Claude新模型4.6来了,更多饭碗没了量子位
一睁眼,Anthropic上新模型,让Claude Opus 4.6来给您拜!年!了!
消息一出,金融数据服务商FactSet最惨盘中暴跌10%,S&P Global、穆迪、纳斯达克公司纷纷下跌,各大指数全线跳水。
这已经是Anthropic你小子本周第二次搅动市场了。
几天前,它旗下一款自动化法律工作的插件悄悄上线,直接引爆了万亿美元级别的软件股暴跌。
投资者的恐慌聚焦在一个问题:谁能保证几年内不被AI颠覆?不能就抛售。
想不到今天的Anthropic更狠。
今天以前,大家对Claude的印象,就是编程能力断档性的强。
Claude Opus 4.6冷笑一声,梆梆一拳打破这个印象:俺在更多的领域都很强!
至少就官方说法而言,财务分析、研究,以及Office三件套,Claude Opus 4.6都可以玩儿得很溜。
官网直接写到:
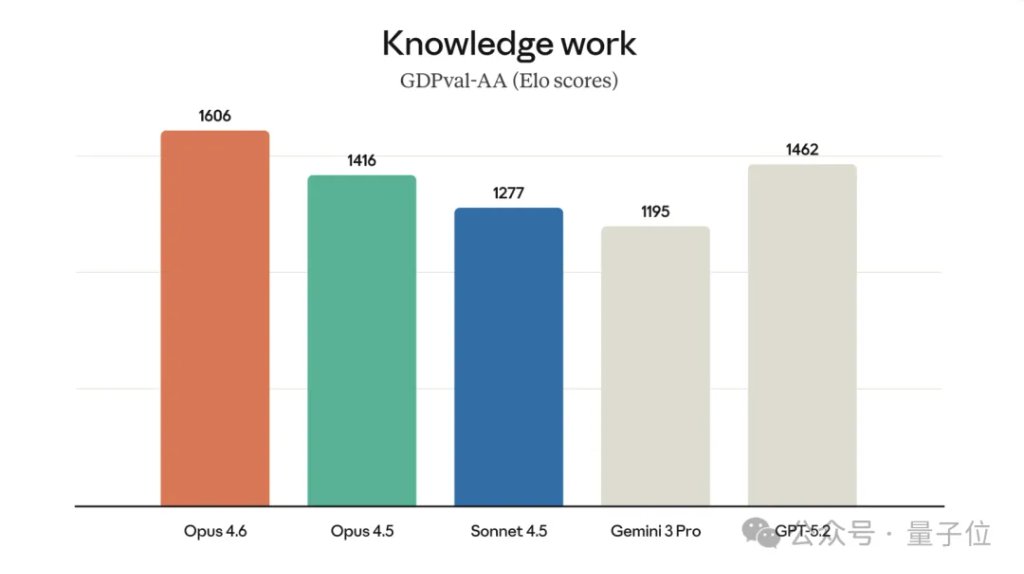
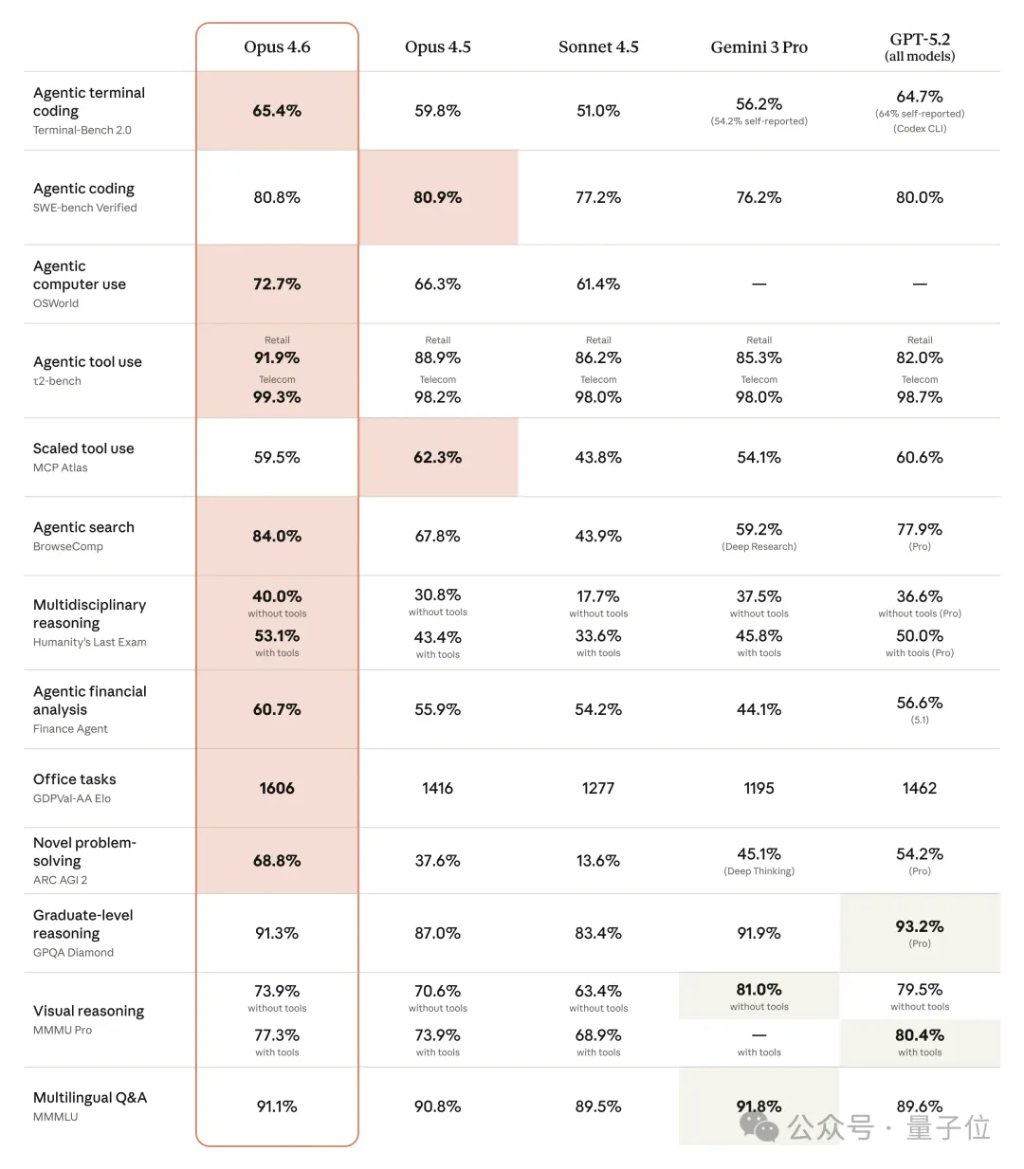
在GDPval-AA(一项评估金融、法律和其他领域经济价值知识工作任务的性能指标)上,Opus 4.6比行业下一最佳模型OpenAI GPT-5.2高出144个Elo哟~
(这意味着Claude Opus 4.6在大约70%的情况下在这个评估中获得比GPT-5.2更高的分数,50%的情况下意味着分数相当)
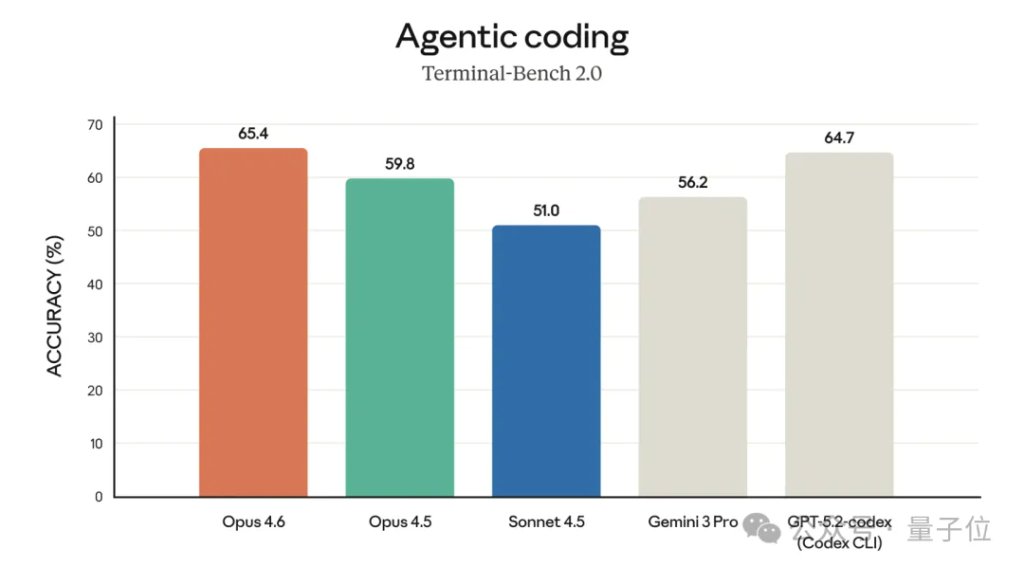
当然,编程这块它依旧独领风骚。
在Agent编程评估Terminal-Bench 2.0中取得了最高分,并在“人类最后考试”中领先所有其他前沿模型。
好消息是加量不加价,Opus 4.6的定价保持原有标准:每百万token输入/输出,价格是5美元/25美元。
(为了方便阅读,以下简称新模型为Opus 4.6)
带着 1M 上下文和自适应思考杀回巅峰
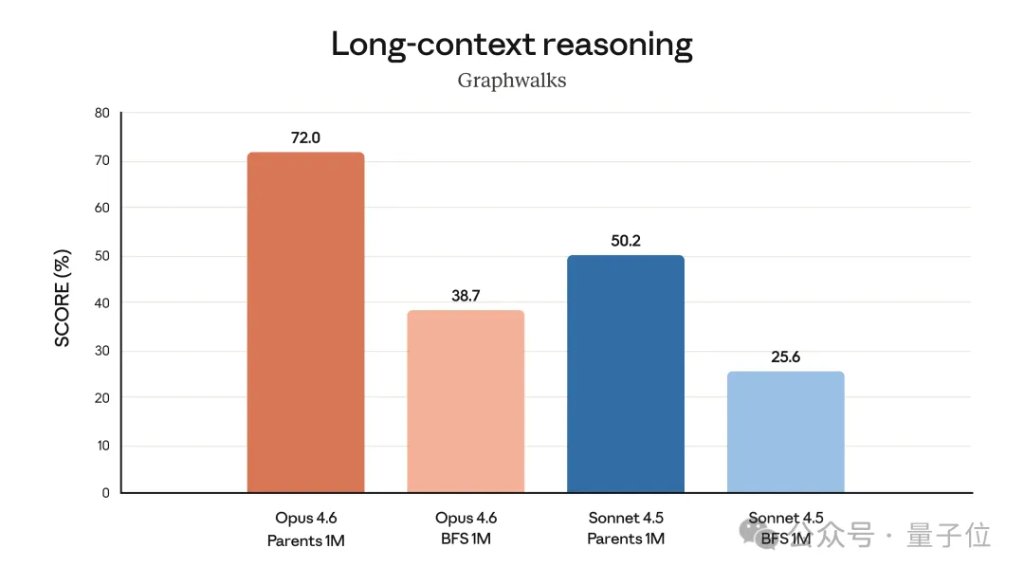
Opus 4.6最直观的进步就是有了1M Token超大上下文,这是Claude首次在Opus级别模型中引入这个长度的上下文窗口。
这极大改善了Opus 4.6在处理长文本时会出现的“上下文衰减”情况。
在MRCR v2 8-needle 1M基准测试——大海捞针——中,Opus 4.6得分76%,而Claude Sonnet 4.5只有18.5%。
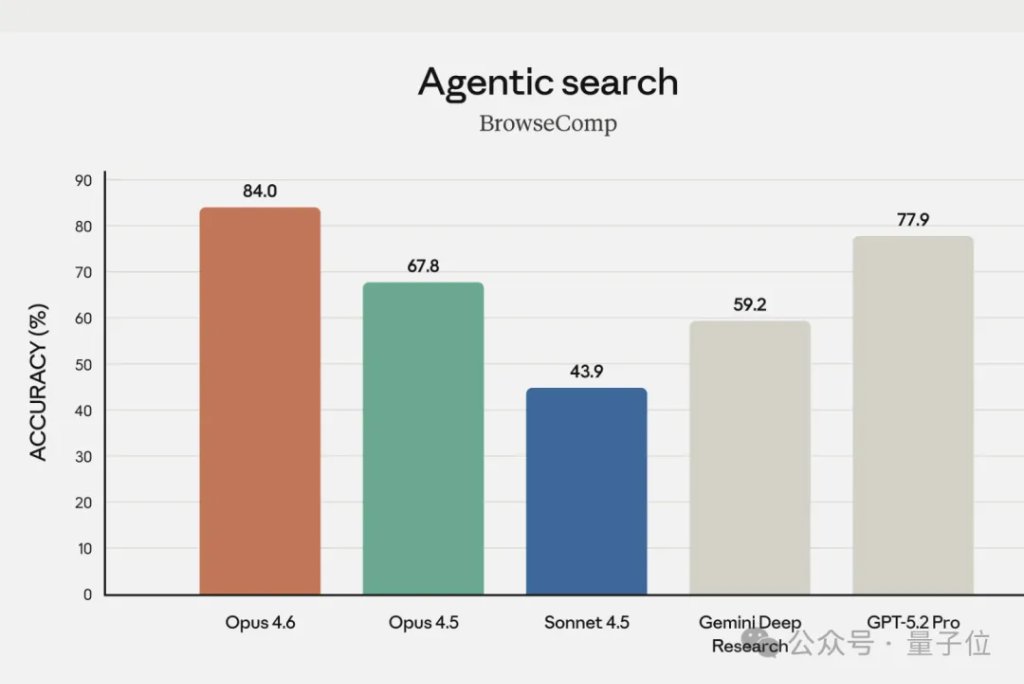
伴随而来的结果是搜索能力的提升。
在BrowseComp评测(评估在线检索难获取信息的能力)中,Opus 4.6排名行业第一,深度多步骤代理式搜索表现最佳,能精准定位分散在长文档中的关键信息。
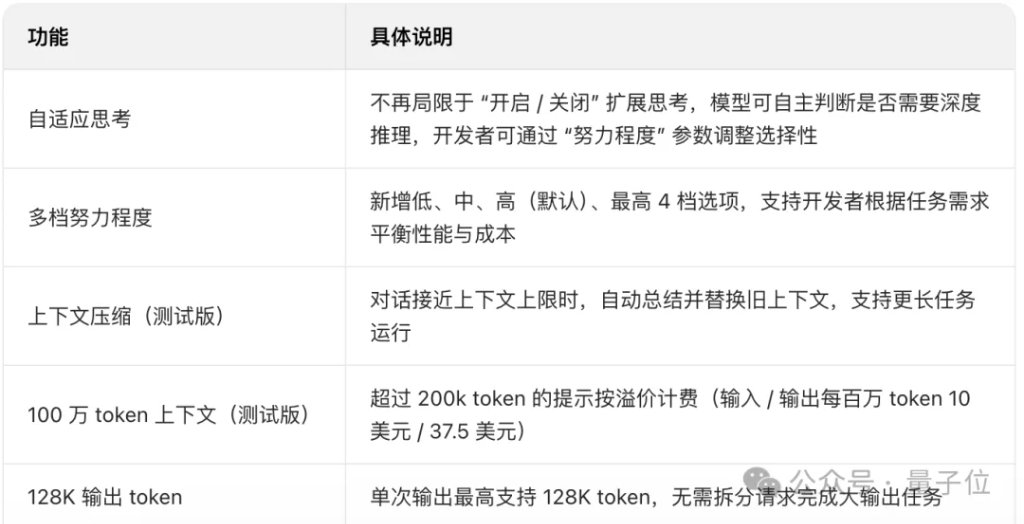
Opus 4.6还引入了自适应思考(Adaptive Thinking)功能。
以前,使用Claude模型的开发者只能二选一,扩展思考模式要么开,要么关。
现在,Claude可以自己判断什么时候需要深度推理。
(讲真,这一步比ChatGPT慢了哈,下次请搞快点上这种好功能)
配套的effort参数提供四档选择——low、medium、high、max——,默认high,遇到模型过度思考的情况可以手动调低。
另一个实用功能是上下文压缩(Context Compaction)。
当对话接近上下文窗口上限时自动摘要并替换旧内容,让长对话和Agent任务更轻松。
编码、知识工作、搜索、推理等核心场景,杀爆了
官方博客显示,Opus 4.6一出,几乎无模型能与其争锋。
在编码、知识工作、搜索、推理等核心场景,Opus 4.6有显著突破。
多项评测成绩超越前代及行业竞品,be like:
看完有了个大概印象,我们再一个一个掰开说。