GB200:英伟达仍是王者,AMD输得彻底新智元
1/3/2026
AI推理游戏规则,正悄然改变。一份最新报告揭示了关键转折:如今决定胜负的,不再是单纯的芯片性能或GPU数量,而是 「每一美元能输出多少智能」。
AI推理,现已不只看算力硬指标了!
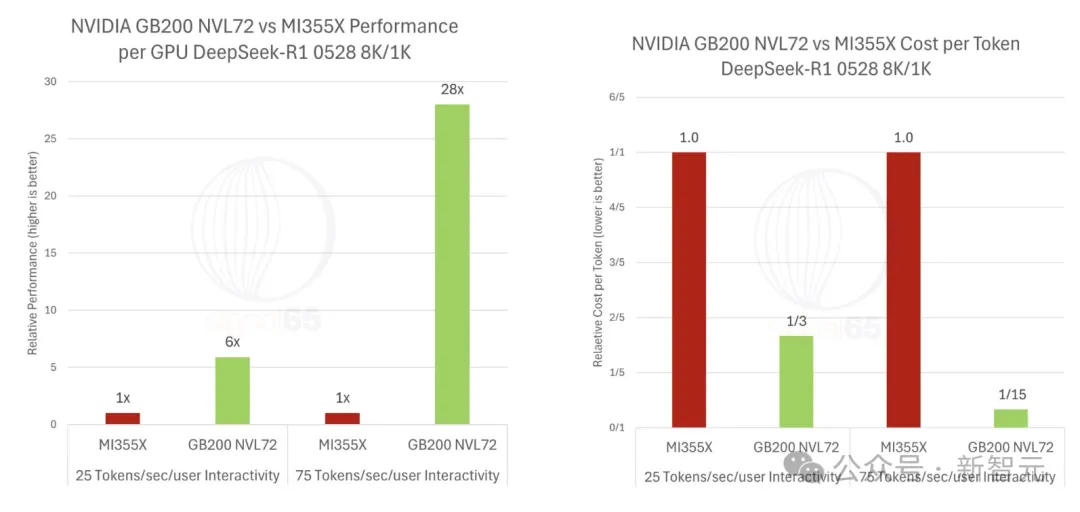
Signal65一份最新报告中,英伟达GB200 NVL72是AMD MI350X吞吐量28倍。
而且,在高交互场景在,DeepSeek R1每Token成本还能低到15倍。
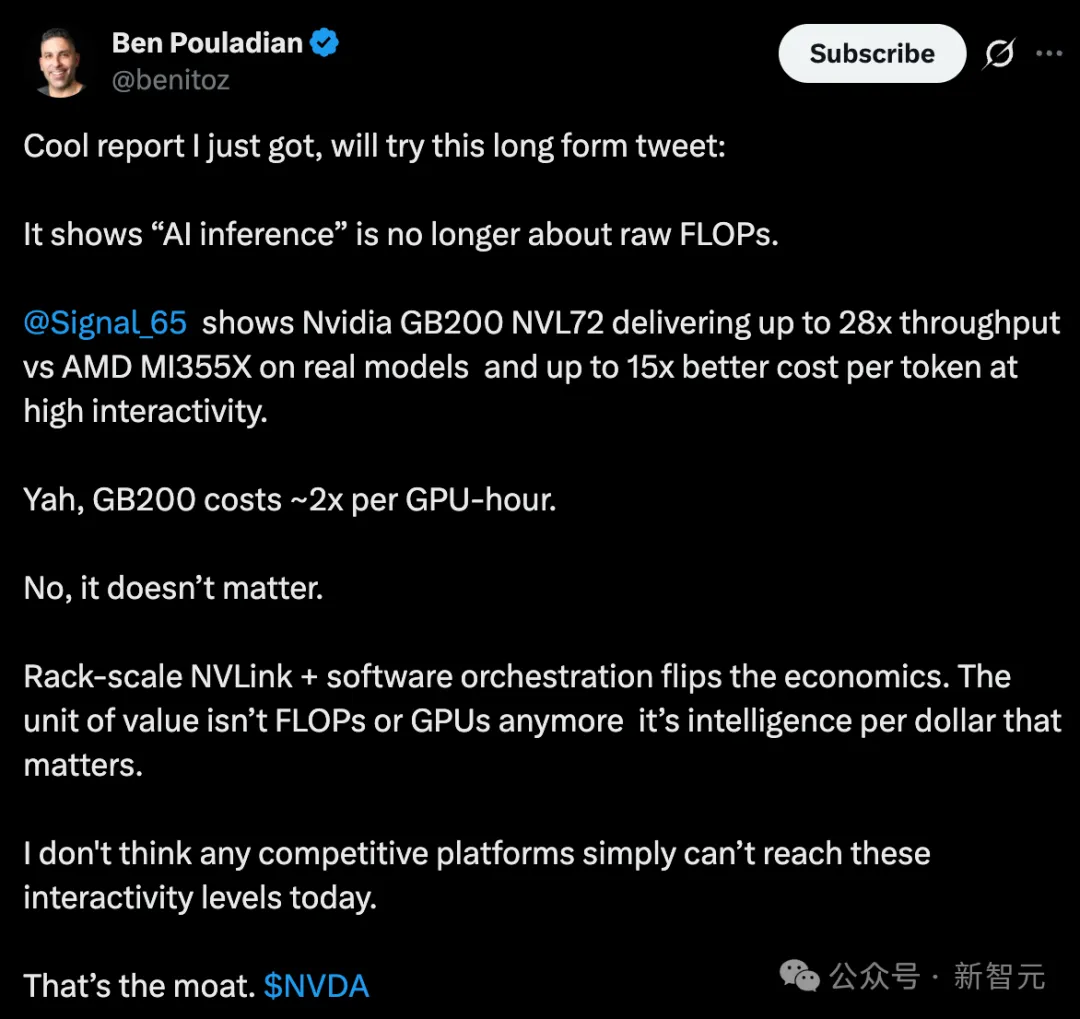
GB200每小时单价大概是贵一倍左右,但这根本不重要。因为机柜级NVLink互联+软件调度能力,彻底改变了成本结构。
顶级投资人Ben Pouladian称,「目前的关键不再是算力或GPU数量,而是每一美元能买到多少智能输出」。
如今,英伟达仍是王者。其他竞争对手根本做不到这种交互水平,这就是护城河。
最关键的是,这还没有集成200亿刀买入Groq的推理能力。
这里,再mark下老黄至理名言——The more you buy, the more you save!
AI推理重心:一美元输出多少智能?
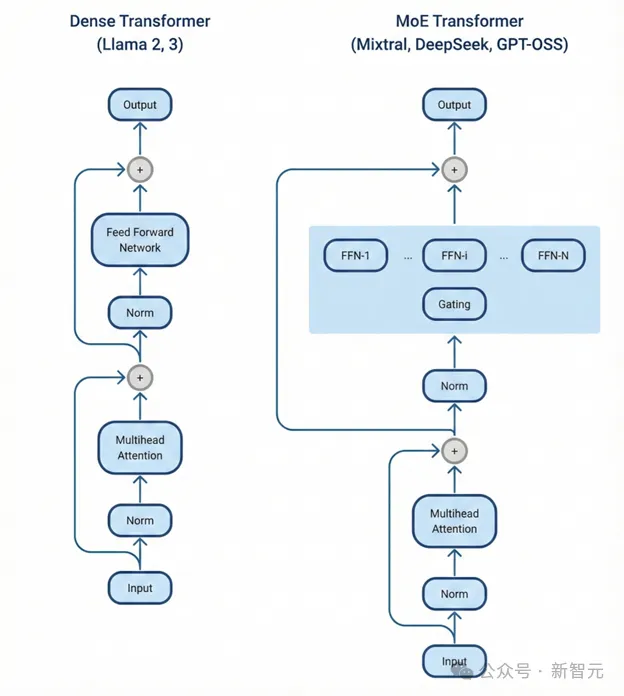
这篇万字报告,探索了从稠密模型(Dense)到混合专家模型(MoE)推理背后的一些本质现象。
传统的「稠密模型」架构要求:在生成每个Token时都激活模型里的全部参数。
这就意味着:模型越大,运行越慢、成本越高,同时还会带来相应的内存需求增长等问题。
MoE架构,正是为了释放更高水平的智能而生——在每个Token上只激活最相关的「专家」。
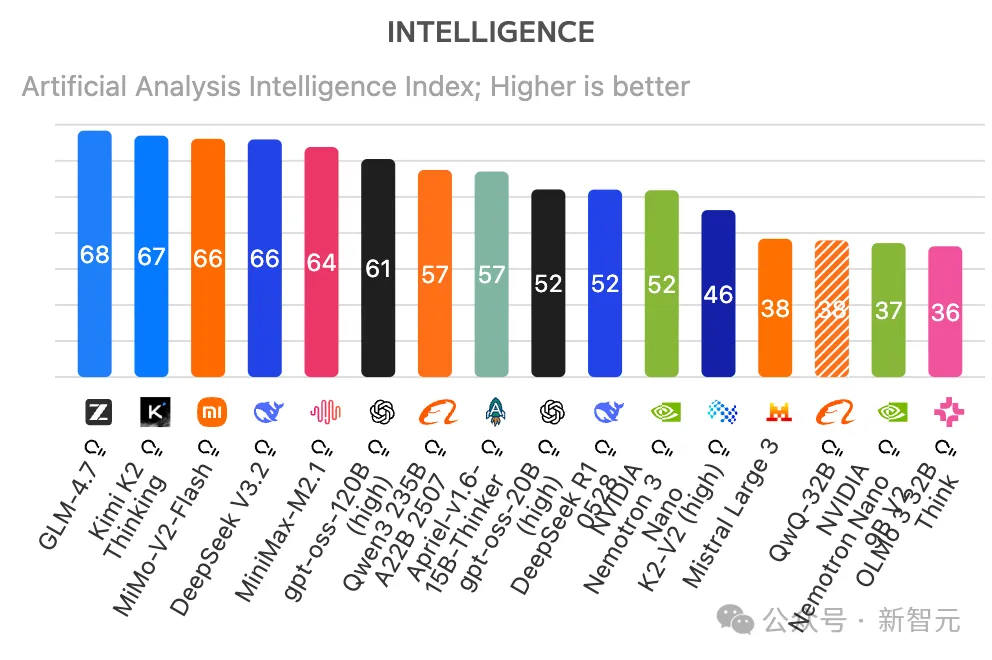
搂一眼Artificial Analysis排行榜即可发现,全球TOP 10开源LLM,全部都是MoE推理模型。
它们会在推理阶段额外「加算力」来提高准确性:
LLM不会立刻吐出答案,而是先生成中间的推理Token,再输出,相当于先把请求和解法「想一遍」。
前16名里有12个是MoE模型