梁文锋署名新论文:给大模型配本“字典”华尔街日报
论文揭示,当我们将“记忆”从“计算”中剥离,把该背的交给“字典”,把该算的交给大脑,AI的推理能力将迎来反直觉的爆发式增长。这一刻,或许就是DeepSeek V4诞生的前夜。
这是一场关于AI“大脑皮层”的重构。
长期以来,Transformer架构被困在一个昂贵的悖论中:我们用着最先进的GPU算力,去让AI模型“死记硬背”那些查字典就能知道的静态知识。
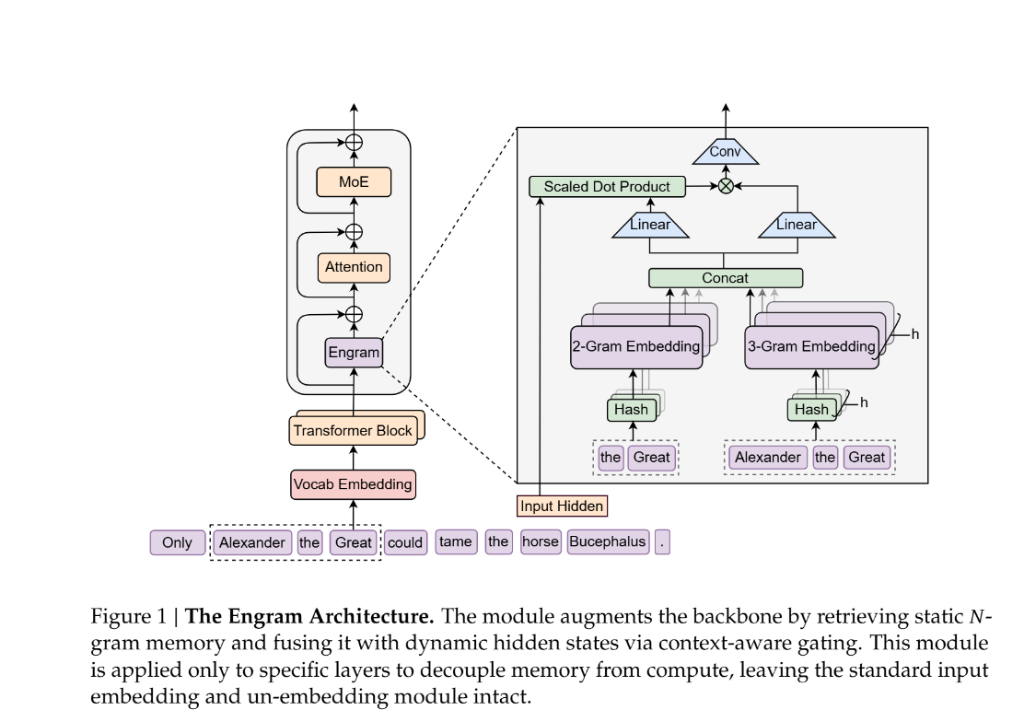
DeepSeek梁文锋团队与其北大合作者在今日凌晨发布的重磅论文《Conditional Memory via Scalable Lookup》,彻底打破了这一僵局。他们提出了一种全新的Engram(印迹)模块,在传统的“条件计算”(MoE)之外,开辟了第二条稀疏化战线——“条件记忆”。
这不只是一次技术修补,而是一场关于模型“脑容量”的供给侧改革。它证明了:当我们将“记忆”从“计算”中剥离,把该背的交给“字典”,把该算的交给大脑,AI的推理能力将迎来反直觉的爆发式增长。
DeepSeek计划在2月春节前后正式发布V4,而这一刻或许就是DeepSeek V4诞生的前夜。
六层神经网络的“无用功”
故事的起点,源于DeepSeek团队对Transformer内部运作机制的一次“核磁共振”扫描。
在人工智能的黑盒子里,当大模型看到“Diana, Princess of Wales”(戴安娜,威尔士王妃)这个短语时,它的内部发生了一场令人费解且极其昂贵的“内耗”。
研究人员发现,为了识别这个固定的实体,模型竟然动用了整整6层网络:
第1-2层:模型还在琢磨“Wales”大概是一个国家;
第3层:它意识到这是欧洲的一个地理概念;
第4层:它开始拼凑出“Princess of Wales”似乎是一个头衔;
第5层:它联想到了“威尔士亲王的妻子”;
第6层:直到这里,它才终于确认,这是指那位著名的“戴安娜王妃”。
在一位追求极致效率的架构师眼中,这简直是算力的暴殄天物。
“戴安娜王妃”是一个客观存在的、静态的实体,它不会因为上下文的变化而改变其本质。为了提取这个本来查字典就能知道的事实,Transformer竟然动用了整整6层深度的昂贵矩阵运算去“重建”这个概念。
这就像是一个绝世天才,在去解决微积分难题之前,每次都得先花半小时默写一遍九九乘法表。 这种“隐式记忆”的机制,迫使模型将宝贵的参数容量和网络深度,浪费在了简单的模式匹配上。
DeepSeek在这篇长达33页的论文中,提出了一个直击灵魂的拷问:为什么不直接给大模型配一本可以随查随用的“超级字典”?
架构重塑——Engram模块的暴力美学
为了解决这个问题,DeepSeek提出了一种名为“Engram(条件记忆)”的全新模块。
如果说MoE(混合专家模型)是把“大脑”分成了不同的区域,让不同的专家负责不同的思考(条件计算);那么Engram就是给大脑外挂了一个巨大的“海马体”,专门负责存储静态知识(条件记忆)。
1. 复活“N-gram”:从古老智慧中寻找答案
Engram的核心灵感,竟然来自于NLP(自然语言处理)领域的“上古神器”——N-gram。在深度学习统治世界之前,我们就是靠统计“N个词同时出现的概率”来理解语言的。
DeepSeek将这一经典概念进行了现代化的魔改:
传统的Transformer:知识分散在神经元的权重(Weights)里,提取知识需要经过复杂的线性层计算,复杂度高。
Engram模块:它是一个巨大的、可扩展的嵌入表(Embedding Table)。当模型读到“张仲景”或者“四大发明”这种固定搭配(N-gram)时,不需要动用大脑皮层去推理,直接通过哈希索引,在内存表中“查”出对应的向量。
这一过程的时间复杂度是O(1)——这意味着无论知识库膨胀到多大(哪怕是1000亿参数),查找速度几乎不变,且极快。
2. 三大技术护城河
既然查表这么好,为什么以前没人做?因为有三个拦路虎:存储爆炸、多义词冲突、参数分配。DeepSeek给出了教科书级的解决方案:
A. 词表压缩:极致的去重
世界上的词组组合是天文数字。DeepSeek首先做了一步“无损压缩”。在分词器(Tokenizer)层面,它将语义相同但写法不同的词进行了归一化。例如,“Apple”(首字母大写)和“apple”(小写)在语义上通常指同一个东西。通过映射归并,有效词表直接缩小了23%。这不仅节省了空间,更让知识的密度大幅提升。
B. 多头哈希:解决“哈希冲突”
不可能把所有N-gram都存下来。Engram使用了“多头哈希(Multi-Head Hashing)”技术。通过多个哈希函数,将无限的N-gram映射到有限的内存槽位中。虽然会有哈希冲突(即两个不同的词被映射到了同一个位置),但通过“多头”设计,模型可以从多个候选结果中拼凑出正确的信息,极大地提高了鲁棒性。
C. 上下文门控:给记忆配个“裁判”
这是最精妙的一笔。查表是死的,语言是活的。比如“苹果”这个词。在“吃苹果”的语境下,它指水果;在“苹果发布会”的语境下,它指科技公司。直接查表可能会引入噪声。
DeepSeek设计了一个“上下文感知门控”(Context-aware Gating)。
Query(查询):当前上下文的隐藏状态(Hidden State)。
Key/Value(键值):查表得到的静态向量。
这个门控就像一个裁判。如果查出来的“静态知识”和当前的“上下文”不搭,裁判就会把权重压低(Gate值趋向0),让模型忽略这个噪声;如果完美契合(比如“伤寒杂病论”后跟着“张仲景”),裁判就会把大门打开(Gate值趋向1),直接把知识注入模型。
黄金比例——发现AI模型的“U型曲线”
架构设计好了,接下来的问题是:怎么分家产?
假设我们显卡里的显存是有限的,总参数预算也是固定的。我们应该把多少参数分配给MoE的“专家”(负责计算),多少参数分配给Engram的“字典”(负责记忆)?
这是一个典型的资源配置博弈。DeepSeek团队进行了一场大规模的消融实验,扫描了从0%到100%的分配比例,结果画出了一条完美的“U型Scaling Law曲线”。