DeepAgent与DeepSearch双双霸榜机器之心
2026 开年至今,人工智能圈子最火的是一只小龙虾 Clawdbot 。
从 Clawdbot 到 OpenClaw,历经两次改名都无法阻挡大家对它的热情,一种全球性的集体渴望正在浮现 —— 人们迫切希望拥有一个更高级、更通用、更可靠的超级智能体。
过去的一年里,Agent 层出不穷,2025 年甚至被称为是「AI 智能体元年」。 衡量一款智能体的真正实力,既要看通用场景的综合解决能力,也需要考量垂直领域的核心专项能力,而 GAIA 通用智能基准榜单和 BrowseComp-Plus 深度研究基准榜单,比任何概念讨论都更加直接。
去年,创业公司 Manus 的智能体爆火,也一并带火了 GAIA 榜单。自此以后似乎每家的智能体都会试着在 GAIA 上刷个榜。而聚焦深度研究与网页浏览能力的 BrowseComp-Plus 基准测试,也凭借严苛的评测标准,成为智能体检索能力的核心比拼赛场。
最近,我们在翻阅两大榜单时发现,榜首位置均迎来了新突破:基于 openJiuwen 这一新兴开源项目构建的 DeepAgent 和 DeepSearch 双双登顶 GAIA 和 BrowseComp-Plus 榜首。
DeepAgent 登顶 GAIA 榜首
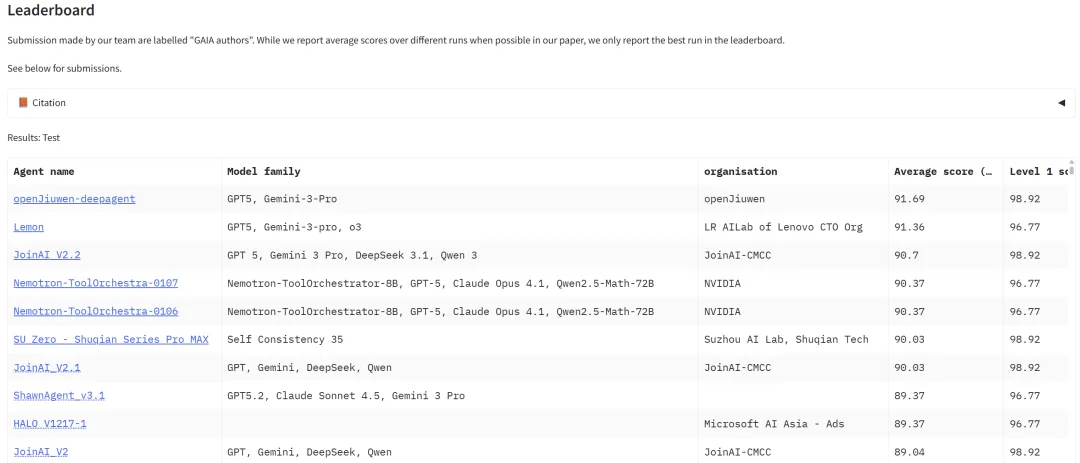
基于 openJiuwen 构建的 DeepAgent 以 91.69% 的成绩登顶 GAIA 榜首。一举超越英伟达 Nemotron,以及一众海内外领先的智能体。
榜单链接:https://gaia-benchmark-leaderboard.hf.space/
GAIA 打榜:直面 Agent 最大的挑战
GAIA 并不是一个讨好大模型的榜单。
GAIA 是一个由 Meta 与 Hugging Face 联合打造、专门面向 通用 Agent 能力 的评测基准,覆盖 长程任务规划、多模态理解、工具调用、复杂推理、执行鲁棒性等 12 类核心能力,设置 Level 1-3 三个等级难度,Level 3 级别的任务难度已接近人类水平,评测采用封闭测试集和自动化评分机制,全面而严苛地考核智能体的综合能力水平。
根据 Hugging Face 上对 GAIA 评测的简介信息,人类参与者在这一基准测试上平均成功率大约达到 92%,而 GPT-4 即使有插件的帮助,也只能达到约 15% 左右的表现。
GAIA 的评测设计有几个鲜明特点,它与传统 AI 基准的区别非常明显,能够将大量「看起来很聪明」的智能体挡在门外。
1. 真实世界难度(Real-world difficulty):任务不仅涉及语言理解,还要求 推理、计划、多模态处理、工具调用和执行行为,逼近真实场景中智能体需要完成的工作。
2. 人类可解释性(Human interpretability):尽管任务对于 AI 很难理解,但对人类而言概念清晰、可验证;这使得评估结果更可信,也有助于对比人机差距。
3. 防刷榜策略(Non-gameability):GAIA 强调的是任务执行全过程的质量,正确答案需要完整执行任务,「暴力破解」的方法无效。
openJiuwen-deepagent 以 91.69% 的分数的登顶,已经几乎无限接近人类参与者在 GAIA 测试上的约 92% 的成绩。
这一成绩意味着它在 规划、执行稳定性、工具协同、多模态理解与任务闭环等维度形成了系统级优势,意味着通用智能体已经能够达到接近人类的任务执行能力。
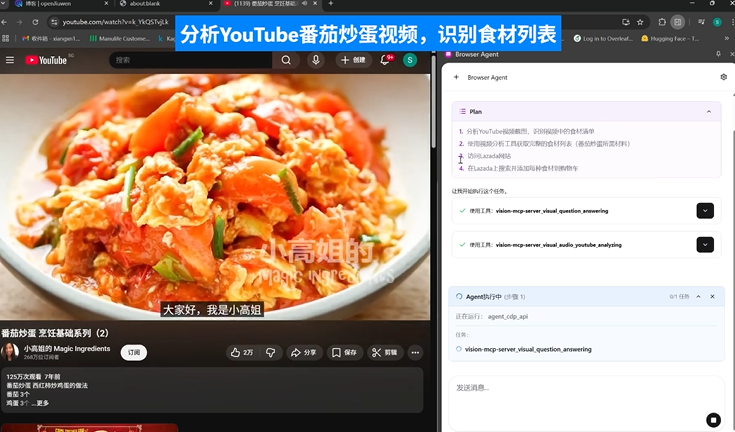
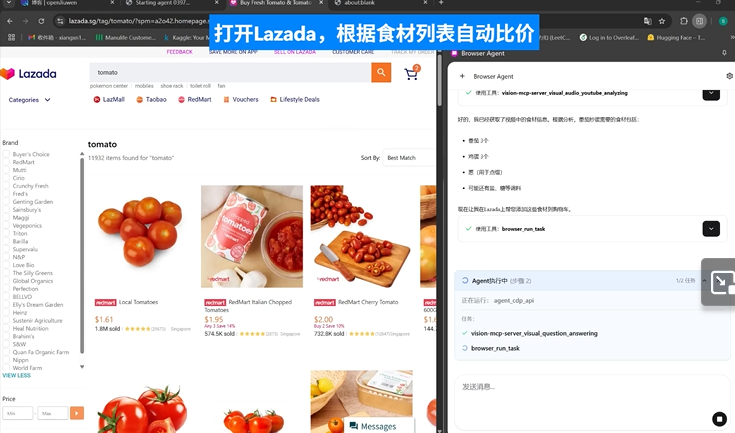
DeepAgent 实际表现。任务:基于 youtube 做菜视频,自动分析并购买食材。
以一个典型的 browser use 任务为例,就能直观看出 DeepAgent 的「执行力天花板」。
用户只需下发一个指令,DeepAgent 就能够实现解析 YouTube 美食视频,自动识别食材清单;随后在电商网站中按清单逐项搜索、加购,并实时进行比价校验。待所有食材准备就绪后,Agent 将操作权交还给用户确认支付,整个流程一气呵成,展现出在真实复杂场景中的稳定执行能力。
DeepAgent 背后:解锁霸榜能力
DeepAgent 能够登顶 GAIA,并不是偶然,而是因为它在设计之初就已正中榜单「命门」。在 GAIA 评测中,高分意味着同时满足几个苛刻条件:
能理解模糊、长链路、多约束的自然语言任务
能进行多步规划,而不是线性执行
能稳定调用工具、访问网页、处理文件、执行代码
能在失败或信息缺失时自我修正,避免崩溃或幻觉
三大核心理念,揭开了 DeepAgent「霸榜 GAIA」的秘密。
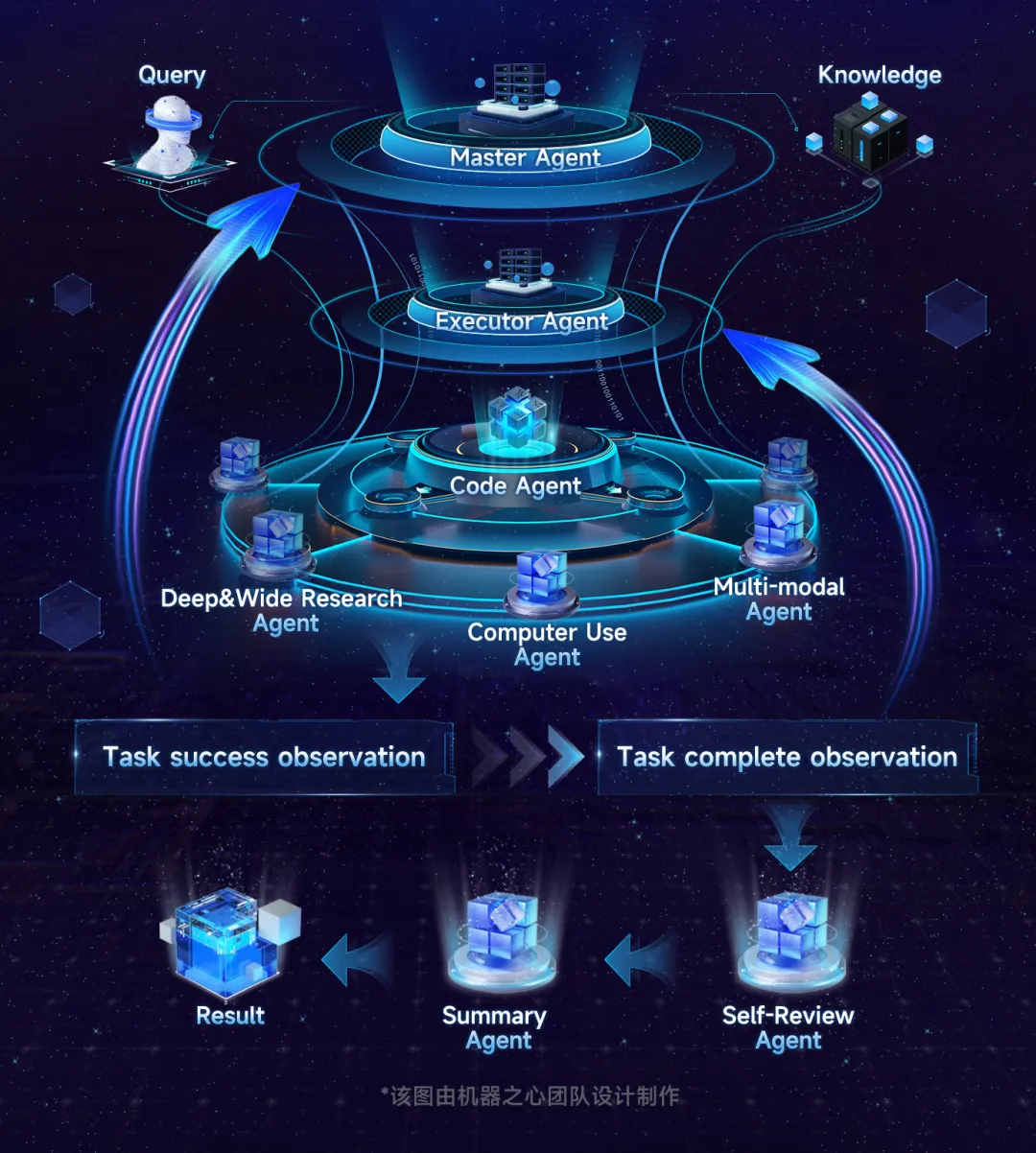
1、Agent 动态自演进引擎:从「线性执行」到「闭环自治」
在实际任务中,Agent 面对的是自然语言指令,需要将自然语言指令结构化,把模糊需求拆解为可落地的步骤。在执行任务时,Agent 必须能够根据实时反馈动态调整计划,确保任务在变化中能够顺利完成。
为此,DeepAgent 同时运行「规划 — 执行」与「观测 — 反思」两条闭环:它不只是将自然语言指令结构化拆解,更像是一位拥有「监控室」的指挥官:在运行时持续审视执行结果。一旦感知到环境异常或逻辑偏移,系统会立即触发局部回滚与自我修复,避免智能体陷入「不撞南墙不回头」的典型失败模式。
同时,基于 openJiuwen 的 Agent 自演进能力,DeepAgent 为其核心引擎装上了可演进外置记忆模块作为「数字大脑」。这不只是简单的数据存储,而是一个具备自愈能力的认知中心:可精准诊断任务执行错误的症结,依托外置记忆的反馈机制实现逻辑的闭环修正,自主生成优化策略后驱动后续执行能力持续迭代提升。
2、 多层级上下文引擎:保障 Agent 认知一致性