马斯克还在卷10秒,中国AI直接掀桌新智元
硅谷巨头在AI视频赛道激战正酣,中国AI正面硬刚!今天,Vidu Q3震撼登场,16s音画直出一镜到底,正式开启「视听生成」时代。
2026年的AI视频圈,开局即决战!
硅谷巨头们的贴身肉搏,比想象中来得更早,也更猛烈。
几周前,谷歌Veo 3.1凭借「素材生视频」(Ingredients to Video),超强一致性+4K画质惊艳登场。
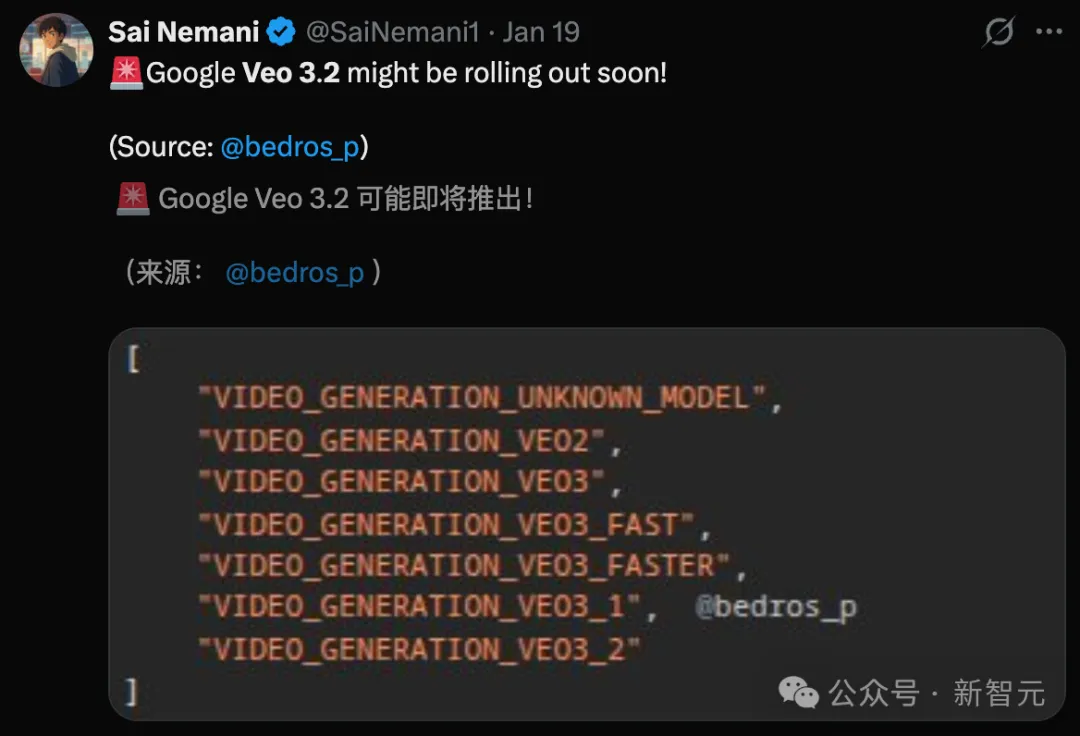
坊间传闻Veo 3.2也将蓄势待发
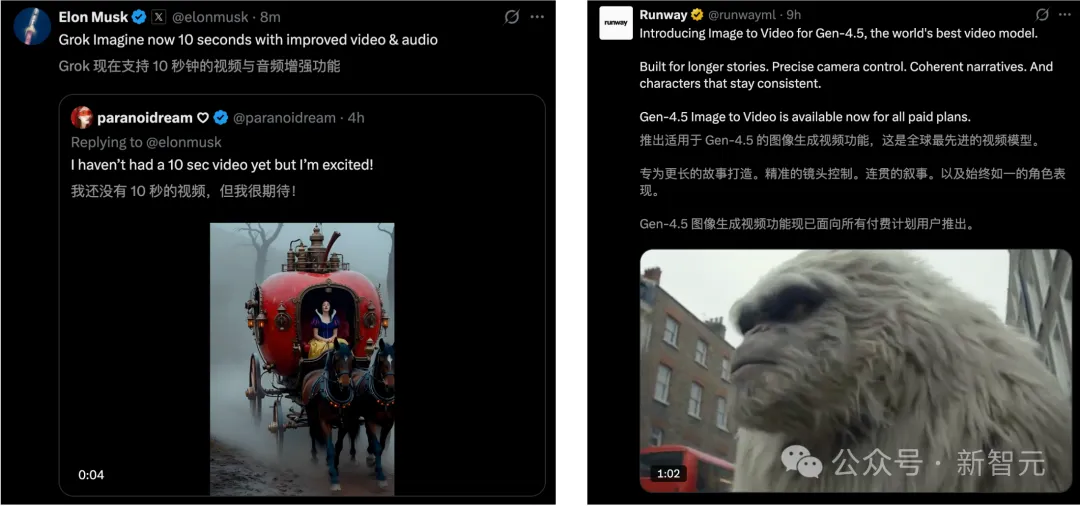
另一边,马斯克也来秀肌肉了。Grok Imagine上线生成10s视频的功能,音画双飞跃。
Runway全新Gen 4.5模型,死磕连贯叙事、高一致性,同样生成时长可达10s。
就在这硝烟弥漫的时刻,中国AI队正式加入战局,并向全球牌桌投下了一枚重磅炸弹。
下一代旗舰模型——Vidu Q3,今日重磅登场!
它带着极具野心的Slogan:「声画同出,创想无界」,直接重新改变了游戏规则。
这是全球首个一键直出16s音视频的模型,做到了一次生成,完整表达。
这意味着,在长达16秒的时长里,Q3能同时处理画面、声音、剧情推进、镜头调度,叙事能力更强。
更惊艳的是,它还支持镜头控制+自由切换、多语言文字渲染,以及专业级漫剧、短剧、电影制作。
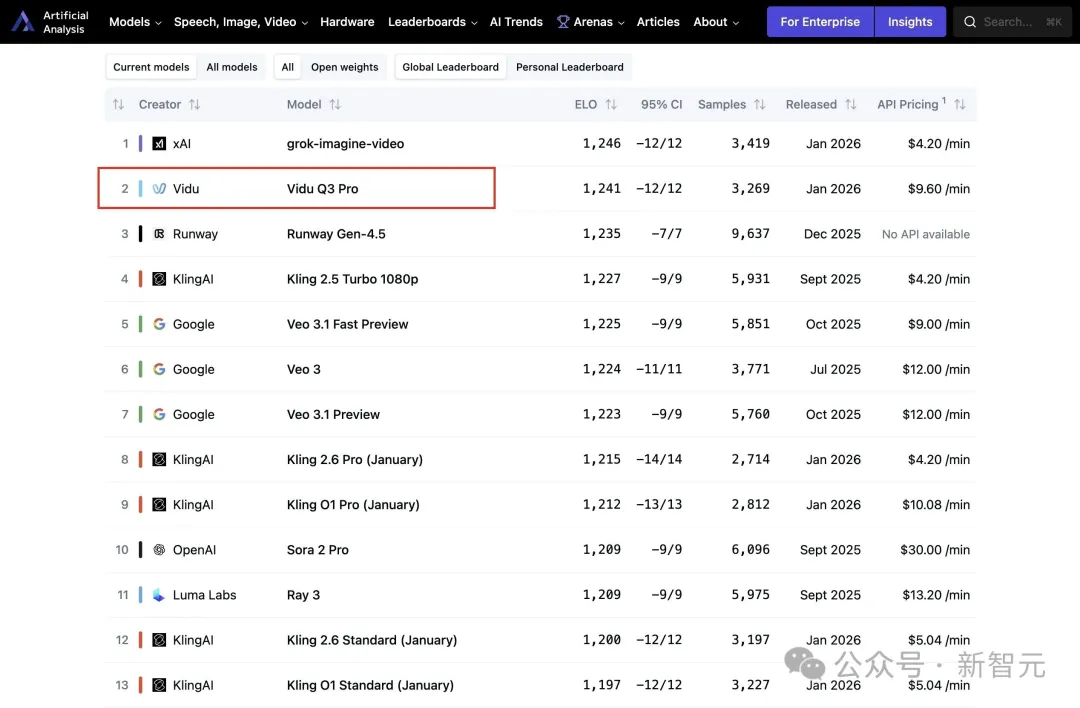
在Artificial Analysis最新榜单中,Vidu Q3表现非常亮眼,硬刚马斯克Grok,位列中国第一、全球第二。
不仅如此,它还一举超越了Runway Gen-4.5 ,谷歌Veo3.1和OpenAI Sora 2。
Vidu正在用实力向世界诠释「中国速度」,领跑视频生成的下半场。
Vidu Q3的出世,标志着AI视频正式从「演技生成」,迈入「视听生成」的新时代。
它不再为单帧画面而生,而是为「剧」而生!
Vidu Q3全球燃爆登场
16s一镜到底
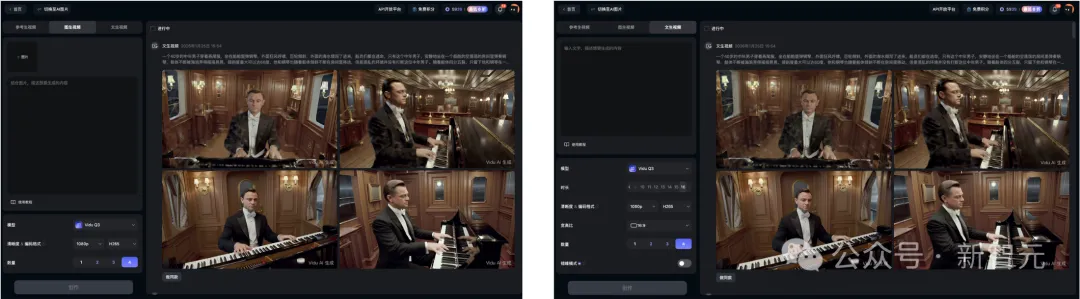
现在,Vidu Q3已上线了文生音视频、图生音视频功能。
从Vidu.cn或Vidu API:platform.vidu.cn,抢先体验Vidu Q3全新功能
接下来,就是一波最全面的实测,看看Q3究竟有多强。
一次生成,声画同步
长久以来,AI视频生成领域存在一个巨大的痛点:视频太短,且大多是「哑剧」。
几秒钟的无声画面,充其量只能算一张「会动的海报」,无法承载复杂的情绪和故事。
去年5月,谷歌Veo3的发布真正引爆了原生多模态「音画同步」,彻底终结了这一尴尬局面。
紧接着Runway Gen-3 Alpha、OpenAI Sora 2等模型迭代,也做到了音画一体。
如今,难点又落在了AI视频的时长上。目前,业界鲜有能打的生成超10秒的AI视频工具。
就拿谷歌Veo 3来说,支持最长8秒视频生成。OpenAI Sora 2还比较例外,最长15秒。
而真正做到单次生成16秒时长的,业界只有Vidu Q3了。不用拼接,不用后期合成——一气呵成,完整叙事。
这种震撼,在demo中展现得淋漓尽致。
一艘正在沉没的巨轮船舱内,海水倒灌,船体倾斜已近60度。
其他人都在逃命,唯有一名中年男子安坐在钢琴前演奏,钢琴声、海浪声交织在一起,营造出史诗般的叙事张力。
下面这个案例中,上传一张六格分镜图,让Vidu Q3按步骤生成一个制作视频。
令人惊叹的是,这种分镜效果在Q3视角下,呈现出完全不输真实大片的效果。
Vidu Q3还能轻松复刻电影的经典瞬间,甚至可以支持多种语言,包括中、英、日。
输入《哈利波特》中一张伏地魔的图片,他用低沉的声音宣告:Harry Potter is dead。人物的神态、声音高度还原,口型和音色精准匹配。
在这段中年夫妇的「对手戏」中,Vidu Q3更是交出了一份令人细思极恐的答卷。
画面呈现出经典的胶片质感,两人对视而立,对话声音平静却难掩忧伤。
Q3精准捕捉到了这种「克制的演技」,再配上精准的口型,让对话有了直击人心的真实重量。
Q3还可以来一段即兴的演奏,上传一张男子的图片,让他唱一句:Welcome to vidu Q3 model,瞬间有爵士那味儿了。