DeepSeek深夜发论文,V4前奏来了?新智元
一夜之间,AI圈再次地震!这次不是DepSeek V4,而是DeepSeek直接换了推理架构。GPU空转的问题,被他们硬生生砍掉了一半。
昨天,DeepSeek-V4要来的消息纷纷扬扬,整个AI圈都被搅动得心绪不宁,隔壁的美国同行们都快崩了。
结果就在昨晚,DeepSeek突然又双叒叕更新了!他们联手北大、清华的团队,发布了针对智能体的推理框架DualPath。
这个框架的核心目标,就是缓解因大规模KV-Cache从外部存储读取而带来的I/O瓶颈问题,避免算力资源因数据加载速度受限而被闲置。
链接:https://arxiv.org/abs/2602.21548
具体来说,此次架构升级引入了「Storage-to-Decode」的第二条加载通路,通过「双路径KV-Cache加载」机制,有效改善了PD分离架构下的读取瓶颈和资源失衡问题。
可以说,这个框架直接剑指多轮AI智能体(agentic)场景下的大语言模型推理性能瓶颈——
以后,DeepSeek+OpenClaw的玩法儿不远了!
还是熟悉的味道,DeepSeek在AI基础设施上的提升一如既往的出色,如今迈入智能体与强化学习时代——
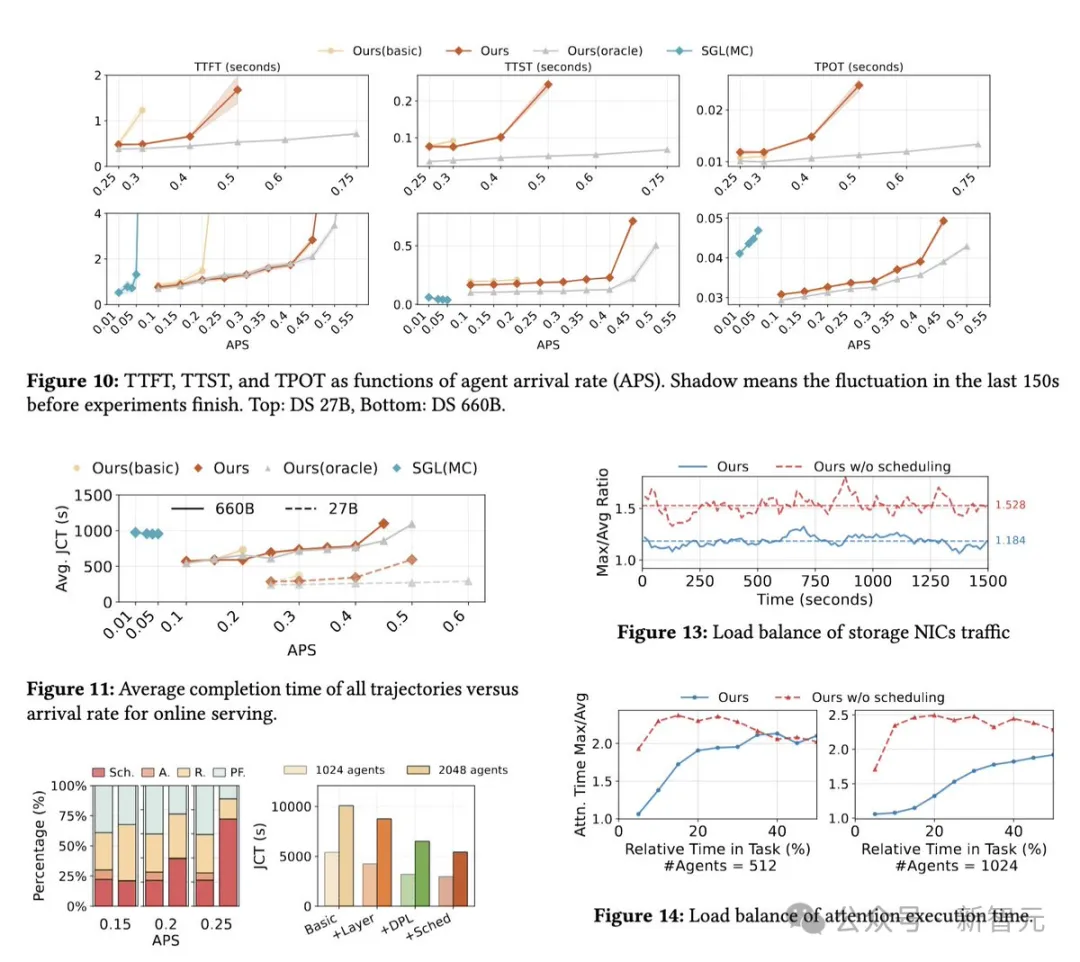
离线推理吞吐量最高提升1.87倍,在线场景下每秒智能体运行次数提升1.96倍。
论文一出,学界直呼:如此极致的算力管理,如此精准的调控,DeepSeek团队是真正的经济学大师!
网友直评:这正是赢得AI大战的关键基础设施思维。
可以说,这篇论文充分体现出DeepSeek的野心——把AI做成像水气电一样的基础设施!
OpenClaw引爆智能体
DeepSeek窥天机
Claude Code\Cowork、OpenClaw等智能体的爆火,毫无争议地点燃了Agent黄金时代的开年热潮!
DeepSeek发现,在智能体推理任务期间,GPU存在严重的利用率不足问题。
一个Agent任务有多长?几十分钟,有时几小时。它要写代码、查文档、 跑测试,再回来改代码。上下文几百万token,每一步都要快。
这就带来了一个巨大的技术债——KV Cache(键值缓存)。
KV Cache是什么?一句话,它是AI的草稿纸。
模型每生成一个token,都会把「思考痕迹」存下来;下次继续写,它要翻草稿;草稿越厚,占用显存越多。
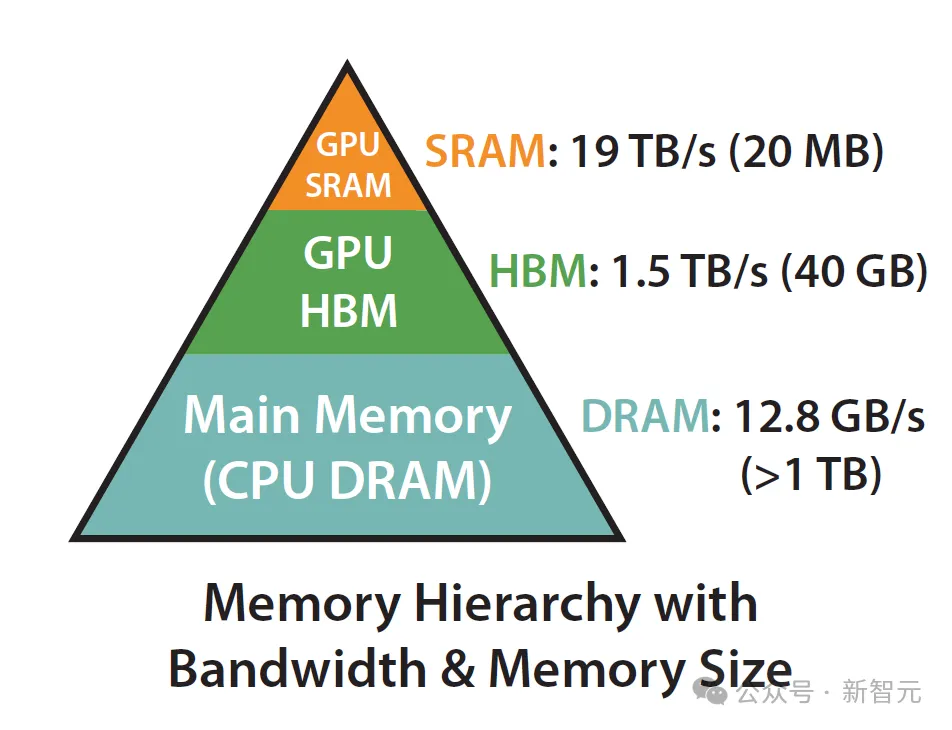
为了让AI记得上下文,我们必须把这些庞大的数据一直存在GPU的显存(HBM)里。
然而,HBM供不应求,死死卡住了AI行业的脖子。
AI模型推理正演变为一场内存竞赛。
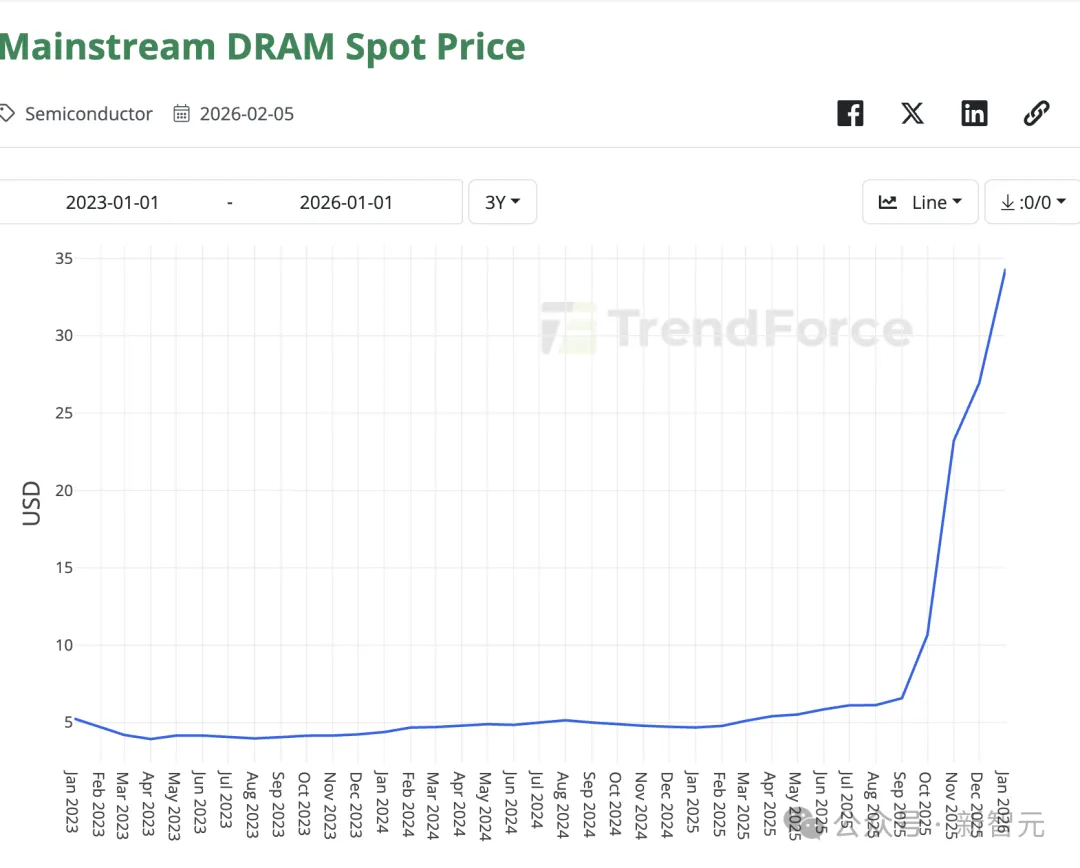
因为AI对HBM需求激增,消费级内存被停产,导致在短短几个月内主流的内存DRAM价格涨了7倍!
所以,把不需要立刻用到的记忆暂时挪到便宜的SSD或主内存里,下次要用时,再把它搬回来,这成了行业的出路。
矛盾就在这里爆发了:传统的推理架构是串行的。
当AI需要调取旧记忆时,计算单元(Compute Unit)必须停下来,眼巴巴地等着数据通过带宽有限的PCIe总线慢慢爬进显存。
DeepSeek的研究指出,在多轮智能体推理(Agentic Inference)的场景下,GPU竟然有大量时间是在「空转」等待数据!
他们发布了一些关于智能体编码的真实世界数据,并定义了一个「缓存-计算比率」指标:该比例取决于模型类型、上下文和追加长度。
他们从代表性编码任务中收集的轨迹显示,平均交互轮数为157,表明LLMs倾向于进行多轮交互。
平均上下文长度为32.7k,而每次追加长度的平均值仅为429,这意味着KV缓存命中率高达98.7%。
在此场景下,缓存-计算比(定义为KV缓存加载量与所需计算量之比)对于DeepSeek-V3.2约为22GB/PFLOP。
由于每个节点上单块存储网卡的带宽有限,KV缓存加载速度成为了瓶颈。
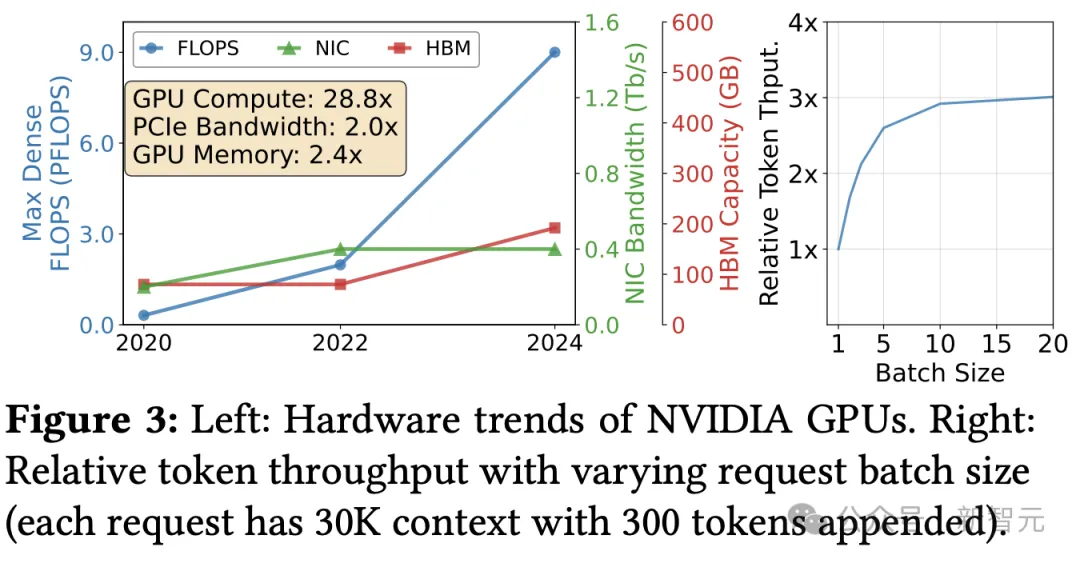
近年来,网络带宽和HBM容量的增长落后于GPU FLOPS的增长,I/O计算比率下降了14.4倍。
此外,较小的HBM容量限制了GPU内核可同时计算的token批次大小,阻碍了张量核心等计算单元被充分利用。
第三,现有的LLM推理系统在不同引擎类型之间表现出严重的存储网络利用率不均衡。
DeepSeek的黑科技:DualPath
DeepSeek的DualPath架构,做了一件听起来简单、实现起来却极具颠覆性的事:它把「思考」和「回忆」这两件事,从串行变成了并行。
在计算机科学中,这被称为「计算与存储访问的解耦」(Decoupling Compute and Memory Access)。
让我们换个通俗的比喻。
传统架构是串行的:先把数据读进显存,读完后,GPU才开始算。像下载电影,必须等100%,才能播放。
而DualPath做了一件事:边下载,边播放。
SemiAnalysis的技术团队成员、高级工程师Jordan Nanos认为:
DeepSeek在DualPath 论文中提出了一个超酷的点子!