峰期报障数量数千条。用户在尝试登录时看到的是HTTP 500和529错误码,或者一句简短的提示:“Claude will return soon.”
对于全球数以百万计已经将Claude深度嵌入日常工作流的开发者、内容创作者和企业用户而言,这场宕机的体感更接近一次“大面积停电”。
社交媒体上,有人自嘲“只会写prompt了,怎么办”;有开发者说,工作写到一半突然断了,只能被迫切换到ChatGPT或Gemini应急;更有人在群里调侃:“AI Native”的公司今天不如去团建。
01 “打地鼠式”宕机
“宕机”的具体原因,至今Anthropic官方也没有详细的解释,但是过去一周发生了一系列事情。
2月28日,Anthropic因拒绝将Claude用于大规模国内监控和全自主武器系统,失去了与美国五角大楼的合同。特朗普总统随即在社交媒体上抨击Anthropic是“左翼疯子”,并下令所有联邦机构停止使用Claude。OpenAI迅速接手,宣布与五角大楼达成合作协议。
这一事件在全球用户群体中引发了戏剧性的反转。一场名为“QuitGPT”的抵制运动在Reddit、Instagram和X.com上迅速蔓延。Reddit上一条呼吁取消ChatGPT的帖子获得了3万个赞,Instagram账号“quitGPT”短时间内吸引了超过78000名关注者。
据Tom's Guide报道,约70万用户开始从ChatGPT转投其他平台。Anthropic成了这场数字迁徙的最大受益者。
根据Anthropic官方披露的数据,自2026年1月以来,Claude免费用户数量增长超过60%,每日新注册用户数较2025年11月翻了三倍,付费订阅用户在年内已经翻倍。在超级碗LX之前,Claude在美国App Store的排名还在第42位;到2月28日,它登上了免费应用排行榜第一名,将ChatGPT挤到了第二。
这波“泼天富贵”来得太猛了。从Sensor Tower的数据看,Claude在整个2月都处于快速攀升通道,但最后几天的用户涌入量远超Anthropic基础设施的承载预期。
外媒在报道中引用Anthropic的说法称,公司在过去一周一直在应对“前所未有的需求”。
从Anthropic官方状态页面的时间线来看,故障的演进呈现出“打地鼠”式的特征。
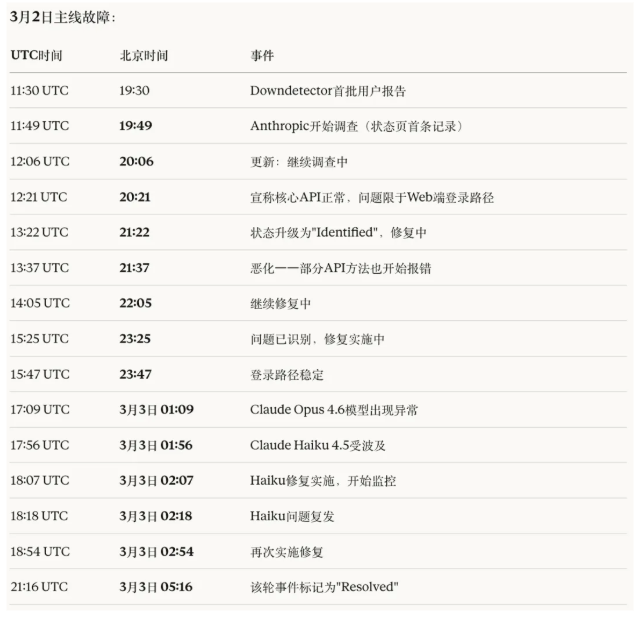
UTC11:49(北京时间19:49),团队开始调查问题,最初判断故障集中在claude.ai的登录和登出路径。
UTC12:21(北京时间20:21),Anthropic宣称核心API运转正常,问题仅限于Web端。
UTC 13:37(北京时间21:37),情况出现恶化,部分API方法也开始报错。
此后,Claude Opus 4.6模型在UTC 17:09出现异常,紧接着Claude Haiku 4.5在UTC 17:56也受到波及。修复、复发、再修复的循环持续了数小时。
直到UTC 15:47(北京时间23:47)左右,主要服务才逐步恢复。随后 Opus 4.6 又出现多次短时 elevated errors(含一段延续到约 21:16 UTC ,北京时间3月3日5:16)。
而仅仅几个小时后的UTC 3月3日凌晨3:15(北京时间11:15),新一轮故障再次出现,影响范围扩展到了Claude Code和Cowork,截至发稿时问题仍在调查中。
关于宕机的原因,还有媒体报道称,中东地区的AWS数据中心疑似遭受“不明物体”袭击导致起火断电,AWS算力池受到冲击,而高度依赖这些算力节点的Claude模型因此失去支撑。
远在中东的地缘冲突,为什么可能会引起美国 AI公司的大规模宕机事件?
当下,AI 服务的关键链路高度全球化且存在少数“咽喉点”:地缘冲突若导致红海—曼德海峡—苏伊士一带的海底光缆受损、区域网络受限,或波斯湾/阿拉伯半岛周边云数据中心与电力设施、跨境骨干网、海缆登陆站出现中断与拥塞,就可能引发跨区域的网络时延飙升、路由收敛异常、认证/计费/控制面访问失败,以及跨区复制和故障切换受阻。
更值得关注的是,Claude 宕机当天,xAI 官方状态页显示 Grok(Web/iOS/Android)在同日 约 UTC23 点前后也发生了约 40 分钟的“暂时不可用“”事件。但两者是否存在共同上游或因果关联,目前缺乏公开证据。
这条链路如果属实,意味着这次宕机不仅仅是前端认证系统的问题,而是涉及底层云基础设施的物理脆弱性。
在赛博空间里算力通天的大模型,在真实世界的“物理打击”面前显得格外脆弱。
02 下游生态的连锁反应
Claude这次宕机之所以引发如此大的关注,核心原因在于,AI已经从一个聊天机器人,变为一整条AI Native生产力链条的关键节点。
首先受到冲击的是开发者群体。Claude Code已经成为全球开发者最依赖的AI编程工具之一。据此前的报道,Claude Code产品年化收入估算约2亿美元量级。Anthropic的Claude Code创始人Boris Cherny曾在播客中透露,他自2025年11月起就再也没有手动编辑过一行代码。
当Claude Code完全不可用时,外媒报道社区普遍反应:开发者们被迫回到生成式AI出现之前的习惯,自己动手写代码。
专业开发者被迫在工作流中途切换到GitHub Copilot或ChatGPT的编码功能,但这种切换本身就意味着效率损失和上下文断裂。对于那些将Claude API深度集成到自有产品中的公司,影响更为直接。
虽然Anthropic声称API在大部分时间保持正常运转,但UTC 13:37的那段时间,API也出现了故障,这恰恰是那些没有多模型容错方案的企业失去所有AI功能的关键时刻。
内容创作领域同样遭受冲击。依赖Claude进行文案撰写、报告生成、数据分析的团队被迫暂停工作。客户服务机器人集体沉默,工单开始堆积。
据Deployflow的分析测算,对于一个25人规模的工程团队,即便按每小时90英镑的计费标准,4小时的服务中断也意味着超过9000英镑的生产力损失,还不包括下游的连锁延迟。
更深远的影响在于信任层面。ainvest的分析指出,重复性的服务中断正在侵蚀用户对平台可靠性的信任,尤其是对于那些在Claude之上构建业务的开发者和企业而言,持续的正常运行时间是最基本的要求。
但是,Claude做了什么,让企业对它的依赖性如此强?
让Claude从“好用的模型”变成“生态链核心”的,是Anthropic持续搭建的Agent基础设施。