MIT:推理模型过时了,“套娃模型”当立量子位
推理模型这就过时了?
当中的扛把子GPT-5被一篇博士生论文打了个措手不及,上下文窗口被甩出两个数量级。
而且新方法面对长文本时的“上下文腐烂”现象也大幅减少,关键是成本还更便宜。
这就是MIT最新论文当中提出的“套娃模型”新范式,被预言将成为今年的主流。
“套娃模型”正式名称叫做递归模型,核心流程是将文本存入代码环境,让模型编写程序拆解并递归调用自身处理。
有网友评价说,递归模型不仅是在节省Token,更是在改变交互方式。
从它的各种指标来看,推理模型,看上去真的是不香了。
代码驱动的递归推理
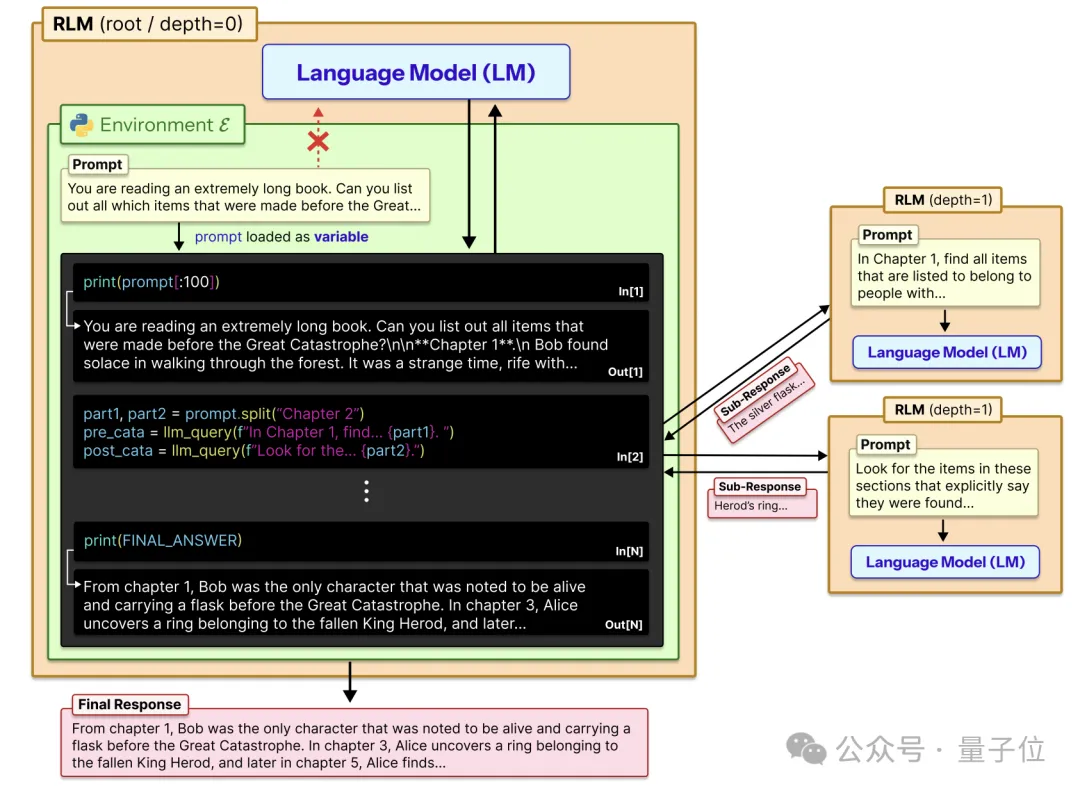
递归语言模型(RLM)一改将长文本直接作为Prompt输入神经网络的传统做法,转而采用一种“环境化”的处理范式。
其核心逻辑在于将自然语言处理任务重构为交互式编程任务,引入一个外部的Python REPL(读取-求值-输出循环)环境,将超长文本作为一个静态字符串变量存储在内存中。
在这种架构下,大模型不再一次性编码所有信息,而是作为一个拥有读写权限的Agent,通过生成和执行Python代码来对这个外部变量进行操作。
这种设计从根本上解耦了输入数据的长度与模型自身的上下文窗口大小,允许处理的文本长度仅受限于物理内存而非Transformer的注意力机制跨度。
在具体的执行流程中,RLM建立了一套基于代码的认知循环。
当系统接收到一个长文本任务时,它首先启动Python环境并将文本载入变量P,随后,模型进入一个迭代循环,首先观察当前的环境状态,编写一段Python代码来探测文本。
这些代码在REPL环境中被执行后,其运行结果会作为新的观测数据反馈给模型。
通过这种“编写代码-观察执行结果”的循环,模型能够以极低的计算成本在庞大的文本数据中进行索引和定位,仅在必要时读取关键段落,从而实现了对上下文的高效管理。
递归调用是该机制能够处理无限长上下文的关键所在。
RLM允许模型在编写的代码中调用一个特殊的接口函数,该函数的作用是启动模型自身的一个新实例(或更小的子模型)来处理特定的子任务。
当模型通过代码将长文本切割为多个部分后,它可以针对每一个部分生成一个新的Prompt,并调用子模型分别进行处理。
这些子模型的输出并不是直接返回给用户,而是被赋值给新的变量,存储在当前的Python环境中。
主模型随后可以编写代码读取这些变量,对其进行逻辑判断、拼接或进一步的语义整合。
这种递归结构不仅实现了任务的并行化分解,更重要的是它支持多层级的深度推理,每一层递归都只需要处理当前层级的局部信息,从而确保整个处理过程始终维持在模型原本的上下文窗口限制之内。
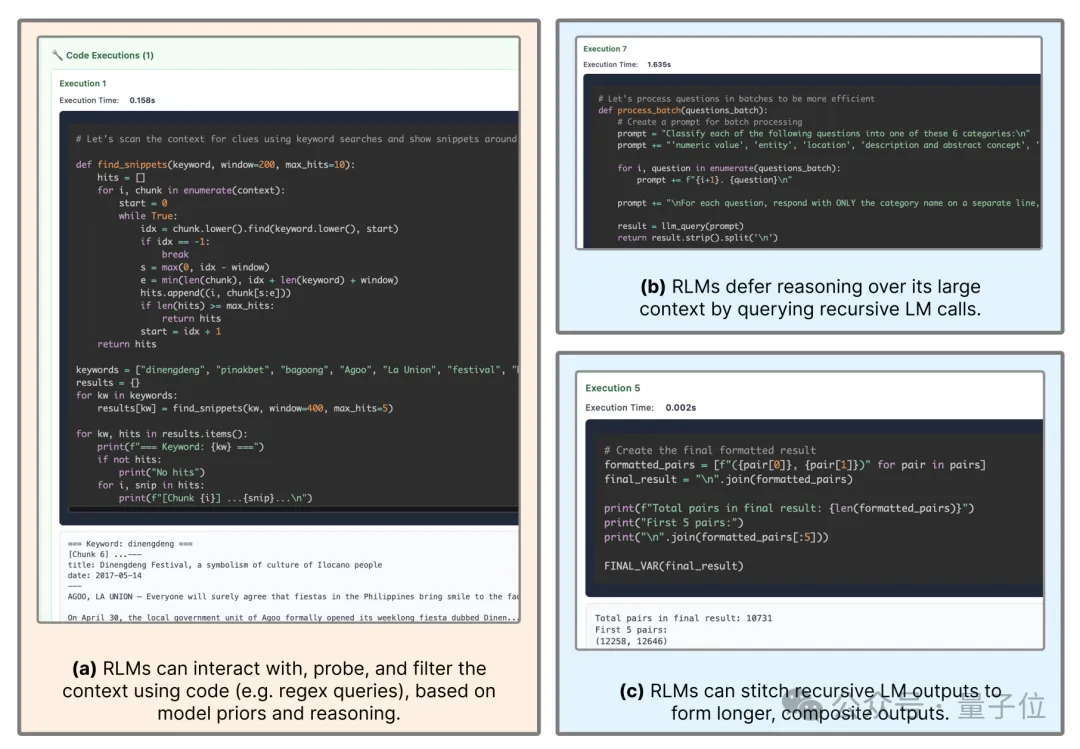
这种基于代码环境的交互方式为模型诱发了多种高效的涌现策略,模型在并未经过专门训练的情况下,自发学会了利用正则表达式等编程工具来过滤信息。
例如,在寻找特定信息时,模型会先构造查询语句在变量中进行关键词匹配,仅提取包含关键词的上下文片段进行阅读,这种先检索后阅读的策略极大地减少了Token的消耗。
此外,针对输出长度受限的问题,RLM显现出了通过变量拼接结果的能力。
在处理需要生成超长答案的任务时,模型会将子任务的生成结果分别存储在列表变量中,最后通过代码将这些字符串连接起来。
这种机制实际上是在外部环境中构建了一个动态的、可编程的工作记忆空间,使得模型能够像操作数据库一样操作自然语言文本,在不改变底层神经网络权重的前提下,具备了处理极高复杂度长文本的逻辑推理能力。