KAN一作再发檄文:Scaling终将撞铁壁新智元
KAN网络作者刘子鸣新作直击痛点:Scaling Law虽然能通过「穷举」达成目标,但其本质是用无限资源换取伪智能。而真正的AGI应大道至简。
继Ilya之后,柯尔莫哥洛夫-阿诺德网络KAN一作向Scaling Law发出最新檄文!
2025年圣诞节,斯坦福大学博士后、清华大学赴任助理教授刘子鸣把矛头对准了Scaling Law。
在他看来,如今的大模型,更像是在用无限算力和数据做穷举,换来的却只是看起来聪明的假智能。
而真正的AGI应当像物理学定律一样,用最简洁的「结构」驾驭无限的世界。
刘子鸣话说很直白:
要想聪明地造出AGI,我们缺的不是规模,而是结构。
在他看来,结构主义AI并不是为了「否定」 Scaling Law。
问题在于,Scaling终究会撞上两堵墙:能源和数据。
当这两样东西耗尽时,Scaling的路,也就到头了。
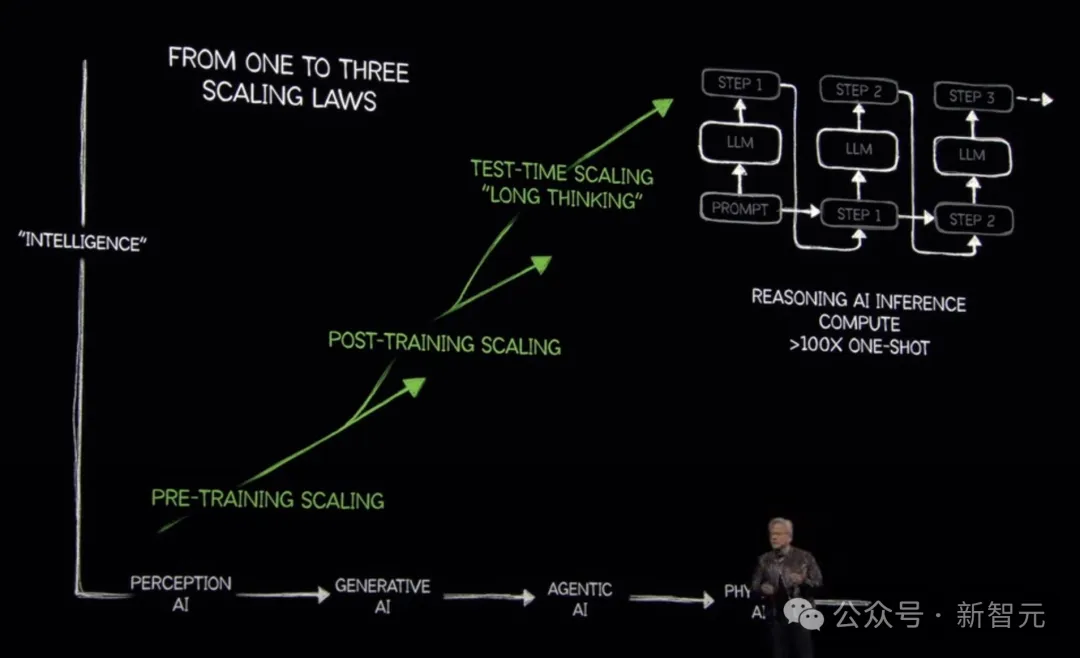
Scaling Law
用战术上的勤奋掩盖战略上的懒惰
在过去数年中,Scaling Law几乎成为AI的「黄金法则」。
它的地位,就像AI界的「元素周期表」——
一旦被发现,整个方向都被统一了。
这一经验规律揭示了模型性能与模型规模、数据量、计算量之间的幂律关系:当模型参数、训练数据和算力不断增加时,模型性能会持续提升。
然而,Scaling Law背后的逻辑却出奇简单:由于在分布外任务上,AI表现不佳,最直接的解决方案就是收集更多数据、训练更大模型,直到一切任务都变得「分布内」。
换句话说,这就是AI版的「大力出奇迹」。
因此,Scaling Law提供了一个可靠但低效的未来。
其实,刘子鸣的立场非常明确:
如果大家完全忽略能源与数据的限制,我毫不怀疑仅靠Scaling Law最终能够实现通用人工智能。
我从未怀疑过这一点。
如果算力无限、数据无穷,大模型原则上可以覆盖一切。
问题恰恰在于——现实世界并不是这样。算力有限。能源有限。高质量数据,同样有限。
于是,真正的问题浮出水面:
有没有一条更明智的路,在资源有限的前提下,走向AGI?
AGI需要「智能」而非「蛮力」
刘子鸣认为有:
答案不是更大的规模,而是更多的结构。
注意:这里是结构而非符号。他有意区分了这一点。
为什么我们需要的是结构?
因为结构能带来压缩。而压缩正是智能的核心。正如Ilya曾经说过的那样:压缩就是智能(Compression is intelligence)。
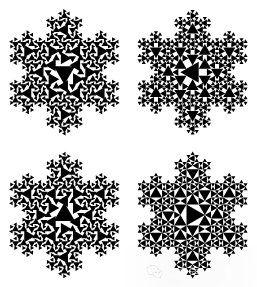
举个简单例子。
如果允许分形结构,那么雪花的内在复杂度极低——它是高度可压缩的。如果不允许结构、必须逐点描述它,那么雪花的表观复杂度几乎是无限的。
今天的Scaling Law更像后者:用越来越多的参数和计算去拟合巨大的表观复杂度。
一个更深的例子来自天体力学。
对行星运动建模最直接的方法,是把行星在每一个时刻的位置都存下来——一个成本极其高昂的查找表。
随后,发生了两次关键的「结构化压缩」:
开普勒意识到行星轨道是椭圆,从而第一次实现了真正的压缩:他找到了一个贯穿时间的全局结构,复杂度立刻大幅下降。
牛顿则发现了局部的动力学定律,实现了第二次压缩:用更少的参数解释了更多现象。
那么,现代AI大致站在什么位置?
Keyon Vafa和合作者的研究表明,Transformer并不会自然地学出牛顿式的世界模型。