为什么AI需要世界模型?XiDianAIWI
你看到的以下两张图片,是一个沙坑还是一座沙丘?
把同一张照片倒过来,沙坑变成沙丘,站在坑底的人变成了趴在坡面上。两张图像的像素信息完全一致,唯一的区别是旋转了180度。我们的视觉系统对同样的输入给出了完全不同的解释。
再来一组。一起做:调转你的手机屏幕——
这不是一个关于视错觉的趣味科普。
它指向一个关于智能的基本问题:感知不是对外部世界的忠实复制,而是大脑对感觉信号的主动推断。
大脑内部必须维持着某种关于世界运作方式的模型——包括光线来自上方这样的物理先验——才能对视网膜上的二维投影做出三维解释。这个模型,就是认知神经科学中所言的"世界模型"(world model)。
类似于认知科学,在AI领域也正在经历一场认知转向。Yann LeCun、李飞飞、Demis Hassabis等人近年来反复强调:仅靠大语言模型预测下一个token,远远不够。
真正的智能系统需要建立世界模型,预测的不是下一个词,而是给定某个动作后,环境的下一个状态。
这个判断的背后,有神经科学的证据,有计算模型的验证,也有工程实践的推动。本文试图沿着这条线索,把故事讲清楚。
一、大脑是一台预测机器
自下而上与自上而下
关于感知的理论大致分两派。
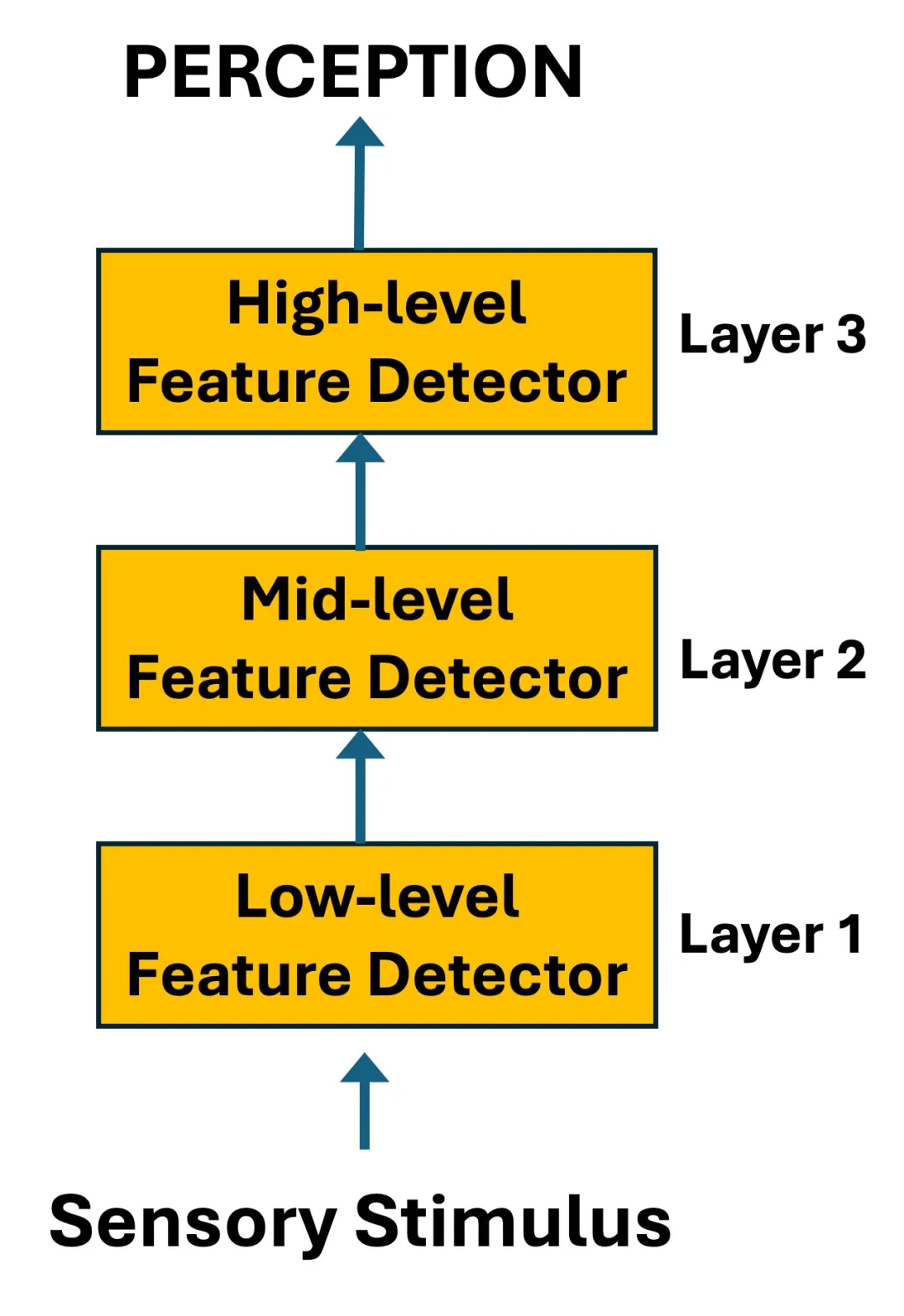
自下而上(bottom-up)的理论认为,大脑从感觉输入开始,逐层提取特征:先识别边缘和线条,再组合成形状和纹理,最终达成高层感知——"这是一个沙坑"。
早期计算机视觉沿用的正是这个思路,由人工设计特征检测器,逐级组合。
深度学习时代,卷积神经网络(CNN)和视觉Transformer虽然不再需要人工设计特征,但信息流动的方向仍然是单向的:从像素到抽象表征。本质上仍是自下而上的过程。
问题在于:如果感知完全由底层输入决定,两张像素相同的图片就不应该产生不同的感知。
沙坑变沙丘的错觉,自下而上模型解释不了。
自上而下(top-down)的理论提供了另一种解释方案。其中,最有影响力的是预测处理框架(predictive processing)。
PP 理论的核心主张是:大脑以层级结构组织,最高层负责对感觉信号的外部原因做出假说,这个假说就是我们的感知。高层告诉低层"你应该看到什么",低层将实际输入与这个预测对比,如果匹配,一切正常;如果不匹配,低层产生预测误差信号,向上传播,促使高层修正假说。
回到沙坑的例子:大脑有一个强大的先验假设——光源来自上方(进化在数百万年中刻入的默认设定)。在观看二维图像时,这个先验被翻译为光从图片顶部照射。图片正放时,阴影分布与"凹陷"一致,大脑假说这是沙坑;倒放后,同样的阴影分布在新的光源假设下,最佳解释变成了"隆起"。
值得一提的是,Sun和Perona在1998年发表的研究还揭示了一个有趣的细节:这个光源位置假设甚至受惯用手影响——右利手的人更倾向于假设光源在左上方,左利手则相反。
即使你知道这是同一张图片,你也无法"取消"这个错觉。先验太顽固了。
从Helmholtz到Friston:150年的思想谱系
预测处理的思想根源可以追溯到19世纪60年代。德国博学者Hermann von Helmholtz提出了"无意识推断"(unconscious inference)这个概念:感知是大脑将感觉信息与先验知识结合,推断外部原因的过程。"无意识"是因为我们完全不知道这些计算在发生,我们只接触到推断的结果。
1970年代,英国神经心理学家Richard Gregory更新了Helmholtz的思想,明确提出大脑是一台预测机器:它像科学家一样,用模型生成假说,用数据验证,必要时修正。Gregory在1990年的一篇文章中写道:对感知规则的一个重要用途,是让过去的经验来处理当前的数据,从而预测未来;但当当下的情境异常时,来自过去的规则就会导致系统性错误——错觉的产生不可避免,因为规则越是宽泛和一般化,就越无法应对所有特殊情况。
1999年,Rajesh Rao和Dana Ballard发表了具有里程碑意义的论文"Predictive Coding in the Visual Cortex",首次给出了预测处理的计算实现。
他们建立了一个三层层级神经网络,层间有双向连接:预测信号自上而下传递,误差信号自下而上传播。最低层将实际像素与上层传下的预测对比,产生误差;误差传给上层的"预测估计器"(predictive estimator),后者做两件事:修正对下层的预测,同时将残差继续向上传递。他们发现,这个网络自发地学会了层级化处理:第一层学会了检测边缘和线条,第二层学会了将第一层的特征组合成更抽象的结构。网络通过最大化生成观测数据的后验概率来学习,内部模型以分布式方式编码在各层神经元的突触中。
Karl Friston的贡献在于把预测处理从感知扩展到了行动。他的自由能原理(free energy principle)和主动推断(active inference)框架提出:当大脑的内部模型不可更改时(比如维持体温在37°C的稳态模型),面对预测误差,解决方案不是修改模型,而是驱动身体行动,改变外部环境来消除误差——天太冷了,就走进屋里。在这个框架下,感知和行动被统一为同一个原理的两种表现:都是在最小化自由能,即内部模型与感觉输入之间的不匹配。
Friston将Helmholtz、Gregory、Rao和Ballard等人的工作整合进了一个统一的理论体系。
二、当机器学会预测:PredNet与机器的"错觉"
Gregory在1967年提出了一个意味深长的问题:会看的机器也会产生错觉吗?
他的答案是"是的"——前提是这里的"看"意味着机器使用了内部模型来解释输入,而不仅仅是被动地处理像素。
2016年,哈佛大学的William Lotter、Gabriel Kreiman和David Cox建造了PredNet(预测神经网络),试图在机器学习中复现预测处理的机制。
PredNet被设计来预测视频序列的下一帧。
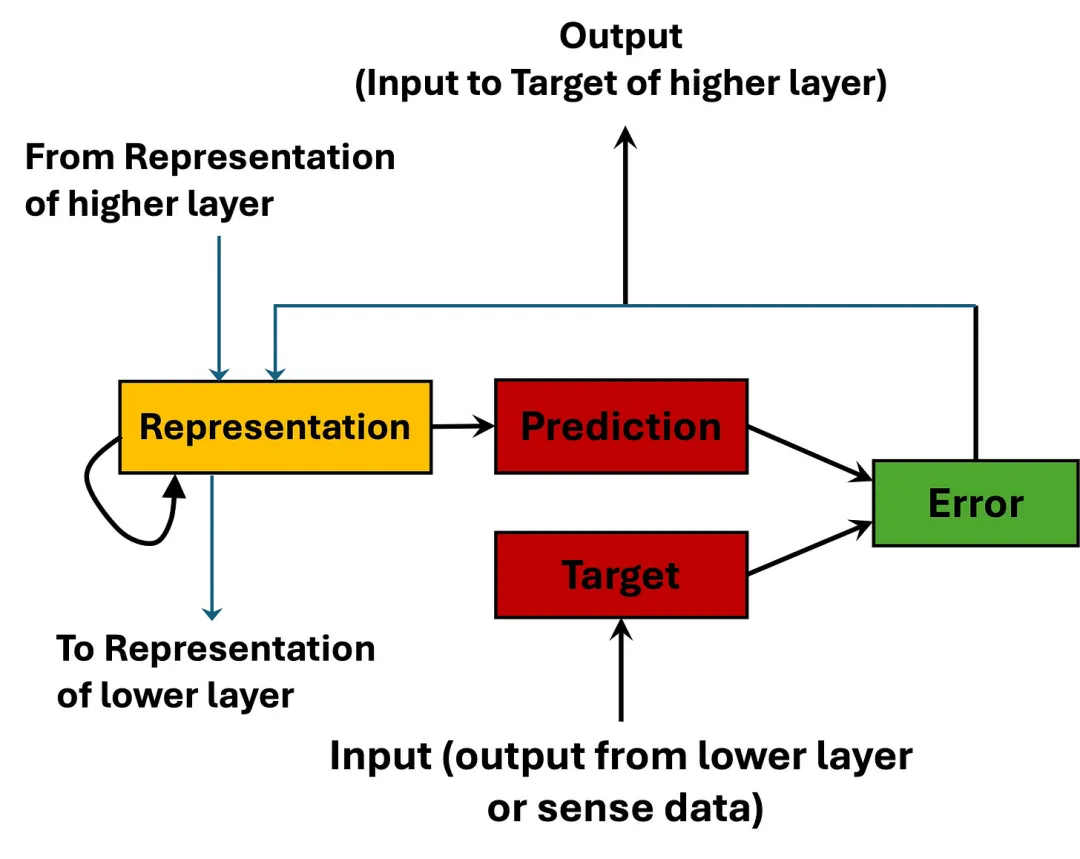
它的每一层包含四个模块:接收输入的目标层(Target)、维护序列记忆的表征层(Representation,使用循环单元)、生成预测的预测层(Prediction),以及比较预测与实际输入的误差层(Error)。预测自上而下流动,误差自下而上传播——正是预测编码的架构。整个网络通过梯度下降和时间反向传播(BPTT)端到端训练。
为了验证PredNet学到了什么,研究者用3D扫描人脸的生成模型制作了旋转人脸的合成视频。结果显示,PredNet不仅学会了预测下一帧人脸的位置,还在潜在空间中自发发现了与旋转角度、旋转速度和面部主成分分析(PCA)成分对应的变量。换句话说,
为了预测下一帧,网络被迫建立了一个关于外部世界的高层抽象模型。
研究者写道:准确预测未来的帧,至少需要一个隐含的模型,该模型描述了场景由哪些物体组成,以及这些物体被允许如何运动。
接下来是这个故事最精彩的部分。
日本研究者Watanabe、Kitaoka等人将改进版的PredNet用自然场景视频训练后,让它观看旋转螺旋桨的视频序列——网络学会了正确预测旋转方向。