梁文锋署名:DeepSeek开源大模型记忆模块量子位
DeepSeek节前开始蓄力!
最新论文直接给Transformer加上“条件记忆”(Conditional Memory),补上了原生缺乏的知识查找机制。
结论中明写道:我们将条件记忆视为下一代稀疏模型不可或缺的建模原语。
还是梁文锋署名,并与北京大学王选所赵东岩、张辉帅团队合作。
论文中不仅提出了条件记忆这个全新范式,并给出了具体实现方案Engram模块,实验中让27B参数碾压同规模纯MoE模型,甚至变相提升了大模型的推理能力:
让原来Transformer要用6层注意力才能干的简单任务压缩到1-2层搞定,省出来的资源就可以用于更难的推理任务了。
条件记忆的原理其实也非常“原始”:不靠计算,回归查表,用上了传统N-gram方法。
给大模型一个巨大的词表,专门存那些固定的实体名称和两三个词的短语,不管词表多大,找信息都是O(1)速度。
关键就在于,如此前大模型时代的玩法,DeepSeek如何解决传统N-gram模型存储爆炸和多义性问题,又是让它和现代Transformer结合起来的?
让注意力干“苦力活”太浪费了
团队的核心观察是,语言建模其实包含两种性质完全不同的任务,一种是需要深度动态计算的组合推理,另一种则是检索静态知识。
问题在于,现有的Transformer架构缺乏原生的知识查找机制。
当模型需要识别一个实体时,它得消耗好几层注意力和前馈网络,逐层拼凑特征,最终才能完成。
论文中引用了一个具体案例:”Diana, Princess of Wales”
模型需要经过6层才能完成这个识别过程,前几层还在纠结”Wales是英国的一个地区”、”Princess of Wales是某种头衔”这些中间状态,最终才能“想起来”这是指戴安娜王妃。
本质上是在用昂贵的运行时计算来重建一个静态查找表,那些本可以用于更高层推理的网络深度,被浪费在了识别概念这种“苦力活”上。
回归查表,回归N-gram
Engram的设计思路相当直接:既然经典的N-gram模型就能用O(1)的时间复杂度捕获这些局部依赖,那为什么不把这个能力直接嵌入Transformer?
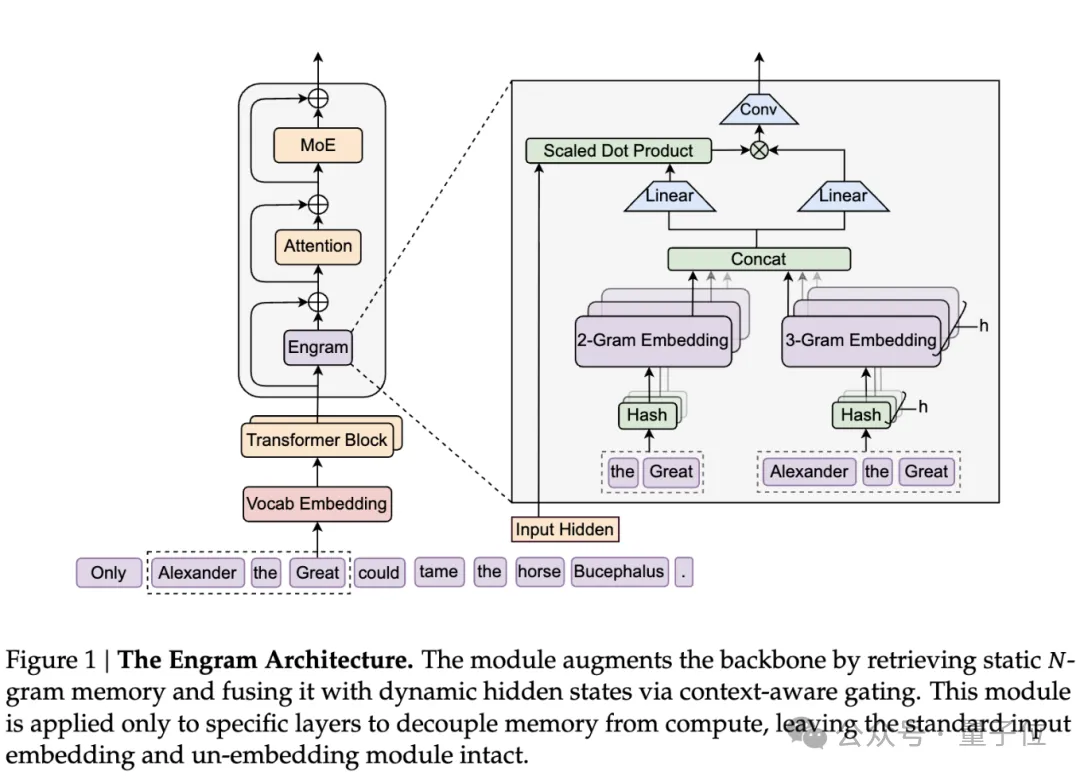
具体实现上,团队在原有的Transformer层之间插入Engram模块。每个位置的输入会触发一次哈希查找:把当前token和前面几个token组成的N-gram映射到一个巨大的嵌入表中,直接取出对应的向量。
为了处理哈希冲突和多义性问题,团队引入了上下文感知的门控机制,用当前的隐藏状态作为Query,检索到的记忆作为Key和Value,计算一个0到1之间的标量门控值。
如果检索到的内容和当前上下文不匹配,门控值就趋近于零,相当于自动屏蔽噪声。
下图中,颜色越深说明Engram越判断当前文本片段是“固定静态模式”,倾向于调用记忆库中的对应信息。
颜色越浅代表这段文本越动态灵活,主要靠模型的注意力机制处理。
比如只看到“张”是一个常见姓氏,但是“张仲景”三个字凑一起就是固定历史人物实体了。
接下来还要解决传统N-gram模型的两个痛点。
语义重复,同一个词的不同形式(比如 Apple、apple、Äpple)被当成不同 token,浪费存储。
存储爆炸,所有可能的 N-gram(比如2词、3词组合)数量太多,比如128k词表就要存128k^3种组合,直接存储根本存不下。
DeepSeek团队首先压缩tokenizer,把语义相同但形式不同的token归为一类,128k词表的有效规模直接减少23%,相同语义的token聚在一起,查找更高效。
再用多个哈希函数把N-gram映射成embedding表的索引,
这既解决了存储爆炸:不管有多少种N-gram,都通过哈希函数映射到一个固定大小的embedding表里,表的大小是质数。
又减少查找冲突:给每种N-gram阶数(比如2-gram、3-gram)配K个不同的哈希头,每个哈希头对应一个独立的embedding表,把所有N-gram阶数、所有哈希头取出来的 embedding向量拼在一起,形成最终的“记忆向量”eₜ,供后续模块使用。
U型曲线:MoE和记忆的最优配比
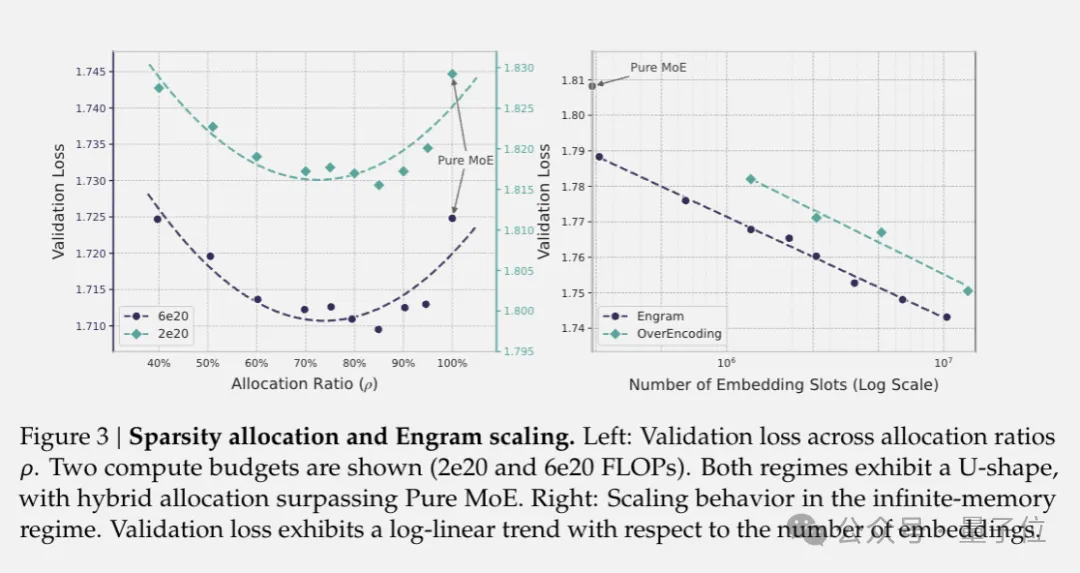
论文最核心的部分是对”稀疏性分配问题”的系统研究。
团队设计了一个严格的实验框架:固定总参数量和每token的激活参数量(也就是计算量),然后在MoE专家和Engram记忆之间重新分配”闲置参数”预算。
分配比例ρ从100%(纯MoE)逐步降到40%,实验结果画出了一条清晰的U型曲线:
纯MoE反而不是最优解,把大约20%到25%的稀疏参数预算分给Engram记忆时,模型验证集loss达到最低点。
在100亿参数规模下,最优配置比纯MoE基线的loss降低了0.0139。
更重要的是,这个最优分配点在不同计算预算下都相当稳定,大约在ρ=75%到80%之间。
团队解释了U型曲线两端的含义:
MoE主导时,模型缺乏静态模式的专用记忆,被迫通过网络深度和大量计算来低效重建。
Engram主导时,模型丢失了条件计算能力,在需要动态推理的任务上表现下降。
总之,记忆无法替代计算,计算也无法高效模拟记忆。