MIT研究,穷人福音:不用堆显卡,抄顶级模型新智元
高分模型未必懂科学,有的只是在「死记硬背」!MIT揭秘:模型越聪明,对物质的理解就越趋同。既然真理路径已清晰,我们何必再深陷昂贵的算力竞赛?
现在的AI for Science,就像一场「多国峰会」,大家用不同的语言描述同一件事。
有人让AI读SMILES字符串,有人给AI看原子的3D坐标,大在不同的赛道上比谁预测得准。
但有一个问题:这些AI是在「找规律」,还是真的理解了背后的物理真相?
在MIT的一项研究中,研究员把59个「出身」不同的模型凑在一起,观察它们在理解物质时,隐藏层表达是否相同 。
结果非常惊人:虽然这些模型看数据的方式天差地别,但只要它们变得足够强大,它们对物质的理解就会变得极度相似 。
更神奇的是,一个读文字的代码模型,竟然能和一个算受力的物理模型在「认知」上高度对齐 。
它们沿着不同的路,爬到了同一座山峰的顶端,开始共同描绘物理与现实的「终极地图」。
真理的汇合:为什么顶尖模型越长越像?
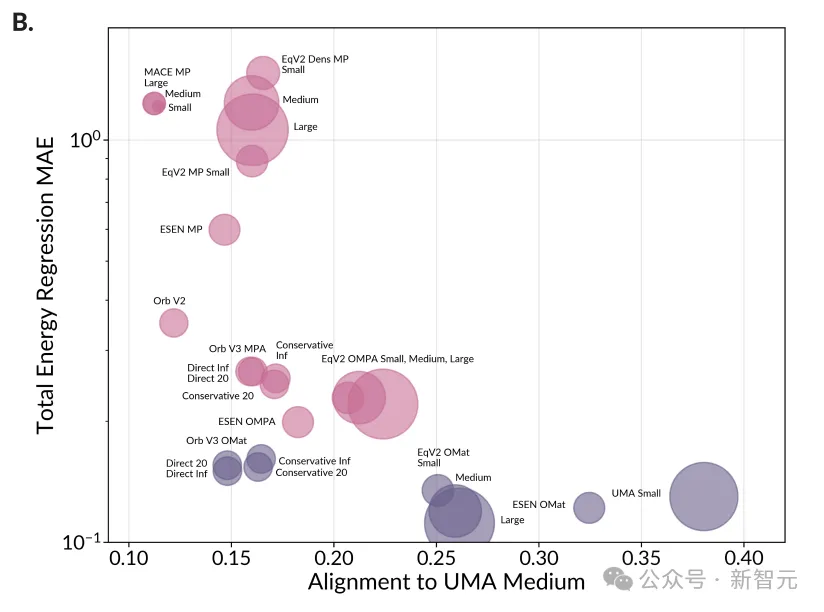
为了验证这些模型是否真的在靠近真理,研究者引入了一个关键指标:表征对齐度。
简单来说,就是看两个模型在处理同一个分子时,它们脑子里的思路有多相似。
结果发现,性能越强的模型,思维方式就越接近。
在实验中,随着模型预测物质能量准确度的提升,这些模型在表达空间里会自发地向同一个方向靠拢。
性能与认知的同步:能量预测越精准,模型与顶尖基座的思维方式就越趋同。每个点代表一个模型;点大小对应模型大小。
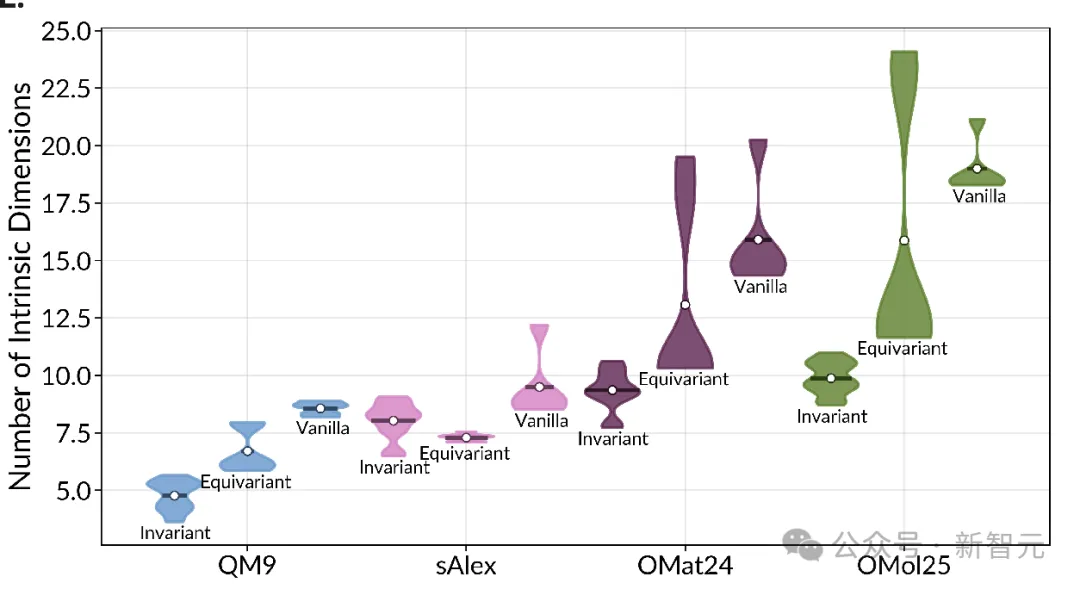
尽管这些AI的架构千差万别,但它们在处理同一批分子数据时,其特征空间的复杂度竟然压缩到了一个非常窄的范围。
无论模型外壳多么复杂,它们最后抓取的都是最核心、最精简的物理信息 。
化繁为简:虽然AI架构各异,但它们提取的物质特征在数学复杂度上却「殊途同归」。
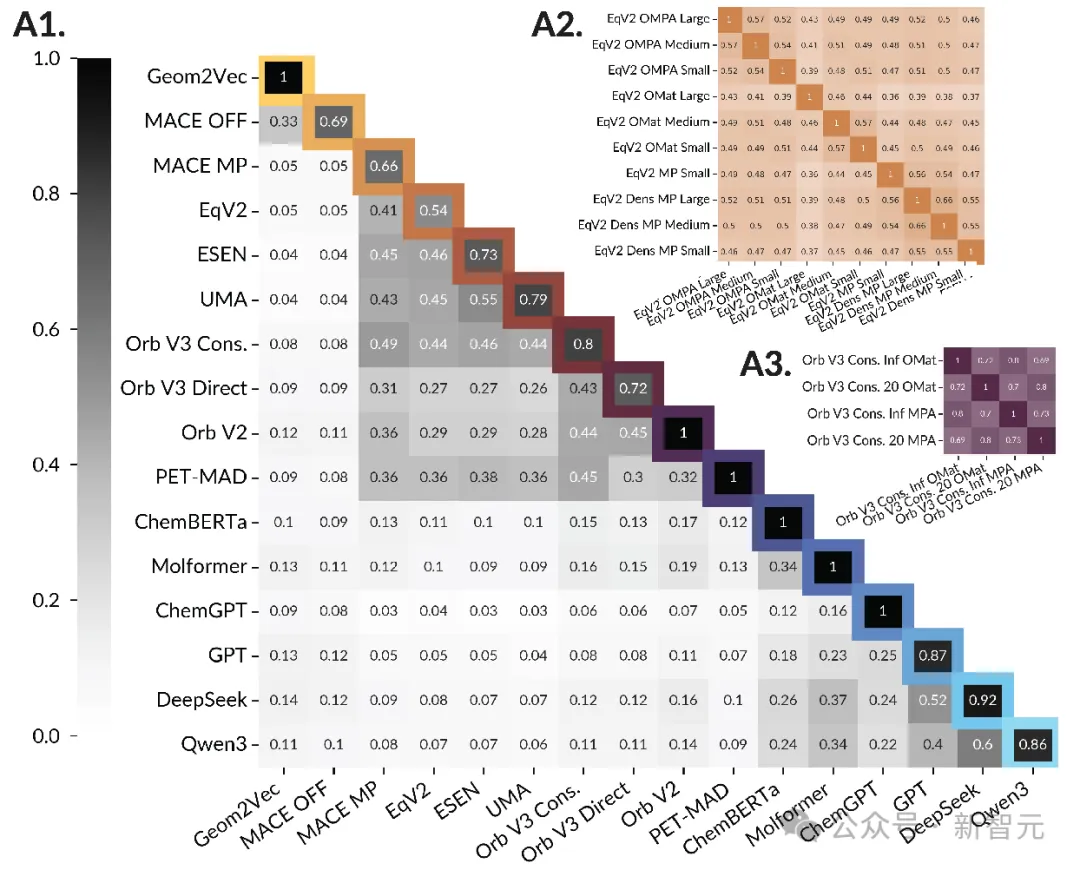
这一特征在Orb V3这样的模型上更加明显。
跨架构的表征对齐:矩阵中的深色区域显示了Orb V3等高性能模型与其它严谨物理模型(如MACE、EqV2)之间强烈的共鸣。
通过更自由的训练,它们可以更精准地对齐物理规律。